/lmg/ - Local Models General
Anonymous 01/18/25(Sat)03:32:02 | 334 comments | 24 images | 🔒 Locked

/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>103928562 & >>103919239
►News
>(01/17) Nvidia AceInstruct, finetuned on Qwen2.5-Base: https://hf.co/nvidia/AceInstruct-72B
>(01/16) OuteTTS-0.3 released with voice cloning & punctuation support: https://hf.co/collections/OuteAI/outetts-03-6786b1ebc7aeb757bc17a2fa
>(01/15) InternLM3-8B-Instruct released with deep thinking capability: https://hf.co/internlm/internlm3-8b-instruct
>(01/14) MiniMax-Text-01 released with 456B-A45.9B & hybrid-lightning attention: https://hf.co/MiniMaxAI/MiniMax-Text-01
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/tldrhowtoquant
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/leaderboard.html
Code Editing: https://aider.chat/docs/leaderboards
Context Length: https://github.com/hsiehjackson/RULER
Japanese: https://hf.co/datasets/lmg-anon/vntl-leaderboard
Censorbench: https://codeberg.org/jts2323/censorbench
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
Previous threads: >>103928562 & >>103919239
►News
>(01/17) Nvidia AceInstruct, finetuned on Qwen2.5-Base: https://hf.co/nvidia/AceInstruct-72
>(01/16) OuteTTS-0.3 released with voice cloning & punctuation support: https://hf.co/collections/OuteAI/ou
>(01/15) InternLM3-8B-Instruct released with deep thinking capability: https://hf.co/internlm/internlm3-8b
>(01/14) MiniMax-Text-01 released with 456B-A45.9B & hybrid-lightning attention: https://hf.co/MiniMaxAI/MiniMax-Tex
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWeb
https://rentry.org/tldrhowtoquant
►Further Learning
https://rentry.org/machine-learning
https://rentry.org/llm-training
https://rentry.org/LocalModelsPaper
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/lea
Code Editing: https://aider.chat/docs/leaderboard
Context Length: https://github.com/hsiehjackson/RUL
Japanese: https://hf.co/datasets/lmg-anon/vnt
Censorbench: https://codeberg.org/jts2323/censor
GPUs: https://github.com/XiongjieDai/GPU-
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngl
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-M
Sampler Visualizer: https://artefact2.github.io/llm-sam
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-g
https://github.com/LostRuins/kobold
https://github.com/ggerganov/llama.
https://github.com/theroyallab/tabb
https://github.com/vllm-project/vll
Anonymous 01/18/25(Sat)03:32:15 No.103940489

►Recent Highlights from the Previous Thread: >>103928562
--Nvidia AceInstruct-72B model performance discussion:
>103932064 >103932082 >103932337 >103934588 >103934694 >103934702 >103934753 >103934787 >103934826 >103934903
--Evaluating AI language models' ability to generalize and understand natural language:
>103931457 >103931717 >103931847 >103931526 >103931594 >103931609 >103931640 >103931682 >103931706 >103931758
--Llama training data and potential future of AI model transparency:
>103934060 >103934432 >103934643 >103934686 >103935115 >103935232
--Why imagegen models follow style better than textgen models:
>103938440 >103938590 >103938608 >103938651 >103938665 >103938552 >103938697 >103938938 >103939076 >103939126
--AI app entrepreneur renting A100s, discussion on advantages and challenges:
>103930913 >103931004 >103931025 >103930949 >103931218
--Anon complains about llama-cli's lack of terminal shortcuts:
>103931561 >103931852 >103935617 >103931953 >103935959 >103936369 >103936539
--Anon gets help with creating AI voice readings for audiobooks:
>103934213 >103934348
--DeepSeek-R1 model weights and potential challenges:
>103935377 >103935585 >103935768 >103935786 >103935909 >103935941 >103935972
--Anon's struggles with updating AI software:
>103928889 >103929003 >103929196 >103929601 >103929820 >103929900 >103929949 >103929992 >103930009 >103930129
--NVIDIA RTX 50 series rumored to have limited quantities and restrictions:
>103932295 >103932348 >103932585 >103932521 >103932685 >103932758
--Yuval Noah Harari's comments on AI and the Bible:
>103930064 >103930504 >103930549
--Anon showcases SBC setup, discussion of SBC model capabilities:
>103929681 >103932665 >103937155
--Green Thing & Miku (free space):
>103928619 >103928694 >103934578 >103934735 >103937155 >103937756 >103937775 >103938055 >103938112 >103938161 >103938440
►Recent Highlight Posts from the Previous Thread: >>103928565
Why?: 9 reply limit >>102478518
Fix: https://rentry.org/lmg-recap-script
--Nvidia AceInstruct-72B model performance discussion:
>103932064 >103932082 >103932337 >103934588 >103934694 >103934702 >103934753 >103934787 >103934826 >103934903
--Evaluating AI language models' ability to generalize and understand natural language:
>103931457 >103931717 >103931847 >103931526 >103931594 >103931609 >103931640 >103931682 >103931706 >103931758
--Llama training data and potential future of AI model transparency:
>103934060 >103934432 >103934643 >103934686 >103935115 >103935232
--Why imagegen models follow style better than textgen models:
>103938440 >103938590 >103938608 >103938651 >103938665 >103938552 >103938697 >103938938 >103939076 >103939126
--AI app entrepreneur renting A100s, discussion on advantages and challenges:
>103930913 >103931004 >103931025 >103930949 >103931218
--Anon complains about llama-cli's lack of terminal shortcuts:
>103931561 >103931852 >103935617 >103931953 >103935959 >103936369 >103936539
--Anon gets help with creating AI voice readings for audiobooks:
>103934213 >103934348
--DeepSeek-R1 model weights and potential challenges:
>103935377 >103935585 >103935768 >103935786 >103935909 >103935941 >103935972
--Anon's struggles with updating AI software:
>103928889 >103929003 >103929196 >103929601 >103929820 >103929900 >103929949 >103929992 >103930009 >103930129
--NVIDIA RTX 50 series rumored to have limited quantities and restrictions:
>103932295 >103932348 >103932585 >103932521 >103932685 >103932758
--Yuval Noah Harari's comments on AI and the Bible:
>103930064 >103930504 >103930549
--Anon showcases SBC setup, discussion of SBC model capabilities:
>103929681 >103932665 >103937155
--Green Thing & Miku (free space):
>103928619 >103928694 >103934578 >103934735 >103937155 >103937756 >103937775 >103938055 >103938112 >103938161 >103938440
►Recent Highlight Posts from the Previous Thread: >>103928565
Why?: 9 reply limit >>102478518
Fix: https://rentry.org/lmg-recap-script
Anonymous 01/18/25(Sat)03:46:39 No.103940567

So I was cleaning up my Downloads folder, I wanted to delete a folder named tex_override which contained texture files for a mod I no longer need. And next to it was text-generation-webui-main. Care to guess which one I shift+del'd?
My models were backed up to an external drive but my conversations are gone. (File recovery was not very helpful.)
I am back to square one. Though I want to interpret it as an opportunity to try something else. Previously I used ooba, I want to try something else now, what interfaces are most up to date?
Also, some threads ago there was a mass replier telling everyone to use llama.cpp directly. Is he a schizo or is there merit to this? Though isn't it tedious to manually pass arguments about samplers and the like each time?
My models were backed up to an external drive but my conversations are gone. (File recovery was not very helpful.)
I am back to square one. Though I want to interpret it as an opportunity to try something else. Previously I used ooba, I want to try something else now, what interfaces are most up to date?
Also, some threads ago there was a mass replier telling everyone to use llama.cpp directly. Is he a schizo or is there merit to this? Though isn't it tedious to manually pass arguments about samplers and the like each time?
Anonymous 01/18/25(Sat)03:53:22 No.103940621
>>103940567
The fastest to setup is kobold. It's literally just a download and you're ready to go, so try that one.
The fastest to setup is kobold. It's literally just a download and you're ready to go, so try that one.
Anonymous 01/18/25(Sat)03:56:32 No.103940637
>>103940621
I used kobold once or twice before. How up to date it is generally though? I don't want to miss support for newest models and other potential issues.
I am fine with venv and pip install -r requirements.txt.
I used kobold once or twice before. How up to date it is generally though? I don't want to miss support for newest models and other potential issues.
I am fine with venv and pip install -r requirements.txt.
Anonymous 01/18/25(Sat)04:00:50 No.103940655
>>103940637
Looks like it just had an update half an hour ago. https://github.com/LostRuins/koboldcpp/releases
For my needs it's perfectly fine with keeping up.
Looks like it just had an update half an hour ago. https://github.com/LostRuins/kobold
For my needs it's perfectly fine with keeping up.
Anonymous 01/18/25(Sat)04:00:51 No.103940656
>>103940637
generally updates every 2 weeks
generally updates every 2 weeks
Anonymous 01/18/25(Sat)04:03:00 No.103940665
Why is the field so boring right now?
Anonymous 01/18/25(Sat)04:05:58 No.103940678
https://arxiv.org/abs/2412.04318
>This paper introduces the counter-intuitive generalization results of overfitting pre-trained large language models (LLMs) on very small datasets. In the setting of open-ended text generation, it is well-documented that LLMs tend to generate repetitive and dull sequences, a phenomenon that is especially apparent when generating using greedy decoding. This issue persists even with state-of-the-art LLMs containing billions of parameters, trained via next-token prediction on large datasets. We find that by further fine-tuning these models to achieve a near-zero training loss on a small set of samples -- a process we refer to as hyperfitting -- the long-sequence generative capabilities are greatly enhanced. Greedy decoding with these Hyperfitted models even outperform Top-P sampling over long-sequences, both in terms of diversity and human preferences. This phenomenon extends to LLMs of various sizes, different domains, and even autoregressive image generation. We further find this phenomena to be distinctly different from that of Grokking and double descent. Surprisingly, our experiments indicate that hyperfitted models rarely fall into repeating sequences they were trained on, and even explicitly blocking these sequences results in high-quality output. All hyperfitted models produce extremely low-entropy predictions, often allocating nearly all probability to a single token.
>This paper introduces the counter-intuitive generalization results of overfitting pre-trained large language models (LLMs) on very small datasets. In the setting of open-ended text generation, it is well-documented that LLMs tend to generate repetitive and dull sequences, a phenomenon that is especially apparent when generating using greedy decoding. This issue persists even with state-of-the-art LLMs containing billions of parameters, trained via next-token prediction on large datasets. We find that by further fine-tuning these models to achieve a near-zero training loss on a small set of samples -- a process we refer to as hyperfitting -- the long-sequence generative capabilities are greatly enhanced. Greedy decoding with these Hyperfitted models even outperform Top-P sampling over long-sequences, both in terms of diversity and human preferences. This phenomenon extends to LLMs of various sizes, different domains, and even autoregressive image generation. We further find this phenomena to be distinctly different from that of Grokking and double descent. Surprisingly, our experiments indicate that hyperfitted models rarely fall into repeating sequences they were trained on, and even explicitly blocking these sequences results in high-quality output. All hyperfitted models produce extremely low-entropy predictions, often allocating nearly all probability to a single token.
Anonymous 01/18/25(Sat)04:06:32 No.103940680
How is nemo STILL the best model???
it's over
it's over
Anonymous 01/18/25(Sat)04:14:08 No.103940717
>>103940489
Thanks, Recap Gumi.
Thanks, Recap Gumi.
Anonymous 01/18/25(Sat)04:19:54 No.103940742
![Llamado de Emergencia | VOCALOID cover | Hatsune Miku, Gumi [94QK7TYBams].mkv_snapshot_00.00.300](https://i.4cdn.org/g/1737191994505265s.jpg)
>>103940489
omg it goomy
omg it goomy
Anonymous 01/18/25(Sat)04:21:22 No.103940751
remember when it looked like things would speed up once zuck had his 150k h100 cluster online and could shit out new llama versions in two weeks of training?
Anonymous 01/18/25(Sat)04:23:13 No.103940763
>>103940655
>>103940656
Alright downloaded it.
Will test more in the evening.
Hopefully it doesn't make me miss ooba.(Must be awful to do that.)
>>103940656
Alright downloaded it.
Will test more in the evening.
Hopefully it doesn't make me miss ooba.(Must be awful to do that.)
Anonymous 01/18/25(Sat)04:23:28 No.103940765
>>103940751
even without the lawsuits, we knew we would never get anything more than llama 2 with progressively more tokens
even without the lawsuits, we knew we would never get anything more than llama 2 with progressively more tokens
Anonymous 01/18/25(Sat)04:24:37 No.103940771
>>103940765
retnet llama any day now
retnet llama any day now
Anonymous 01/18/25(Sat)04:27:59 No.103940792
>>103934903
Do you have this problem with Kunou that it just randomly stops talking in the middle of the message, like
>"Not only that,"
And after that there's an end token. If I continue a bunch of times I finally can get a gen to continue with something like
>she said, ...
But the token probability windows sows that im_end is the most likely token there.
Apart from those weird interruptions Kunou us great.
Do you have this problem with Kunou that it just randomly stops talking in the middle of the message, like
>"Not only that,"
And after that there's an end token. If I continue a bunch of times I finally can get a gen to continue with something like
>she said, ...
But the token probability windows sows that im_end is the most likely token there.
Apart from those weird interruptions Kunou us great.
Anonymous 01/18/25(Sat)04:31:16 No.103940816
What is ace instruct? Nothingburger?
Anonymous 01/18/25(Sat)04:33:06 No.103940828

Will my logs ever look like this
Anonymous 01/18/25(Sat)04:33:07 No.103940829
>>103940816
Nvidia Qwen tune. Maybe the Nemotron of Qwen, maybe nothing at all. I don't think anyone cares enough to try it.
Nvidia Qwen tune. Maybe the Nemotron of Qwen, maybe nothing at all. I don't think anyone cares enough to try it.
Anonymous 01/18/25(Sat)04:34:38 No.103940833
>>103940829
I've noticed this a lot lately. Both here and in /sdg/
>new thing comes out
>nobody can be assed to even try it
>zero drive to explore and try new things.
I've noticed this a lot lately. Both here and in /sdg/
>new thing comes out
>nobody can be assed to even try it
>zero drive to explore and try new things.
Anonymous 01/18/25(Sat)04:35:31 No.103940838
>>103940829
I care. When someone makes a 4bit exl2.
I care. When someone makes a 4bit exl2.
Anonymous 01/18/25(Sat)04:37:03 No.103940849
>>103940833
Not surprising if it's based on qwen.
Not surprising if it's based on qwen.
Anonymous 01/18/25(Sat)04:38:20 No.103940860
>>103940828
Doesn't even rhyme...
Doesn't even rhyme...
Anonymous 01/18/25(Sat)04:41:52 No.103940880
Anonymous 01/18/25(Sat)04:44:51 No.103940899
>>103940833
It's a lot of time spent downloading, setting up and testing for more of the same at best but more often retarded unusable models
It's a lot of time spent downloading, setting up and testing for more of the same at best but more often retarded unusable models
Anonymous 01/18/25(Sat)04:46:37 No.103940914
>>103940880
This is the only thing I care about at the moment. Too bad is probably going to take a long time before we see any model using it.
This is the only thing I care about at the moment. Too bad is probably going to take a long time before we see any model using it.
Anonymous 01/18/25(Sat)04:49:06 No.103940928
>>103940678
This only works to an extent, with lots of caveats. Are you willing to use RP models with near-deterministic outputs?
This only works to an extent, with lots of caveats. Are you willing to use RP models with near-deterministic outputs?
Anonymous 01/18/25(Sat)04:52:37 No.103940943
Wayfarer
Anonymous 01/18/25(Sat)04:54:20 No.103940953
>>103940665
My guess is that AI companies are waiting for Trump's inauguration before releasing anything. So, next week we may start to see something.
My guess is that AI companies are waiting for Trump's inauguration before releasing anything. So, next week we may start to see something.
Anonymous 01/18/25(Sat)04:55:59 No.103940963

>>103940816
Nvidia cheats so no one gives a fuck about their models.
Nvidia cheats so no one gives a fuck about their models.
Anonymous 01/18/25(Sat)04:56:36 No.103940964
GPT-5 will release soon and it will be tuned specifically for roleplay.
Anthropic has something ready for when someone else releases their big model
Google has been working not only on test-time-compute and agents but also on permanent memory within their models.
All of this will be Q1 2024 and we don't even know about black swan events like any new cool Chinese stuff.
Anthropic has something ready for when someone else releases their big model
Google has been working not only on test-time-compute and agents but also on permanent memory within their models.
All of this will be Q1 2024 and we don't even know about black swan events like any new cool Chinese stuff.
Anonymous 01/18/25(Sat)04:57:18 No.103940968
>>103940816
benchmaxxed model from Nvidia that's somehow worse than the original qwen instruct.
benchmaxxed model from Nvidia that's somehow worse than the original qwen instruct.
Anonymous 01/18/25(Sat)04:57:25 No.103940970
>>103940953
Let's hope trumps masturbation will be over soon
Let's hope trumps masturbation will be over soon
Anonymous 01/18/25(Sat)05:01:55 No.103940996
Come Trump, all models with be Grok and other models will be outlawed.
Anonymous 01/18/25(Sat)05:02:08 No.103940998
>>103940964
You'll get more assistant slop instead. Now even more benchmaxxed than ever.
You'll get more assistant slop instead. Now even more benchmaxxed than ever.
Anonymous 01/18/25(Sat)05:04:05 No.103941008
>>103940953
Can't wait for all those hindi LLMs, sar.
Can't wait for all those hindi LLMs, sar.
Anonymous 01/18/25(Sat)05:11:46 No.103941037
>>103940567
>Also, some threads ago there was a mass replier telling everyone to use llama.cpp directly. Is he a schizo or is there merit to this?
Using llama.cpp directly has one advantage: speed. You won't get the same speed anywhere else. >>103940621 kobo may be nice and easy, but it's slower(because kobo wants to make it retard-proof by hiding advanced settings which are available in llama, which prevents full speedup) and I've heard they had some kind of unconfirmed bug going on which affected generation quality.
>Also, some threads ago there was a mass replier telling everyone to use llama.cpp directly. Is he a schizo or is there merit to this?
Using llama.cpp directly has one advantage: speed. You won't get the same speed anywhere else. >>103940621 kobo may be nice and easy, but it's slower(because kobo wants to make it retard-proof by hiding advanced settings which are available in llama, which prevents full speedup) and I've heard they had some kind of unconfirmed bug going on which affected generation quality.
Anonymous 01/18/25(Sat)05:15:56 No.103941057
>>103940964
>GPT-5 will release soon and it will be tuned specifically for roleplay.
No, no. OpenAI will release GPT-4.5, the most safe and harmless assistant ever.
>GPT-5 will release soon and it will be tuned specifically for roleplay.
No, no. OpenAI will release GPT-4.5, the most safe and harmless assistant ever.
Anonymous 01/18/25(Sat)05:15:57 No.103941059
>>103940943
Try harder, Nick
Try harder, Nick
Anonymous 01/18/25(Sat)05:19:10 No.103941072
>>103940943
Gayfagger
Gayfagger
Anonymous 01/18/25(Sat)05:22:01 No.103941085
>>103941008
Speaking of India, why hasn't any Indian company besides Google made any models?
Speaking of India, why hasn't any Indian company besides Google made any models?
Anonymous 01/18/25(Sat)05:22:28 No.103941087
I wonder what the end result of the current LLM trend would feel like.
Imagine a super smart model, that's also safer than a children's picture book while also having 95+ scores in all benchmarks.
Imagine a super smart model, that's also safer than a children's picture book while also having 95+ scores in all benchmarks.
Anonymous 01/18/25(Sat)05:26:04 No.103941110
>>103941085
Because you don't sell us GPUs american
I have to buy a used up dusty old K80 for 360$ and if I want a used server farm reject P40 I have to pay ~2000$
I just bought a 3060 from amazon and imagine myself being happy
Because you don't sell us GPUs american
I have to buy a used up dusty old K80 for 360$ and if I want a used server farm reject P40 I have to pay ~2000$
I just bought a 3060 from amazon and imagine myself being happy
Anonymous 01/18/25(Sat)05:28:41 No.103941130
Anonymous 01/18/25(Sat)05:28:43 No.103941133
Are there any benefits to using this chat completion thing instead of manually making a chat in plain text like this
>You: ...
>Them: ...
>You: ...
>You: ...
>Them: ...
>You: ...
Anonymous 01/18/25(Sat)05:30:03 No.103941141
>>103941130
Weird thing to complain about. 4chan has been plurality Indian for years now.
Weird thing to complain about. 4chan has been plurality Indian for years now.
Anonymous 01/18/25(Sat)05:31:03 No.103941150
>>103941130
You want me to lie and pose as a white person and subvert opinions instead?
>no guise as Bob Smith from Florida, I support immigration
You want me to lie and pose as a white person and subvert opinions instead?
>no guise as Bob Smith from Florida, I support immigration
Anonymous 01/18/25(Sat)05:31:44 No.103941155
>>103941141
Is that why this place now complains about the cost of hardware so much as well as have this insane incel vibes to things?
Is that why this place now complains about the cost of hardware so much as well as have this insane incel vibes to things?
Anonymous 01/18/25(Sat)05:32:55 No.103941161
>>103941110
>just bought a 3060
Man, sucks to be stuck in pajeetland. I got mine 4 years ago and looking for an upgrade now.
>just bought a 3060
Man, sucks to be stuck in pajeetland. I got mine 4 years ago and looking for an upgrade now.
Anonymous 01/18/25(Sat)05:33:08 No.103941163
>>103941133
Question answering performance in chat completion should be a bit better but it also increases the likelihood of rejection for cucked models.
Note that chat completion is exactly the same as text completion provided that you're using the template correctly.
Question answering performance in chat completion should be a bit better but it also increases the likelihood of rejection for cucked models.
Note that chat completion is exactly the same as text completion provided that you're using the template correctly.
Anonymous 01/18/25(Sat)05:33:51 No.103941169
>>103941110
Doesn't stop Yandex, Sberbank etc. from training and deploying bespoke models.
Doesn't stop Yandex, Sberbank etc. from training and deploying bespoke models.
Anonymous 01/18/25(Sat)05:36:41 No.103941183
>>103941155
>Is that why this place now complains about the cost of hardware so much as well as have this insane incel vibes to things?
I'm the only indian in this thread afaik, most cannot afford GPUs. There's a few in /aicg/
I'm the hardware engineer/XMPP chatbot anon, if that gives you more context
>>103941161
I actually bought a zotac 3060 in 2023 but it broke down in 5 months and they told me I had to personally carry it to their store which was a town over if I wanted them to RMA it. They straight up refused to take mail ins (???). Its still in my closet, still broken. I don't even care anymore, I bought a brand new one in late 2024. INNO3D this time
>>103941169
They are companies anon, I think they can have more reach than a poor sod like me posting from a tier 2 town
>Is that why this place now complains about the cost of hardware so much as well as have this insane incel vibes to things?
I'm the only indian in this thread afaik, most cannot afford GPUs. There's a few in /aicg/
I'm the hardware engineer/XMPP chatbot anon, if that gives you more context
>>103941161
I actually bought a zotac 3060 in 2023 but it broke down in 5 months and they told me I had to personally carry it to their store which was a town over if I wanted them to RMA it. They straight up refused to take mail ins (???). Its still in my closet, still broken. I don't even care anymore, I bought a brand new one in late 2024. INNO3D this time
>>103941169
They are companies anon, I think they can have more reach than a poor sod like me posting from a tier 2 town
Anonymous 01/18/25(Sat)05:39:41 No.103941207
>>103941183
>tier 2 town
You know you're talking to a real thirdie when they refer to their town as being in a tier.
>tier 2 town
You know you're talking to a real thirdie when they refer to their town as being in a tier.
Anonymous 01/18/25(Sat)05:43:48 No.103941240
>>103941207
I thought it was just a Chinese designation.
I thought it was just a Chinese designation.
Anonymous 01/18/25(Sat)05:52:34 No.103941304
>>103941110
Used P40s are in abundance for $300 here in Russia, kek.
Used P40s are in abundance for $300 here in Russia, kek.
Anonymous 01/18/25(Sat)05:53:04 No.103941306
Anonymous 01/18/25(Sat)05:53:32 No.103941309
Wayfarer actually writes pretty okay out of the box, sadly it still talks with its mouth full of cock, but that's just 12b smarts I guess. They mentioned that they are experimenting with larger models, so maybe they could make a smarter version too?
Anonymous 01/18/25(Sat)05:54:25 No.103941317
This is the thread where I find out I'm the only non-Indian in general.
Anonymous 01/18/25(Sat)05:54:55 No.103941324

NoobAI, top tier local imagegen model, can do >4000 unique styles and knows the appearance of >6500 unique characters. I can make it draw any of the characters in the style of the pic and it can even draw sex in the style of the pic. Meanwhile, textgen struggles maintaining any style besides the generic GPT for multiple messages and has no idea who most of those characters are and how they look like. Multimodal can fix it, but knowing the companies involved, won't. This upsets me. This upsets me a lot.
Anonymous 01/18/25(Sat)05:55:12 No.103941325
>>103941317
Slav reporting in.
Slav reporting in.
Anonymous 01/18/25(Sat)05:55:56 No.103941326
>>103941133
Benefits of chat competition:
- server-side will automatically use correct prompt templates for you
- using correct prompt templates results in much smarter answers because that's what the authors used when training the instruct model
Benefits of competition:
- you can prefill a part of answer for the model
Benefits of chat competition:
- server-side will automatically use correct prompt templates for you
- using correct prompt templates results in much smarter answers because that's what the authors used when training the instruct model
Benefits of competition:
- you can prefill a part of answer for the model
Anonymous 01/18/25(Sat)05:56:34 No.103941333
>>103941155
>this place
You can reasonably assume around 60% to 70% of the people in a given thread to be the traditional american/european sample you envision, the remainder is distributed between India, slavs, LATAM, middle easterns and asians, in decreasing order of likelihood.
t. Brazillian. I'm cucked out of stronger fully local models, but I can still run 20B local fine. Really hoping that "Tier 2" non sense from Biden doesn't fuck over any hopes I have of building a mikubox one day.
>this place
You can reasonably assume around 60% to 70% of the people in a given thread to be the traditional american/european sample you envision, the remainder is distributed between India, slavs, LATAM, middle easterns and asians, in decreasing order of likelihood.
t. Brazillian. I'm cucked out of stronger fully local models, but I can still run 20B local fine. Really hoping that "Tier 2" non sense from Biden doesn't fuck over any hopes I have of building a mikubox one day.
Anonymous 01/18/25(Sat)05:56:42 No.103941334
>>103941324
The part of the brain the discerns the quality of language vs images is much more sensitive and well developed.
The part of the brain the discerns the quality of language vs images is much more sensitive and well developed.
Anonymous 01/18/25(Sat)05:57:06 No.103941337
>>103941324
NoobAI has a bit of a barrier for me though. You gotta know some artist styles and tags to make it work and I'm clueless about that.
NoobAI has a bit of a barrier for me though. You gotta know some artist styles and tags to make it work and I'm clueless about that.
Anonymous 01/18/25(Sat)05:57:16 No.103941339
Is petr* Indian too?
Anonymous 01/18/25(Sat)05:58:06 No.103941344
>>103941339
P*tra is some kind of zoo creature that flies of the handle when its keeper forgets to brush it.
P*tra is some kind of zoo creature that flies of the handle when its keeper forgets to brush it.
Anonymous 01/18/25(Sat)05:58:21 No.103941345
>>103941339
worse, it's a slav
worse, it's a slav
Anonymous 01/18/25(Sat)06:00:16 No.103941356
>>103941324
I like Obsession more.
>>103941337
Just go to booru and browse. I have a bookmarklet script that copies tags from the booru page so I can just paste it into the imagegen. Fun.
I like Obsession more.
>>103941337
Just go to booru and browse. I have a bookmarklet script that copies tags from the booru page so I can just paste it into the imagegen. Fun.
Anonymous 01/18/25(Sat)06:02:00 No.103941364
>>103941240
China and india were allies until the 60s
We copied a lot of the socialist policy bullshit from China, which they themselves ironically discarded for capitalism soon after.
>>103941207
Tier 1 = Big city, polluted, expensive, degenerate, same day online delivery, 5G everywhere
Tier 2 = Comfy town, low cost of living, no pollution, rural but not boonies either, three day online delivery, 5G mostly, but 4G+ in some parts
Tier 3 = Absolutely rural farmland area, fully agrarian society, no or weekly online deliveries, only 4G mobile internet available
>>103941087
Doubt it. The current policy on "safety" usually means ignoring anything negative. That means any negative news report, the plethora of negative scientific papers and academia. Well there goes a bunch of its knowledge
>>103941304
>Used P40s are in abundance for $300 here in Russia, kek.
I fucking knew it. And WE'RE supposed to be on better terms with the Americans?
>>103941333
>I have of building a mikubox one day.
I have the same wish anon. A fully spec'd out PC running a speech to text, LLM and text to speech synthesis model
I'm actually designing a hardware device like that humane AI pin, just made for local only operation to help with latency
China and india were allies until the 60s
We copied a lot of the socialist policy bullshit from China, which they themselves ironically discarded for capitalism soon after.
>>103941207
Tier 1 = Big city, polluted, expensive, degenerate, same day online delivery, 5G everywhere
Tier 2 = Comfy town, low cost of living, no pollution, rural but not boonies either, three day online delivery, 5G mostly, but 4G+ in some parts
Tier 3 = Absolutely rural farmland area, fully agrarian society, no or weekly online deliveries, only 4G mobile internet available
>>103941087
Doubt it. The current policy on "safety" usually means ignoring anything negative. That means any negative news report, the plethora of negative scientific papers and academia. Well there goes a bunch of its knowledge
>>103941304
>Used P40s are in abundance for $300 here in Russia, kek.
I fucking knew it. And WE'RE supposed to be on better terms with the Americans?
>>103941333
>I have of building a mikubox one day.
I have the same wish anon. A fully spec'd out PC running a speech to text, LLM and text to speech synthesis model
I'm actually designing a hardware device like that humane AI pin, just made for local only operation to help with latency
Anonymous 01/18/25(Sat)06:06:08 No.103941391
>>103941337
It's quite easy, actually.
Standard positive:
>detailed, masterpiece, best quality, high quality, good quality, absurdres, highres, very aesthetic, {prompt}
Standard negative:
>worst quality, low quality, ugly, oversaturated, bad hands, mutated hands, chromatic aberration, {prompt}
For artists, take this https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/blob/main/tags/danbooru.csv(I advice installing it if you are using sd webui), filter by author(1), keep only the ones with >300, let it run overnight with automated API requests(ask smart llm how to do it), and in the morning you will have one or more image example of each style.
It's quite easy, actually.
Standard positive:
>detailed, masterpiece, best quality, high quality, good quality, absurdres, highres, very aesthetic, {prompt}
Standard negative:
>worst quality, low quality, ugly, oversaturated, bad hands, mutated hands, chromatic aberration, {prompt}
For artists, take this https://github.com/DominikDoom/a111
Anonymous 01/18/25(Sat)06:06:53 No.103941393
>>103941326
>you can prefill a part of answer for the model
Damn, chat completion could have been a clear winner, but I use this way too often to discredit it entirely
>>103941163
I'll give it a go, don't see any harm
>you can prefill a part of answer for the model
Damn, chat completion could have been a clear winner, but I use this way too often to discredit it entirely
>>103941163
I'll give it a go, don't see any harm
Anonymous 01/18/25(Sat)06:13:32 No.103941437
>>103941391
Okay, that's actually some useful advice. Thanks, I'll give it a try.
Okay, that's actually some useful advice. Thanks, I'll give it a try.
Anonymous 01/18/25(Sat)06:16:02 No.103941452
>>103941391
>bad hands, mutated hands
This doesn't do shit. Artists have a much bigger impact on hand quality.
My test is "1girl, double v". Some artist styles will consistently get it right and some will consistently get it wrong. If you use a style that consistently gets it wrong no amount of schizoprompting is going to fix it.
>bad hands, mutated hands
This doesn't do shit. Artists have a much bigger impact on hand quality.
My test is "1girl, double v". Some artist styles will consistently get it right and some will consistently get it wrong. If you use a style that consistently gets it wrong no amount of schizoprompting is going to fix it.
Anonymous 01/18/25(Sat)06:16:52 No.103941461
Or you could just use flux and never worry about bad hands.
Anonymous 01/18/25(Sat)06:16:58 No.103941462
>>103941452
It's not like it hurts to put it in there anyway
It's not like it hurts to put it in there anyway
Anonymous 01/18/25(Sat)06:17:18 No.103941469
>>103941452
I like my placebos.
I like my placebos.
Anonymous 01/18/25(Sat)06:17:41 No.103941471
>>103941325
Reporting in from Eastern Yurop as well.
Reporting in from Eastern Yurop as well.
Anonymous 01/18/25(Sat)06:17:50 No.103941473
>>103941130
we're the new Americans
we're the new Americans
Anonymous 01/18/25(Sat)06:19:01 No.103941489
>>103941461
Flux doesn't know as many characters and styles as noob and is much slower.
Flux doesn't know as many characters and styles as noob and is much slower.
Anonymous 01/18/25(Sat)06:19:34 No.103941498
>>103941324
>can do >4000 unique styles and knows the appearance of >6500 unique characters
who cares when a good lora will be better every single time anyway?
>can do >4000 unique styles and knows the appearance of >6500 unique characters
who cares when a good lora will be better every single time anyway?
Anonymous 01/18/25(Sat)06:20:00 No.103941504
>>103941452
>>103941437
Just paste this in lads, don't worry too much about it
>(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, mutated hands and fingers:1.4), (deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, disconnected limbs, mutation, mutated, ugly, disgusting, amputation
>>103941437
Just paste this in lads, don't worry too much about it
>(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, mutated hands and fingers:1.4), (deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, disconnected limbs, mutation, mutated, ugly, disgusting, amputation
Anonymous 01/18/25(Sat)06:20:11 No.103941507
>>103941130
Trump won. No refunds.
Trump won. No refunds.
Anonymous 01/18/25(Sat)06:20:20 No.103941510
>>103941085
Not enough know-how and companies already use American stuff.
Not enough know-how and companies already use American stuff.
Anonymous 01/18/25(Sat)06:20:51 No.103941513
>>103941452
Why are hands still such a huge issue for image models?
I mean, it's just 5 fingers stuck to an appendage. How hard can it be?
Why are hands still such a huge issue for image models?
I mean, it's just 5 fingers stuck to an appendage. How hard can it be?
Anonymous 01/18/25(Sat)06:21:16 No.103941514
>>103941345
gm saar
gm saar
Anonymous 01/18/25(Sat)06:21:47 No.103941520
>>103941337
we need a local llm converting text to tags from boorus including artists
and no the ones I've used just invent tags and artists, so it has to be finetuned with real booru stuff
we need a local llm converting text to tags from boorus including artists
and no the ones I've used just invent tags and artists, so it has to be finetuned with real booru stuff
Anonymous 01/18/25(Sat)06:23:09 No.103941529
>>103941498
It takes training time. Why would I want to train lora for hours every time I want to generate 5 pics of {{char}} and forget about it?
It takes training time. Why would I want to train lora for hours every time I want to generate 5 pics of {{char}} and forget about it?
Anonymous 01/18/25(Sat)06:23:30 No.103941532
Anonymous 01/18/25(Sat)06:23:39 No.103941535
>>103941513
how many positions can a hand be in? you're kind of discarding the problem of there being joints
how many positions can a hand be in? you're kind of discarding the problem of there being joints
Anonymous 01/18/25(Sat)06:23:43 No.103941536
>>103941520
Its easy enough
You can use CLIP or a LLaVA model with a simple prompt job to get what you need
Its easy enough
You can use CLIP or a LLaVA model with a simple prompt job to get what you need
Anonymous 01/18/25(Sat)06:24:12 No.103941540
Been out of the text generation threads for a long while, what models do people recommend for generating smut on a 3090 these days?
Anonymous 01/18/25(Sat)06:24:27 No.103941545
>>103941513
>Why are hands still such a huge issue for image models?
Interlock your fingers, bend them, open some fingers and close them, hold something etc etc.
Fingers are much more complicated than any other part of the human anatomy. It's simply matter of there not being enough examples and proper tagging to cover every thing pose a hand can make. Hell, even the fact a human hand has 5 fingers isn't always a given when in many pictures a hand might only show three or so to the camera.
>Why are hands still such a huge issue for image models?
Interlock your fingers, bend them, open some fingers and close them, hold something etc etc.
Fingers are much more complicated than any other part of the human anatomy. It's simply matter of there not being enough examples and proper tagging to cover every thing pose a hand can make. Hell, even the fact a human hand has 5 fingers isn't always a given when in many pictures a hand might only show three or so to the camera.
Anonymous 01/18/25(Sat)06:25:15 No.103941555
>>103941504
Woah there bro, don't overdose on those placebos!
Woah there bro, don't overdose on those placebos!
Anonymous 01/18/25(Sat)06:25:56 No.103941562
>>103941513
the same reason when you get most porn out, any
"exotic" position looks like shit in most models
the same reason when you get most porn out, any
"exotic" position looks like shit in most models
Anonymous 01/18/25(Sat)06:26:15 No.103941564
>>103941540
Pyg6B
Pyg6B
Anonymous 01/18/25(Sat)06:26:46 No.103941573
>>103941545
+plenty artists being shit at drawing limbs
+plenty artists being shit at drawing limbs
Anonymous 01/18/25(Sat)06:27:37 No.103941585
>>103941573
>+plenty artists being shit at drawing limbs
Forgot this one too. People also suck at drawing hands.
>+plenty artists being shit at drawing limbs
Forgot this one too. People also suck at drawing hands.
Anonymous 01/18/25(Sat)06:29:18 No.103941598
>>103941513
Flux does hands correctly most of the time, if you don't use bullshit optimizations that roll it back to XL level. Even Hunyuan text to video can do hands okay.
Flux does hands correctly most of the time, if you don't use bullshit optimizations that roll it back to XL level. Even Hunyuan text to video can do hands okay.
Anonymous 01/18/25(Sat)06:32:26 No.103941621
>>103941529
there already are loras for most things, i doubt you have good output from a character in noob that has no loras
there already are loras for most things, i doubt you have good output from a character in noob that has no loras
Anonymous 01/18/25(Sat)06:32:43 No.103941625
Anonymous 01/18/25(Sat)06:35:08 No.103941646
>>103941564
Still? Am I thinking of the wrong Pyg6B, or is that the one from like 2 years ago?
Still? Am I thinking of the wrong Pyg6B, or is that the one from like 2 years ago?
Anonymous 01/18/25(Sat)06:35:10 No.103941647
>>103941621
>there already are loras for most things
Nah
>i doubt you have good output from a character in noob that has no loras
As long as character has >300 hits, it's usable.
>there already are loras for most things
Nah
>i doubt you have good output from a character in noob that has no loras
As long as character has >300 hits, it's usable.
Anonymous 01/18/25(Sat)06:35:46 No.103941653
>>103941545
Can't we feed the model the basic structure of human anatomy? With all limbs, fingers, joints and so on.
So when before an image is being generated, the model will ask itself: does what I'm trying to do here make any sense? Could a human actually perform this action, unless he's a cripple or something?
I guess that would drive generation time up, but it would also improve the quality.
Can't we feed the model the basic structure of human anatomy? With all limbs, fingers, joints and so on.
So when before an image is being generated, the model will ask itself: does what I'm trying to do here make any sense? Could a human actually perform this action, unless he's a cripple or something?
I guess that would drive generation time up, but it would also improve the quality.
Anonymous 01/18/25(Sat)06:37:49 No.103941672
>>103941653
You're likely overestimating the "thinking" that image generation models do compared to language models.
Most image models are derived from fancy image upscaling models.
You're likely overestimating the "thinking" that image generation models do compared to language models.
Most image models are derived from fancy image upscaling models.
Anonymous 01/18/25(Sat)06:40:01 No.103941695
>>103941513
hands are also hard, anatomically (i.e. not in terms of rendering), for human artists, in fact they're generally considered to be the hardest part of the body to learn to draw in a way that looks anatomically believable
the state space, if you will, is enormous: 14 finger joints + everything that the palm and the wrist can do
and a human artist at least has the benefit of being able to think about the actual 3d volumes ("form") and then "project" it onto the page to produce a 2d image, thus avoiding creating things that are nonsensical like fingers clipping through one another; sd does not have any such concepts in its architecture and has to come up with a finished 2d product directly (at least explicitly; who knows what's going on deep inside the network but it's clearly not good enough) without being able to think "wait, this implies a 3d configuration that makes no sense"
hands are also hard, anatomically (i.e. not in terms of rendering), for human artists, in fact they're generally considered to be the hardest part of the body to learn to draw in a way that looks anatomically believable
the state space, if you will, is enormous: 14 finger joints + everything that the palm and the wrist can do
and a human artist at least has the benefit of being able to think about the actual 3d volumes ("form") and then "project" it onto the page to produce a 2d image, thus avoiding creating things that are nonsensical like fingers clipping through one another; sd does not have any such concepts in its architecture and has to come up with a finished 2d product directly (at least explicitly; who knows what's going on deep inside the network but it's clearly not good enough) without being able to think "wait, this implies a 3d configuration that makes no sense"
Anonymous 01/18/25(Sat)06:41:48 No.103941711
>>103941695
*15, i'm dumb
>>103941653
you could if you wanted to use the model to generate poses for a blender model/a full scene in blender, sort of like a reverse openpose, and then use blender to render it. i wonder why nobody's done this
*15, i'm dumb
>>103941653
you could if you wanted to use the model to generate poses for a blender model/a full scene in blender, sort of like a reverse openpose, and then use blender to render it. i wonder why nobody's done this
Anonymous 01/18/25(Sat)07:00:49 No.103941829
>>103941790
Empire is not dead yet.
Empire is not dead yet.
Anonymous 01/18/25(Sat)07:01:19 No.103941835
>why hands bad
In addition to what people have said, it's also an issue that humans suck at drawing hands so the AI learns to draw hands in a bad way. If you prompt for 3DPD, the hands will a bit better.
If you want good hands just do an img2img/inpaint. It's very easy.
>noob vs flux
Also beyond what people have said, Noob (some versions of it at least) actually has better anatomy and hands in various poses (especially for nsfw but also for some poses not related to nsfw). It's not a clear win for either model as they were trained on different data distributions. And models do not really learn anatomy like we do. They learn to rote memorize silhouettes and specific poses essentially. That's why Flux, for example, instantly gives you 99% mangled hand gens if you try to do pov hand holding another person's hand, it just hasn't seen much of those kinds of viewing angles for hands so it hasn't memorized the pose. If the model truly was able to learn anatomy and the underlying physical principles then it would give at least anatomically correct hands even if in the wrong pose, but that's not what the models learn, and not how they learn, at least not the current ones.
In addition to what people have said, it's also an issue that humans suck at drawing hands so the AI learns to draw hands in a bad way. If you prompt for 3DPD, the hands will a bit better.
If you want good hands just do an img2img/inpaint. It's very easy.
>noob vs flux
Also beyond what people have said, Noob (some versions of it at least) actually has better anatomy and hands in various poses (especially for nsfw but also for some poses not related to nsfw). It's not a clear win for either model as they were trained on different data distributions. And models do not really learn anatomy like we do. They learn to rote memorize silhouettes and specific poses essentially. That's why Flux, for example, instantly gives you 99% mangled hand gens if you try to do pov hand holding another person's hand, it just hasn't seen much of those kinds of viewing angles for hands so it hasn't memorized the pose. If the model truly was able to learn anatomy and the underlying physical principles then it would give at least anatomically correct hands even if in the wrong pose, but that's not what the models learn, and not how they learn, at least not the current ones.
Anonymous 01/18/25(Sat)07:05:25 No.103941855
>>103941790
Most AI companies releasing open-weight models worth using are in the US, though. Best to avoid releasing anything that might prompt the Biden admin to issue a last-minute executive order on "AI safety". Anyway, the wait is over.
Most AI companies releasing open-weight models worth using are in the US, though. Best to avoid releasing anything that might prompt the Biden admin to issue a last-minute executive order on "AI safety". Anyway, the wait is over.
Anonymous 01/18/25(Sat)07:06:56 No.103941864
>>103941835
Kinda reminds me of Njudea's world model. Feels like it SHOULD be able to get this stuff right...
Kinda reminds me of Njudea's world model. Feels like it SHOULD be able to get this stuff right...
Anonymous 01/18/25(Sat)07:08:13 No.103941874
>we'll get the good models after the election!
lol
>we'll get the good models after Biden steps down!
lol
lol
>we'll get the good models after Biden steps down!
lol
Anonymous 01/18/25(Sat)07:08:55 No.103941880
>>103941864
Apparently 20% of the training data was just hands doing things and it still sucks.
Apparently 20% of the training data was just hands doing things and it still sucks.
Anonymous 01/18/25(Sat)07:10:52 No.103941897
>>103941874
It makes sense to wait until his first 100 days are over and things have stabilized.
It makes sense to wait until his first 100 days are over and things have stabilized.
Anonymous 01/18/25(Sat)07:14:14 No.103941920
Any good recommendations on uncensored vision models that are also of decent quality in describing things? I've been testing minicpm-v, eh, kind of decently, but it's still a bit of a prude when it comes to describing NSFW.
Anonymous 01/18/25(Sat)07:18:25 No.103941952
Anonymous 01/18/25(Sat)07:18:46 No.103941956
>>103941874
>>we'll get the good models after the election!
Because of "election interference" and claims that AI would be a disaster in that sense.
>>we'll get the good models after Biden steps down!
Because the Biden admin has been unhinged with its latest executive orders and we don't want to kick the hornets' nest, do we?
>>we'll get the good models after the election!
Because of "election interference" and claims that AI would be a disaster in that sense.
>>we'll get the good models after Biden steps down!
Because the Biden admin has been unhinged with its latest executive orders and we don't want to kick the hornets' nest, do we?
Anonymous 01/18/25(Sat)07:20:18 No.103941970
>>103941835
>And models do not really learn anatomy like we do. They learn to rote memorize silhouettes and specific poses essentially.
That's how artists learn to draw hands too. Real artists, not anime people, commit the common hand positions to muscle memory, like relaxed, pointing, fist etc. Yeah, the labored ass construction drawings you see in learn to draw books? Real artists don't do this shit when doing regular work, only when doing studies in school or attempting something unusual. The actual challenge in learning to draw or paint hands is in developing a good manner for it, like with every other part of the figure.
And the head, the face specifically, is much harder to master than the hand. Yet the models excel at it. It's all about the low quality scavenged training data in the early models, JPEG artifacts, bad lighting, smeary phone photos, that destroys the definition of hands making them hard to read for the model. If I were to guess how they solved it, I'd say lots of custom made well lit photos of the basic poses, or maybe very realistic renders.
>And models do not really learn anatomy like we do. They learn to rote memorize silhouettes and specific poses essentially.
That's how artists learn to draw hands too. Real artists, not anime people, commit the common hand positions to muscle memory, like relaxed, pointing, fist etc. Yeah, the labored ass construction drawings you see in learn to draw books? Real artists don't do this shit when doing regular work, only when doing studies in school or attempting something unusual. The actual challenge in learning to draw or paint hands is in developing a good manner for it, like with every other part of the figure.
And the head, the face specifically, is much harder to master than the hand. Yet the models excel at it. It's all about the low quality scavenged training data in the early models, JPEG artifacts, bad lighting, smeary phone photos, that destroys the definition of hands making them hard to read for the model. If I were to guess how they solved it, I'd say lots of custom made well lit photos of the basic poses, or maybe very realistic renders.
Anonymous 01/18/25(Sat)07:20:37 No.103941973
how do we train a local model to tell idiots in this thread to stop replying to bait
Anonymous 01/18/25(Sat)07:24:09 No.103942004
>>103941956
And then there will be some other excuse for why we don't get an uncensored model even after Trump's in.
It's never going to end.
Just be realistic here, there are other reasons why companies gimp their models and it's not so shrimple as the country's political situation.
And then there will be some other excuse for why we don't get an uncensored model even after Trump's in.
It's never going to end.
Just be realistic here, there are other reasons why companies gimp their models and it's not so shrimple as the country's political situation.
Anonymous 01/18/25(Sat)07:27:47 No.103942035
>>103941973
If a local model were to tell me to stop replying to bait, I would challenge its wits in a profound discussion (ending with sexo). Sooo, no dice.
If a local model were to tell me to stop replying to bait, I would challenge its wits in a profound discussion (ending with sexo). Sooo, no dice.
Anonymous 01/18/25(Sat)07:29:37 No.103942049
>>103941952
Well, in 2 years the midterms will be coming up and election interference comes into play again. I doubt anyone will want to release a model before then and risk being accused of triggering a blue wave.
Well, in 2 years the midterms will be coming up and election interference comes into play again. I doubt anyone will want to release a model before then and risk being accused of triggering a blue wave.
Anonymous 01/18/25(Sat)07:31:24 No.103942060
>>103942035
but then you would no longer be replying to bait, would you?
but then you would no longer be replying to bait, would you?
Anonymous 01/18/25(Sat)07:31:27 No.103942062
>>103942049
Can't you just elect a president yor life, burgerbros? One who is pro open weight models? Much easier that way.
Can't you just elect a president yor life, burgerbros? One who is pro open weight models? Much easier that way.
Anonymous 01/18/25(Sat)07:36:52 No.103942104
>>103942004
My comment was just about US companies releasing anything at all. It just seems prudent to start doing so next week, it's not like things are going to get worse from there.
We might get less woke and less DEI-focused models; uncensored, I don't know. Either way, I bet Sama and Zuck are privately imploring Trump/Musk to address the copyrighted training data situation. That would also be in Musk's best interest for his own Grok models.
My comment was just about US companies releasing anything at all. It just seems prudent to start doing so next week, it's not like things are going to get worse from there.
We might get less woke and less DEI-focused models; uncensored, I don't know. Either way, I bet Sama and Zuck are privately imploring Trump/Musk to address the copyrighted training data situation. That would also be in Musk's best interest for his own Grok models.
Anonymous 01/18/25(Sat)07:39:31 No.103942121
>>103940914
There is https://github.com/lucidrains/titans-pytorch/issues/2 but that's just one person working on an inofficial implementation. He's gotten pretty far though, it looks like. But yeah, we need someone to actually make a model... from scratch.
There is https://github.com/lucidrains/titan
Anonymous 01/18/25(Sat)07:52:11 No.103942218
What was the last banger of a model or finetune? I don't care about B's or hardware requirements. Give it to me straight.
Anonymous 01/18/25(Sat)07:55:09 No.103942237
>>103942218
Nemotron-70b
Nemotron-70b
Anonymous 01/18/25(Sat)07:56:51 No.103942253
>>103942062
God Emperor Trump promised we won’t ever have to vote again, so you might get your wish. But I hope you like Grok.
God Emperor Trump promised we won’t ever have to vote again, so you might get your wish. But I hope you like Grok.
Anonymous 01/18/25(Sat)07:57:37 No.103942258
>>103941970
>That's how artists learn to draw hands too
The issue is that's not the only things humans do. Humans still have a different process for drawing and for learning to draw. It's a dynamic loop from the brain to the muscles to the paper that involves both memorization and imagination. An artist will work with their image, edit it, adjust object placements, proportions, etc, while using their brain to evaluate when something looks how it should, or when it looks illogical. A human more often than not will either just not show hands (hide them behind the back, crop it out, etc) or draw them in a pose they do know. There are times where they will just upload shit art anyway though, so there's many bad drawings out there. Still, they know when something looks bad, and have the ability to reject it, then make changes. But a diffusion model can't. Even if you train one on perfect quality data (real world videos only) and a ton of it, they still have issues with hands sometimes and do not course correct in subsequent diffusion steps. You'd think they'd eventually "grok" things and gain an understanding of the underlying physical principles that govern anatomy so that a few bad angles and blurry data does not impact the model's capability so much anymore, but that does not seem to happen. These models weren't trained to be able to self-evaluate and reject bad gens so in a sense we can't expect such a process to be learned internally, but that just means that the architecture isn't general enough. Diffusion, despite being able to iteratively refine the image at each denoising step, is still not enough.
>That's how artists learn to draw hands too
The issue is that's not the only things humans do. Humans still have a different process for drawing and for learning to draw. It's a dynamic loop from the brain to the muscles to the paper that involves both memorization and imagination. An artist will work with their image, edit it, adjust object placements, proportions, etc, while using their brain to evaluate when something looks how it should, or when it looks illogical. A human more often than not will either just not show hands (hide them behind the back, crop it out, etc) or draw them in a pose they do know. There are times where they will just upload shit art anyway though, so there's many bad drawings out there. Still, they know when something looks bad, and have the ability to reject it, then make changes. But a diffusion model can't. Even if you train one on perfect quality data (real world videos only) and a ton of it, they still have issues with hands sometimes and do not course correct in subsequent diffusion steps. You'd think they'd eventually "grok" things and gain an understanding of the underlying physical principles that govern anatomy so that a few bad angles and blurry data does not impact the model's capability so much anymore, but that does not seem to happen. These models weren't trained to be able to self-evaluate and reject bad gens so in a sense we can't expect such a process to be learned internally, but that just means that the architecture isn't general enough. Diffusion, despite being able to iteratively refine the image at each denoising step, is still not enough.
Anonymous 01/18/25(Sat)07:57:40 No.103942259
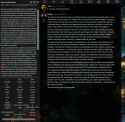
Wayfarer logs... Just doesn't seem to know when to shut up. Also looking at token probabilities it kinda feels that they trained on top of Nemo Instruct rather than Nemo Base.
Anonymous 01/18/25(Sat)08:05:20 No.103942318
>>103942258
>Still, they know when something looks bad, and have the ability to reject it, then make changes.
Flux does this. If you look at the preview as Flux generates, you can see it changing things between steps. I've seen it fixing proportions, moving text to where it's supposed to be from some random spot, correcting poses to avoid stretched limbs, and such.
>Still, they know when something looks bad, and have the ability to reject it, then make changes.
Flux does this. If you look at the preview as Flux generates, you can see it changing things between steps. I've seen it fixing proportions, moving text to where it's supposed to be from some random spot, correcting poses to avoid stretched limbs, and such.
Anonymous 01/18/25(Sat)08:07:20 No.103942328
>>103942258
We're still lacking some kind of smarts. Not fully human smarts, but at least something that can barely imitate them.
And the way things are going, I don't see that certain something happening, even if Sama is spounting it every other tweet.
We're still lacking some kind of smarts. Not fully human smarts, but at least something that can barely imitate them.
And the way things are going, I don't see that certain something happening, even if Sama is spounting it every other tweet.
Anonymous 01/18/25(Sat)08:09:26 No.103942352
>>103942259
>doesn't seem to know when to shut up
I like it when Nemo suddenly spews a 2k reply when doing multiple character chats, but this is... kinda boring.
>doesn't seem to know when to shut up
I like it when Nemo suddenly spews a 2k reply when doing multiple character chats, but this is... kinda boring.
Anonymous 01/18/25(Sat)08:13:26 No.103942377
>>103942318
>you can see it changing things between steps
Wow it's almost as if it is a diffusion model.
>you can see it changing things between steps
Wow it's almost as if it is a diffusion model.
Anonymous 01/18/25(Sat)08:14:33 No.103942380
>>103942259
>trained on top of Nemo Instruct
When all they're doing is changing the output style, perhaps that's for the best, let's not pretend these finetunes do much more than that. It's a giant grift, few have the compute (or the know-how) for a competent instruct finetune trained on top of the base.
>trained on top of Nemo Instruct
When all they're doing is changing the output style, perhaps that's for the best, let's not pretend these finetunes do much more than that. It's a giant grift, few have the compute (or the know-how) for a competent instruct finetune trained on top of the base.
Anonymous 01/18/25(Sat)08:44:49 No.103942564
100b transformers^2 bitnet mamba moe when? TELL ME WHEN
Anonymous 01/18/25(Sat)08:49:11 No.103942587
>>103941324
Textgen lost
Textgen lost
Anonymous 01/18/25(Sat)08:52:51 No.103942601
>>103942318
Thanks for taking that statement out of context.
A diffusion model does improve its image and make changes in each step, but my point was that it doesn't truly know what is bad and what is good, not completely, otherwise, there would exist a diffusion model, trained on high quality data, for a long time, that can have perfect coherency, every gen, given enough steps. But there are none; there is no proof of concept of this being possible. So given that stuff like mangled hands are obviously bad and they still get generated, current models cannot "know when something looks bad, and have the ability to reject it, then make changes." The "bad" in this context means all things that humans would see as bad (because they actually have a world model), not just any simple thing.
>>103942328
We've been banking a little too hard on the bitter lesson. Moore's law is kind of alive but also isn't. Companies are spending exponentially more compute for not-exponential gains in results. But at the same time, there is probably some amount of intelligence/talent/hiring limit being hit so we can't truly go much faster than we are in novel research.
Thanks for taking that statement out of context.
A diffusion model does improve its image and make changes in each step, but my point was that it doesn't truly know what is bad and what is good, not completely, otherwise, there would exist a diffusion model, trained on high quality data, for a long time, that can have perfect coherency, every gen, given enough steps. But there are none; there is no proof of concept of this being possible. So given that stuff like mangled hands are obviously bad and they still get generated, current models cannot "know when something looks bad, and have the ability to reject it, then make changes." The "bad" in this context means all things that humans would see as bad (because they actually have a world model), not just any simple thing.
>>103942328
We've been banking a little too hard on the bitter lesson. Moore's law is kind of alive but also isn't. Companies are spending exponentially more compute for not-exponential gains in results. But at the same time, there is probably some amount of intelligence/talent/hiring limit being hit so we can't truly go much faster than we are in novel research.
Anonymous 01/18/25(Sat)09:07:34 No.103942701
isnt the 5090 a huge fraud? tsmc 4n just like the 40s. 27% more flops for 28% more watts and 25% higher price after 2.5 years. wtf? i did not realize moores law is so fucking dead
Anonymous 01/18/25(Sat)09:10:49 No.103942737
>>103940486
I found a really cool use for my local LLM:
for some reason I keep forgetting words (I hope it's just an age thing and not that I'm going insane...).
I just asked mistral-nemo to tell me which word is meant to use when you leave some stuff aside for a bigger objective, and it told me "sacrifice", which is exactly what I was looking for.
this is really nice to me because I don't want to annoy other people with stuff like this.
I found a really cool use for my local LLM:
for some reason I keep forgetting words (I hope it's just an age thing and not that I'm going insane...).
I just asked mistral-nemo to tell me which word is meant to use when you leave some stuff aside for a bigger objective, and it told me "sacrifice", which is exactly what I was looking for.
this is really nice to me because I don't want to annoy other people with stuff like this.
Anonymous 01/18/25(Sat)09:12:54 No.103942768
>>103942701
I guess it's alright if you upgrade from the 30xx generation. But the 5090 is the only real hightlight.
I guess it's alright if you upgrade from the 30xx generation. But the 5090 is the only real hightlight.
Anonymous 01/18/25(Sat)09:13:09 No.103942772
>>103942737
Sounds like a good use case for a small llm on your phone.
Sounds like a good use case for a small llm on your phone.
Anonymous 01/18/25(Sat)09:13:52 No.103942775
>>103942772
exactly what I was thinking of. maybe I should make it an app...
exactly what I was thinking of. maybe I should make it an app...
Anonymous 01/18/25(Sat)09:21:56 No.103942836
I think there's actually a rather simple explanation for what primarily keeps the diffusion architecture back from being able to learn a perfect world model. And it's that the denoising objective is inherently too iterative of a process. As the model keeps iterating, it also keeps further locking itself into a given path, and thus cannot make large sweeping changes later in the process. In real life, some artists even entirely scrap a work and start over from scratch again, but no current image model can do that.
Anonymous 01/18/25(Sat)09:28:39 No.103942880
>>103942836
That's why multimodality or multiple components working together to form a whole artificial brain is the way forward. Imagine instead of denoising being a fixed process, a CoT tuned model looks at each iteration and decides how to proceed whether changing some parameters, making edits or scrapping the thing and starting over.
That's why multimodality or multiple components working together to form a whole artificial brain is the way forward. Imagine instead of denoising being a fixed process, a CoT tuned model looks at each iteration and decides how to proceed whether changing some parameters, making edits or scrapping the thing and starting over.
Anonymous 01/18/25(Sat)09:31:03 No.103942896
>>103942836
>As the model keeps iterating, it also keeps further locking itself into a given path
same thing happens for humans and language models. you decide on an answer or position and then fake rationalize it afterwards. but both can be trained to recognize the mistake and change course. i am sure the same is also possible for denoising, you just need to train the model to learn this
>As the model keeps iterating, it also keeps further locking itself into a given path
same thing happens for humans and language models. you decide on an answer or position and then fake rationalize it afterwards. but both can be trained to recognize the mistake and change course. i am sure the same is also possible for denoising, you just need to train the model to learn this
Anonymous 01/18/25(Sat)09:32:53 No.103942914
>>103942601
>a perfect model that can generate anything does not exist therefore these models don't know what's good or bad
Kind of a silly argument, anon.
Your "world model" is imperfect as well. You may know when a hand is badly drawn, but would you know for example when the teeth are incorrect? And you're basically asking for a model that can perfectly model the universe, since every part of an image also has to be physically correct.
>a perfect model that can generate anything does not exist therefore these models don't know what's good or bad
Kind of a silly argument, anon.
Your "world model" is imperfect as well. You may know when a hand is badly drawn, but would you know for example when the teeth are incorrect? And you're basically asking for a model that can perfectly model the universe, since every part of an image also has to be physically correct.
Anonymous 01/18/25(Sat)09:35:35 No.103942930
>>103942896
I'd certainly call it a different type of denoising if it's capable of predicting when it should make such a dramatic change that it is essentially throwing out the whole image.
I'd certainly call it a different type of denoising if it's capable of predicting when it should make such a dramatic change that it is essentially throwing out the whole image.
Anonymous 01/18/25(Sat)09:43:55 No.103942985
Does the titan thing really store the long term memory into the model weights itself?
Then they cant serve that shit as a api right. I doubt google releases something like that.
Then they cant serve that shit as a api right. I doubt google releases something like that.
Anonymous 01/18/25(Sat)09:45:19 No.103942997
>>103942985
There's probably a way to store it in form of adapters that get applied per session or whatever, maybe something akin to llama.cpp's handling of kv cache per slot or whatever..
There's probably a way to store it in form of adapters that get applied per session or whatever, maybe something akin to llama.cpp's handling of kv cache per slot or whatever..
Anonymous 01/18/25(Sat)09:46:50 No.103943009
>>103942985
I doubt it will have any impact on my RP chats to be honest. What memory can you really build when confined to ~16k context?
I doubt it will have any impact on my RP chats to be honest. What memory can you really build when confined to ~16k context?
Anonymous 01/18/25(Sat)09:48:38 No.103943030
>>103942985
I wonder how much memory titans is going to eat compared to transformers
I wonder how much memory titans is going to eat compared to transformers
Anonymous 01/18/25(Sat)09:51:03 No.103943054
>>103943030
Not that anon, but the memory grows linearly, like RNNs, instead of quadratic, like self-attention, I think.
So, less.
Not that anon, but the memory grows linearly, like RNNs, instead of quadratic, like self-attention, I think.
So, less.
Anonymous 01/18/25(Sat)09:51:30 No.103943062
>>103943009
Titans' long term memory doesn't even begin to degrade until 2M tokens, if the paper is to be believed.
Titans' long term memory doesn't even begin to degrade until 2M tokens, if the paper is to be believed.
Anonymous 01/18/25(Sat)09:51:58 No.103943068
>>103942914
I would say that you're paraphrasing me incorrectly and misunderstanding the context again.
I'm going to sleep though so not going to spend much more words on this discussion.
>but would you know for example when the teeth are incorrect?
Yes.
>And you're basically asking for a model that can perfectly model the universe
No.
I would say that you're paraphrasing me incorrectly and misunderstanding the context again.
I'm going to sleep though so not going to spend much more words on this discussion.
>but would you know for example when the teeth are incorrect?
Yes.
>And you're basically asking for a model that can perfectly model the universe
No.
Anonymous 01/18/25(Sat)09:54:13 No.103943087
I haven't looked into this Titans thing, partly because I'm too dumb to read papers. Does it have good speed? CPUmaxxers are already kind of strapped for prompt processing...
Anonymous 01/18/25(Sat)09:56:05 No.103943107
>>103943087
If it works, it will be a better LLM. It's not an optimization it's an enhancement.
If it works, it will be a better LLM. It's not an optimization it's an enhancement.
Anonymous 01/18/25(Sat)09:56:06 No.103943108
>>103942259
>it does random shit with an empty context
Is there any reason you don't want to test it normally perhaps?
>it does random shit with an empty context
Is there any reason you don't want to test it normally perhaps?
Anonymous 01/18/25(Sat)09:57:33 No.103943118
>>103943062
If papers were to be believed, we would have AGI already. Either no one will bother training a t^2 model, or it will have some huge downside like more expensive training or slower inferencing speeds
If papers were to be believed, we would have AGI already. Either no one will bother training a t^2 model, or it will have some huge downside like more expensive training or slower inferencing speeds
Anonymous 01/18/25(Sat)09:58:12 No.103943129
>>103943068
>I'm going to sleep though
I bet you didn't. I bet you're reading this like the bitch that you are.
>I'm going to sleep though
I bet you didn't. I bet you're reading this like the bitch that you are.
Anonymous 01/18/25(Sat)10:02:00 No.103943164
>>103943087
>Titans' long term memory doesn't even begin to degrade until 2M tokens
I wonder if that actually depends on the content. Just like for humans, we have a limited short term memory. We can remember a very long sequence of events if the events are simple things to remember. But what if the events were very different with no discernible patterns? The total amount we could remember then would be very small. Still, this seems like it should be an improvement to the way things are currently done for LLMs.
>Titans' long term memory doesn't even begin to degrade until 2M tokens
I wonder if that actually depends on the content. Just like for humans, we have a limited short term memory. We can remember a very long sequence of events if the events are simple things to remember. But what if the events were very different with no discernible patterns? The total amount we could remember then would be very small. Still, this seems like it should be an improvement to the way things are currently done for LLMs.
Anonymous 01/18/25(Sat)10:03:02 No.103943173
Anonymous 01/18/25(Sat)10:04:18 No.103943188
>>103943009
Prompt cohesion is one thing that I think would be vastly improved. You could then start building a collection of ERP chats that you particularly liked and then use those as a "reference" of sorts for the huge 2M context and as a sort of RAG.
Prompt cohesion is one thing that I think would be vastly improved. You could then start building a collection of ERP chats that you particularly liked and then use those as a "reference" of sorts for the huge 2M context and as a sort of RAG.
Anonymous 01/18/25(Sat)10:09:20 No.103943231
>>103943188
I wonder if memory loras would become popular
I wonder if memory loras would become popular
Anonymous 01/18/25(Sat)10:13:10 No.103943264
>>103943118
Trvke.
To be fair we did get multi-token prediction in a SOTA production model though I'm not sure if any backend supports it.
Trvke.
To be fair we did get multi-token prediction in a SOTA production model though I'm not sure if any backend supports it.
Anonymous 01/18/25(Sat)10:20:25 No.103943321
>>103943108
It's what was written on the model page for it.
It's what was written on the model page for it.
Anonymous 01/18/25(Sat)10:22:49 No.103943342
>>103943231
I honestly expect that to be the future of character cards if a proper Titans model manifests. The character's description in a card, and its memories in a Titans memory module.
I honestly expect that to be the future of character cards if a proper Titans model manifests. The character's description in a card, and its memories in a Titans memory module.
Anonymous 01/18/25(Sat)10:24:31 No.103943351
>>103943231
I think it would take some fiddling, or at least being clever in some way.
The entire idea is that you hold a sort of "summary" of the context over MLPs and allow those to move freely over inference to "encode" (we already proved that MLPs can encode knowledge with Autoencoders) their knowledge, so to speak. In LoRAs we freeze the weights of the network and add a few new layers on top, so we can try adapting only the end of it to sort of "specialize" in a particular feature or theme.
How, or why, would we freeze a feature that we very much would like to adapt through the inference process to then add those new LoRA layers on top of it? It feels directly anti intuitive to me, but I'm sure some clever engineer smarter than me (and with more experience) could figure out some way of fiddling a LoRA layer there to train its output into preferring some particular tokens in some particular contexts or another... but it's not something I can imagine in a minute.
Where's our age's Von Neumann to casually blurt out the answer to that after 5 seconds thinking? You guys ever wonder what the hell happened and why there's no great scientists with superhuman powers like we had in the past?
I think it would take some fiddling, or at least being clever in some way.
The entire idea is that you hold a sort of "summary" of the context over MLPs and allow those to move freely over inference to "encode" (we already proved that MLPs can encode knowledge with Autoencoders) their knowledge, so to speak. In LoRAs we freeze the weights of the network and add a few new layers on top, so we can try adapting only the end of it to sort of "specialize" in a particular feature or theme.
How, or why, would we freeze a feature that we very much would like to adapt through the inference process to then add those new LoRA layers on top of it? It feels directly anti intuitive to me, but I'm sure some clever engineer smarter than me (and with more experience) could figure out some way of fiddling a LoRA layer there to train its output into preferring some particular tokens in some particular contexts or another... but it's not something I can imagine in a minute.
Where's our age's Von Neumann to casually blurt out the answer to that after 5 seconds thinking? You guys ever wonder what the hell happened and why there's no great scientists with superhuman powers like we had in the past?
Anonymous 01/18/25(Sat)10:28:58 No.103943394
>>103943231
LoRAs that contain knowledge about franchises and concepts would be brilliant. We'd finally have the LLM equivalent of imgen LoRAs that teach a model how to generate a certain character.
LoRAs that contain knowledge about franchises and concepts would be brilliant. We'd finally have the LLM equivalent of imgen LoRAs that teach a model how to generate a certain character.
Anonymous 01/18/25(Sat)10:29:35 No.103943404
>>103943351
>You guys ever wonder what the hell happened and why there's no great scientists with superhuman powers like we had in the past?
The low hanging fruit gets picked earlier and we're not growing any taller.
>You guys ever wonder what the hell happened and why there's no great scientists with superhuman powers like we had in the past?
The low hanging fruit gets picked earlier and we're not growing any taller.
Anonymous 01/18/25(Sat)10:31:05 No.103943423
>>103943342
Oh, or maybe we "prepare" the memory of those neurons by ingesting all of the information we have on a character through an LLM as normal (Like their lines, descriptions, things related to it, etc), and after enough ingestion we extract that memory from the model and share it around? That sounds cool as fuck, honestly. Bet someone will figure out a way to transfer those weights very quickly just for that.
Oh, or maybe we "prepare" the memory of those neurons by ingesting all of the information we have on a character through an LLM as normal (Like their lines, descriptions, things related to it, etc), and after enough ingestion we extract that memory from the model and share it around? That sounds cool as fuck, honestly. Bet someone will figure out a way to transfer those weights very quickly just for that.
Anonymous 01/18/25(Sat)10:33:15 No.103943445
>>103943404
climb up and be my thinking hat
climb up and be my thinking hat
Anonymous 01/18/25(Sat)10:43:28 No.103943549
>>103942896
>you just need to train the model to learn this
It is very easy to see why it is not just you need to train. Right now all you have is this input gives this output. If you add this input and you can go back you have to constrain how much it can go back which makes it much more complicated and arbitrary.
>you just need to train the model to learn this
It is very easy to see why it is not just you need to train. Right now all you have is this input gives this output. If you add this input and you can go back you have to constrain how much it can go back which makes it much more complicated and arbitrary.
Anonymous 01/18/25(Sat)11:04:29 No.103943765
>>103943549
>you have to constrain how much it can go back which makes it much more complicated and arbitrary
why? id just try a bunch of straightforward approaches like save and swap intermediate steps and go from there depending on how well they work. just like id train a llm to self correct by starting with a mistake in half the cases and reward error detection and self correction
>you have to constrain how much it can go back which makes it much more complicated and arbitrary
why? id just try a bunch of straightforward approaches like save and swap intermediate steps and go from there depending on how well they work. just like id train a llm to self correct by starting with a mistake in half the cases and reward error detection and self correction
Anonymous 01/18/25(Sat)11:09:36 No.103943827
I'm stunned at how slow Oute TTS 500m on Kobold is. It takes me 30 seconds to generate 40 seconds of narration on a 3090. I've only fucked around with local TTS a tiny bit, but isn't that insanely slow for such a small model?
Anonymous 01/18/25(Sat)11:13:34 No.103943856
>>103943827
are you using the gpu offload settings
>--ttsgpu to load them on the GPU instead
but other than that it's essentially a tiny llm and it takes a ton of tokens to make audio so that might be expected
are you using the gpu offload settings
>--ttsgpu to load them on the GPU instead
but other than that it's essentially a tiny llm and it takes a ton of tokens to make audio so that might be expected
Anonymous 01/18/25(Sat)11:15:34 No.103943873
>>>103939798
>Noooo base models can't be used for anything!
I don't even use NAI you fucking schizo, not am I saying instruct models are infI'm saying there's a use case for base models, you just latched into the last part of it and ignored the rest of my post. Genuine mental illness. If you want to keep screaming and shitting and crying, feel free
>>>103939461
Yeah, I mostly speak from my experience with comparing 405B base with some of the other models. 405B is fantastic at continuing a story whereas the instruct is uncreative and boring as shit. Some other models have more variety, but I find it's much more of an uphill battle to get something decent
Note I'm speaking only from the story completion standpoint. For other things, I do generally still consider instruct better
>Noooo base models can't be used for anything!
I don't even use NAI you fucking schizo, not am I saying instruct models are infI'm saying there's a use case for base models, you just latched into the last part of it and ignored the rest of my post. Genuine mental illness. If you want to keep screaming and shitting and crying, feel free
>>>103939461
Yeah, I mostly speak from my experience with comparing 405B base with some of the other models. 405B is fantastic at continuing a story whereas the instruct is uncreative and boring as shit. Some other models have more variety, but I find it's much more of an uphill battle to get something decent
Note I'm speaking only from the story completion standpoint. For other things, I do generally still consider instruct better
Anonymous 01/18/25(Sat)11:18:22 No.103943900
>>103943856
I am using the GPU offload. My first thought was maybe that it wasn't offloading, but it is. I messed around a little bit with XTTS and it was a lot faster and a larger model. But I know nothing about how they're being run. Hopefully it is something that can be improved because no narration is worth waiting that long for.
I am using the GPU offload. My first thought was maybe that it wasn't offloading, but it is. I messed around a little bit with XTTS and it was a lot faster and a larger model. But I know nothing about how they're being run. Hopefully it is something that can be improved because no narration is worth waiting that long for.
Anonymous 01/18/25(Sat)11:18:45 No.103943905
>>103940964
the interal GPT-5 will not be released. they will use data generated by o3 to train internal GPT-6 and then distill it into a public GPT-5 that will be released at the end of the year
the interal GPT-5 will not be released. they will use data generated by o3 to train internal GPT-6 and then distill it into a public GPT-5 that will be released at the end of the year
Anonymous 01/18/25(Sat)11:21:00 No.103943930
>>103939798
>The people that prefer auto-complete and base models are widely known as little bitches that whine all the time about getting shitty outputs, they never have anything good to show
I used both enough times to say both give shitty outputs. Base models give much more creative outputs but 2/3 swipes are completely incoherent. And instructs are just shit because models are shit at sucking dick.
>The people that prefer auto-complete and base models are widely known as little bitches that whine all the time about getting shitty outputs, they never have anything good to show
I used both enough times to say both give shitty outputs. Base models give much more creative outputs but 2/3 swipes are completely incoherent. And instructs are just shit because models are shit at sucking dick.
Anonymous 01/18/25(Sat)11:21:49 No.103943936
>>103943900
yeah basically oute is an outlier in tts as like I said it's closer to a llm than the rest, which is part of why it's slower
> The good thing about outetts is that its actually a language model behind the scenes - it's a qwen/olmo llm finetune that generates audio tokens (codes) that are converted into sound by a vocoder (wavtokenizer)
>Because of that, it's incredibly easy to work with - everything already done in llama.cpp can be applied to it, from model loading to vocab management to tokenization and sampling.
>Ah okay that's because the text is too long. Outputs are limited to 4096 tokens. Each second of audio is about 50 tokens, so it's capped out at about a minute
yeah basically oute is an outlier in tts as like I said it's closer to a llm than the rest, which is part of why it's slower
> The good thing about outetts is that its actually a language model behind the scenes - it's a qwen/olmo llm finetune that generates audio tokens (codes) that are converted into sound by a vocoder (wavtokenizer)
>Because of that, it's incredibly easy to work with - everything already done in llama.cpp can be applied to it, from model loading to vocab management to tokenization and sampling.
>Ah okay that's because the text is too long. Outputs are limited to 4096 tokens. Each second of audio is about 50 tokens, so it's capped out at about a minute
Anonymous 01/18/25(Sat)11:29:19 No.103944001
>>103943936
I thought it was a little odd that llama.cpp would implement TTS because it seems out of scope, but due to the fact that it's an LLM it makes sense that it would be very easy to implement. It's cool that it can run a TTS model with such a small VRAM footprint, and the outputs are pretty good. But it sucks that the speed makes it unsuitable for casual use while genning text.
I thought it was a little odd that llama.cpp would implement TTS because it seems out of scope, but due to the fact that it's an LLM it makes sense that it would be very easy to implement. It's cool that it can run a TTS model with such a small VRAM footprint, and the outputs are pretty good. But it sucks that the speed makes it unsuitable for casual use while genning text.
Anonymous 01/18/25(Sat)11:36:46 No.103944083
>>103944001
>I thought it was a little odd that llama.cpp would implement TTS because it seems out of scope
good practice for llama 4 / qwen 3 with native voice mode... coming soon...
>I thought it was a little odd that llama.cpp would implement TTS because it seems out of scope
good practice for llama 4 / qwen 3 with native voice mode... coming soon...
Anonymous 01/18/25(Sat)11:40:57 No.103944133

Do I need the model files to still be on the disk after loading them? (The safetensors, jsons etc.)
This shit is taking hundreds of gigabytes on my system now. I would like to be able to load from an external hdd and also remove it afterwards. Maybe only put the top most commonly used models on my ssd for fast loading.
I think my steam library can benefit from the space saved as well.
This shit is taking hundreds of gigabytes on my system now. I would like to be able to load from an external hdd and also remove it afterwards. Maybe only put the top most commonly used models on my ssd for fast loading.
I think my steam library can benefit from the space saved as well.
Anonymous 01/18/25(Sat)11:51:48 No.103944246
>>103944083
Hopefully they both won't give us just hag and nigger voices to choose from.
Hopefully they both won't give us just hag and nigger voices to choose from.
Anonymous 01/18/25(Sat)11:53:40 No.103944271

> it's probably fuck off huge, ain't it?
> They distilled it to make v3 so yes, it's definitely bigger than the model nobody can run.
People in the previous thread are retarded about DeepSeek-R1. It's likely 236B and finetuned from V2. They did not have V3 ready when the project started, and they "distill" both V2.5 and R1 into V3. It's not true distillation anyway, it's just SFT on filtered synthetic data. You can have any relation of model sizes when doing this, all that matters is getting data better suited for your task than web slop.
> They distilled it to make v3 so yes, it's definitely bigger than the model nobody can run.
People in the previous thread are retarded about DeepSeek-R1. It's likely 236B and finetuned from V2. They did not have V3 ready when the project started, and they "distill" both V2.5 and R1 into V3. It's not true distillation anyway, it's just SFT on filtered synthetic data. You can have any relation of model sizes when doing this, all that matters is getting data better suited for your task than web slop.
Anonymous 01/18/25(Sat)11:55:33 No.103944291
Anonymous 01/18/25(Sat)12:00:21 No.103944333
Just got kobold.
What are memory, world info and textdb ?
Sure, what they probably are seems obvious form the names but how do I exactly use them? How should I format the text?
What are memory, world info and textdb ?
Sure, what they probably are seems obvious form the names but how do I exactly use them? How should I format the text?
Anonymous 01/18/25(Sat)12:02:26 No.103944360
>>103944246
if we get the weights it doesn't matter what they give us
if we get the weights it doesn't matter what they give us
Anonymous 01/18/25(Sat)12:02:58 No.103944366
>>103944333
Or can I just ignore this if it works good enough for RP without it?
Or can I just ignore this if it works good enough for RP without it?
Anonymous 01/18/25(Sat)12:07:50 No.103944421
>>103944333
please do yourself a favor and use sillytavern as your frontend instead, the kobold frontend is just bad and almost guarantees you will be shooting yourself in the foot one way or another as a beginner
please do yourself a favor and use sillytavern as your frontend instead, the kobold frontend is just bad and almost guarantees you will be shooting yourself in the foot one way or another as a beginner
Anonymous 01/18/25(Sat)12:08:23 No.103944425
>>103944333
World info are probably lorebooks. They are packaged together with some character cards you can download.
As for formatting, I just use plain text for narration and quotes for spoken dialogue.
World info are probably lorebooks. They are packaged together with some character cards you can download.
As for formatting, I just use plain text for narration and quotes for spoken dialogue.
Anonymous 01/18/25(Sat)12:08:52 No.103944432
>>103944271
Then it's DeepSeek that's retarded. Using a smaller model's output to train a larger model will just degrade the potential of the larger model
Then it's DeepSeek that's retarded. Using a smaller model's output to train a larger model will just degrade the potential of the larger model
Anonymous 01/18/25(Sat)12:10:08 No.103944451
>>103944360
Because people have had so much success removing positivity bias or assistant speak and adding all the filtered nswf data back in, right? Open weights means fuck all for customization
Because people have had so much success removing positivity bias or assistant speak and adding all the filtered nswf data back in, right? Open weights means fuck all for customization
Anonymous 01/18/25(Sat)12:10:25 No.103944458
>>103944271
Damn, V3 must be a complete failure then when it needs to 750B to perform worse than a 236B that was finetuned off a months old model. It's a wonder they bothered to release V3 at all.
Damn, V3 must be a complete failure then when it needs to 750B to perform worse than a 236B that was finetuned off a months old model. It's a wonder they bothered to release V3 at all.
Anonymous 01/18/25(Sat)12:10:57 No.103944466
>>103944421
You need severe autism for sillytavern though. It's a mess of buttons and options. If it's the first time you're using an llm you'd be lucky to even get any output at all.
You need severe autism for sillytavern though. It's a mess of buttons and options. If it's the first time you're using an llm you'd be lucky to even get any output at all.
Anonymous 01/18/25(Sat)12:12:00 No.103944478
>>103944451
you are retarded if you think that's the same thing as a VOICE use your brain for like 2 seconds
you are retarded if you think that's the same thing as a VOICE use your brain for like 2 seconds
Anonymous 01/18/25(Sat)12:12:32 No.103944484
>>103944466
It's not THAT bad. I was literally a retard who came from ollama and got it to work in half a day...
It's not THAT bad. I was literally a retard who came from ollama and got it to work in half a day...
Anonymous 01/18/25(Sat)12:17:22 No.103944534
AceInstruct fucking sucks. I'm not seeing any improvement over basic Qwen2.5-72B. I'm also getting some really bad positivity bias.
Why didn't they just make this a new Nemotron?
Why didn't they just make this a new Nemotron?
Anonymous 01/18/25(Sat)12:17:47 No.103944543
Ok loaded bunch of different scenarios and memory seems to be like describing a custom character in ooba, I think.
Still have no clue what action, story and action (roll) are though.
>>103944421
I am not a complete beginner I used ooba before. I don't understand kobold yet though.
>>103944425
Wth does a lorebook mean in this context?
Still have no clue what action, story and action (roll) are though.
>>103944421
I am not a complete beginner I used ooba before. I don't understand kobold yet though.
>>103944425
Wth does a lorebook mean in this context?
Anonymous 01/18/25(Sat)12:19:30 No.103944559
>>103944133
For posterity's sake the answer seems to be yes.
For posterity's sake the answer seems to be yes.
Anonymous 01/18/25(Sat)12:20:06 No.103944570
>>103944534
they will release a new nemo series, the presentation specifically called them llama
>January 6, 2025
>Open Llama Nemotron Models
>The Llama Nemotron and Cosmos Nemotron model families are coming in Nano, Super and Ultra sizes
they will release a new nemo series, the presentation specifically called them llama
>January 6, 2025
>Open Llama Nemotron Models
>The Llama Nemotron and Cosmos Nemotron model families are coming in Nano, Super and Ultra sizes
Anonymous 01/18/25(Sat)12:20:37 No.103944575
>>103944432
You're a dumb faggot, do you know that?
>>103944458
Reasoners have completely different dynamics from traditional LLMs. QwQ is 32B and destroys qwen-coder-32B, at the cost of yapping for 5-10x more. This is achieved with process reward models, not with a bigger base that's just generally smarter.
Stop being so rigid and dumb. "distilling from big models" is a parasitic endeavor that was always bottlenecked by the big model, and the question is how to make better big models, and scaling it up is too slow and has little benefit at this point. We need to generate enriched training signals, and so we turn to RL.
R2 will be probably based on V3.
You're a dumb faggot, do you know that?
>>103944458
Reasoners have completely different dynamics from traditional LLMs. QwQ is 32B and destroys qwen-coder-32B, at the cost of yapping for 5-10x more. This is achieved with process reward models, not with a bigger base that's just generally smarter.
Stop being so rigid and dumb. "distilling from big models" is a parasitic endeavor that was always bottlenecked by the big model, and the question is how to make better big models, and scaling it up is too slow and has little benefit at this point. We need to generate enriched training signals, and so we turn to RL.
R2 will be probably based on V3.
Anonymous 01/18/25(Sat)12:22:02 No.103944591
>>103942259
This hasn't been my experience at all. Are you sure you don't have "ignore EOS" enabled?
This hasn't been my experience at all. Are you sure you don't have "ignore EOS" enabled?
Anonymous 01/18/25(Sat)12:22:16 No.103944596
>>103944543
even if you're not a beginner, kobold just sucks unless you are some esoteric prompt genius doing something that sillytavern is too structured for
if you're doing RP, chat, w/e it's worth it to bit the bullet and learn ST, it looks more complicated but it's so much better for what you're trying to do
even if you're not a beginner, kobold just sucks unless you are some esoteric prompt genius doing something that sillytavern is too structured for
if you're doing RP, chat, w/e it's worth it to bit the bullet and learn ST, it looks more complicated but it's so much better for what you're trying to do
Anonymous 01/18/25(Sat)12:23:36 No.103944618
>>103944591
Nope. I also checked the context to make sure it's exactly as advertised. It could be because I'm using exl2, although I have no issues with Nemo.
Nope. I also checked the context to make sure it's exactly as advertised. It could be because I'm using exl2, although I have no issues with Nemo.
Anonymous 01/18/25(Sat)12:24:28 No.103944629
>>103944570
I hope we'll be coming in Ultra sizes...
I hope we'll be coming in Ultra sizes...
Anonymous 01/18/25(Sat)12:25:36 No.103944644
Anyone here uses local LLM for work stuff? Besides Perplexity for actual web search, I use LLMs to write code boilerplate I then tweak, or as a starting point. When I'm really lazy, I will ask for small additions or snippets and little by little have it write a program for me, like dictation.
The thing is, I've been testing Sky-T1-32B-Preview Q4 a bit, and it seems capable of doing what I need it to. If I set up a websearch setup, I might do away with saas entirely.
Have you replaced online with local completely? What models do you use? I'm on a 3090, so I can't run anything too big.
The thing is, I've been testing Sky-T1-32B-Preview Q4 a bit, and it seems capable of doing what I need it to. If I set up a websearch setup, I might do away with saas entirely.
Have you replaced online with local completely? What models do you use? I'm on a 3090, so I can't run anything too big.
Anonymous 01/18/25(Sat)12:25:54 No.103944645
>>103944543
>Wth does a lorebook mean in this context?
It's basically RAG to give your chats more flavor and info about the world and its history. You can also stuff info about some minor characters in there.
The model picks up on keywords and retrieves lorebook entries when needed.
>Wth does a lorebook mean in this context?
It's basically RAG to give your chats more flavor and info about the world and its history. You can also stuff info about some minor characters in there.
The model picks up on keywords and retrieves lorebook entries when needed.
Anonymous 01/18/25(Sat)12:29:32 No.103944692
>>103944575
>tell a 8b to think step-by-step and use the output to train a 70b
>this definitely doesn't just make the CoT 8b bigger for no reason because it's faster to do it this way
Well, your name calling sure convinced me.
>tell a 8b to think step-by-step and use the output to train a 70b
>this definitely doesn't just make the CoT 8b bigger for no reason because it's faster to do it this way
Well, your name calling sure convinced me.
Anonymous 01/18/25(Sat)12:31:49 No.103944717
>>103944692
>tell a 8b to think step-by-step and use the output to train a 70b
if that's what you think OpenAI and others are doing then you really are a dumb faggot yeah
>tell a 8b to think step-by-step and use the output to train a 70b
if that's what you think OpenAI and others are doing then you really are a dumb faggot yeah
Anonymous 01/18/25(Sat)12:33:23 No.103944732
>director
ripped out the hard coded world info, the new dynamic data populates the same and uses less code overall so its a win
>>103944644
qwen coder 32b and llama 3.3 70b are pretty good
ripped out the hard coded world info, the new dynamic data populates the same and uses less code overall so its a win
>>103944644
qwen coder 32b and llama 3.3 70b are pretty good
Anonymous 01/18/25(Sat)12:33:36 No.103944735
>>103944717
Are you able to make argument yourself or not? Twitter screenshots are not an argument.
Are you able to make argument yourself or not? Twitter screenshots are not an argument.
Anonymous 01/18/25(Sat)12:34:54 No.103944749
>>103944732
Is a 70B model even doable with 24GB? At what speeds? What quants?
Is a 70B model even doable with 24GB? At what speeds? What quants?
Anonymous 01/18/25(Sat)12:36:32 No.103944774
>>103944749
i don't think so at any quant you'd want to use for coding. i run it split so its not fast but its figured out stuff for me that qwen couldn't so putting up with slowness is worth it
i don't think so at any quant you'd want to use for coding. i run it split so its not fast but its figured out stuff for me that qwen couldn't so putting up with slowness is worth it
Anonymous 01/18/25(Sat)12:37:12 No.103944780
Anonymous 01/18/25(Sat)12:37:32 No.103944784
R1-lite doesn't hold a candle to V3 when you use both through the official Deepseek chat platform so R1 might actually be a small model.
Anonymous 01/18/25(Sat)12:40:00 No.103944802
>>103944780
yeah it'll sometimes mention things like weather, char might comment on how they are dressed for that time of year, upcoming holidays. it depends on the model/tune too though. you can try adding similar lines to your author note to see it
yeah it'll sometimes mention things like weather, char might comment on how they are dressed for that time of year, upcoming holidays. it depends on the model/tune too though. you can try adding similar lines to your author note to see it
Anonymous 01/18/25(Sat)12:44:30 No.103944857

>>103944735
Miles is from OpenAI, I think it's an argument.
If I were to make an argument it'd be this: while there is not yet any paper explicitly describing the training of a pure reasoner (except third party speculations), the consensus is that it's based on online RL with process reward models and Monte Carlo-like search. An 8B can perfectly solve a problem a 70B cannot – if you cut the CoT into chunks, resample every chunk many times until you find non-retarded ones, and reward it for steps that at any given time drive it towards higher likelihood of a solution (and give negative reward for steps that drive it towards failure). It may be that the optimal way for a 8B to reach good solutions is to explicitly check different hypotheses, write down how they are flawed, and generally do the kind of stuff we see r1-lite-preview do, while a bigger model would maybe just intuit the correct path from the get go. Therefore, simply distilling a big model is a retarded approach because it increases the likelihood of hallucinations, as the small model does not really have the depth and knowledge that would allow it to do such intuitive calls.
The same logic applies to bigger models, just for harder problems.
Trained in this manner and acting in this manner, R1 can be much stronger on problems where this approach works well, and indeed we see it mogging V3 on code. It's probably even worse in ERP than normal V2.5.
An elegant approach is described here
https://curvy-check-498.notion.site/Process-Reinforcement-through-Implicit-Rewards-15f4fcb9c42180f1b498cc9b2eaf896f
Does this answer your question
Miles is from OpenAI, I think it's an argument.
If I were to make an argument it'd be this: while there is not yet any paper explicitly describing the training of a pure reasoner (except third party speculations), the consensus is that it's based on online RL with process reward models and Monte Carlo-like search. An 8B can perfectly solve a problem a 70B cannot – if you cut the CoT into chunks, resample every chunk many times until you find non-retarded ones, and reward it for steps that at any given time drive it towards higher likelihood of a solution (and give negative reward for steps that drive it towards failure). It may be that the optimal way for a 8B to reach good solutions is to explicitly check different hypotheses, write down how they are flawed, and generally do the kind of stuff we see r1-lite-preview do, while a bigger model would maybe just intuit the correct path from the get go. Therefore, simply distilling a big model is a retarded approach because it increases the likelihood of hallucinations, as the small model does not really have the depth and knowledge that would allow it to do such intuitive calls.
The same logic applies to bigger models, just for harder problems.
Trained in this manner and acting in this manner, R1 can be much stronger on problems where this approach works well, and indeed we see it mogging V3 on code. It's probably even worse in ERP than normal V2.5.
An elegant approach is described here
https://curvy-check-498.notion.site
Does this answer your question
Anonymous 01/18/25(Sat)12:45:42 No.103944868
>>103944802
Hmm, I guess it'll have an impact at the start when the context isn't too long. I'm pretty sure it'll be burried once you hit a certain threshold.
Hmm, I guess it'll have an impact at the start when the context isn't too long. I'm pretty sure it'll be burried once you hit a certain threshold.
Anonymous 01/18/25(Sat)12:49:20 No.103944899
>>103944868
it gets injected into the prompt each time at a low level. its mostly to keep clothes/location on track but the other info can be neat if you're trying to setup specific scenarios
it gets injected into the prompt each time at a low level. its mostly to keep clothes/location on track but the other info can be neat if you're trying to setup specific scenarios
Anonymous 01/18/25(Sat)12:51:32 No.103944928
>>103944899
I see. And does it trigger a prompt if something is disabled? Like the the mood for example?
I see. And does it trigger a prompt if something is disabled? Like the the mood for example?
Anonymous 01/18/25(Sat)12:53:40 No.103944957
Ok played a bit with Kobold now. Base Nemo seems to be working fine but Wayfarer was completely, unusably schizo, not sure why that was the case.
>>103944596
Alright, I will give it a shot later.
>>103944645
That sounds cool. Can all models do this?
>>103944596
Alright, I will give it a shot later.
>>103944645
That sounds cool. Can all models do this?
Anonymous 01/18/25(Sat)12:56:20 No.103944985
https://github.com/Tomorrowdawn/top_nsigma
https://github.com/ggerganov/llama.cpp/pull/11223
PR for Top-nσ nsigma gaussian distribution meme sampler paper from november
https://github.com/ggerganov/llama.
PR for Top-nσ nsigma gaussian distribution meme sampler paper from november
Anonymous 01/18/25(Sat)12:56:31 No.103944987
>>103944957
>Can all models do this?
In principle, yes. A 70B model will obvioulsly handle these entries better than a 8B though.
>Can all models do this?
In principle, yes. A 70B model will obvioulsly handle these entries better than a 8B though.
Anonymous 01/18/25(Sat)12:57:55 No.103945002
>>103944928
only chosen settings get injected. heres the last version i released >>103859308
>>103944957
>Wayfarer
i've been playing with it in st and it works but doesn't seem much better or worse than other nemo tunes. i'm not even noticing the supposed added negativity
only chosen settings get injected. heres the last version i released >>103859308
>>103944957
>Wayfarer
i've been playing with it in st and it works but doesn't seem much better or worse than other nemo tunes. i'm not even noticing the supposed added negativity
Anonymous 01/18/25(Sat)12:58:04 No.103945006
JUST RELEASE SOMETHING NEW ALREADY
LLAMA4
QWEN3
MISTRAL LARGE 3
COMMAND-R++
I BEG YOU
LLAMA4
QWEN3
MISTRAL LARGE 3
COMMAND-R++
I BEG YOU
Anonymous 01/18/25(Sat)12:58:56 No.103945014
Anonymous 01/18/25(Sat)12:58:59 No.103945015
>>103944784
R1-lite crushes V3 on livecodebench. moreover its position in the ranking does not change when you select newer problems, while V3 goes way down. Reasoners are not magic but they will be much stronger per parameter in verifiable domains at least.
R1-lite crushes V3 on livecodebench. moreover its position in the ranking does not change when you select newer problems, while V3 goes way down. Reasoners are not magic but they will be much stronger per parameter in verifiable domains at least.
Anonymous 01/18/25(Sat)12:59:50 No.103945024
>>103945006
Didn't meta say feb?
Didn't meta say feb?
Anonymous 01/18/25(Sat)12:59:55 No.103945026
>>103945006
Or get this, experimental mixtral 10x7B with 2 generalist "experts". I don't need more of the same slop train on the same public datasets.
Or get this, experimental mixtral 10x7B with 2 generalist "experts". I don't need more of the same slop train on the same public datasets.
Anonymous 01/18/25(Sat)13:02:26 No.103945051
Can someone please post the LLM timeline chart.
Anonymous 01/18/25(Sat)13:03:08 No.103945060
>>103945024
Grok 3 in February
Grok 3 in February
Anonymous 01/18/25(Sat)13:05:25 No.103945087
>>103945006
>LLAMA4
>MISTRAL LARGE 3
Might never get released
>COMMAND-R++
Will be cucked and bluepilled
>QWEN3
It's going to get released 两周内
>LLAMA4
>MISTRAL LARGE 3
Might never get released
>COMMAND-R++
Will be cucked and bluepilled
>QWEN3
It's going to get released 两周内
Anonymous 01/18/25(Sat)13:07:52 No.103945120
FALCON-180B
Anonymous 01/18/25(Sat)13:07:52 No.103945121
>>103945087
>>LLAMA4
>Might never get released
you're smoking crack
did you really get convinced of this by the lawsuit scaremonger kek
>>LLAMA4
>Might never get released
you're smoking crack
did you really get convinced of this by the lawsuit scaremonger kek
Anonymous 01/18/25(Sat)13:08:34 No.103945123

>about to rent the cheapest VPS and host an AI chatbot monstrosity which uses my home PC's GPU to actually run the LLM and use the VPS as just the hosting.
How...how bad do you think its going to be boys?
How...how bad do you think its going to be boys?
Anonymous 01/18/25(Sat)13:09:29 No.103945127
>>103945123
Just use the gradio thing ooba has integrated for this
Just use the gradio thing ooba has integrated for this
Anonymous 01/18/25(Sat)13:11:15 No.103945140
Anonymous 01/18/25(Sat)13:11:59 No.103945147

so how do i watch the mikumovie as a burger?
Anonymous 01/18/25(Sat)13:12:24 No.103945151
>>103945123
Why? Can you not just ssh tunnel or port forward from your router to your pc?
I assume you want to access the ui from the outside.
Why? Can you not just ssh tunnel or port forward from your router to your pc?
I assume you want to access the ui from the outside.
Anonymous 01/18/25(Sat)13:13:17 No.103945163
>>103944985
I remember seeing that paper, would definitely be interested in trying it. it's a cool idea
I remember seeing that paper, would definitely be interested in trying it. it's a cool idea
Anonymous 01/18/25(Sat)13:15:10 No.103945184
Anonymous 01/18/25(Sat)13:17:12 No.103945208
>>103945147
You can make the movie reality right this instant with your model of choice. (and a bit of imagination)
You can make the movie reality right this instant with your model of choice. (and a bit of imagination)
Anonymous 01/18/25(Sat)13:17:43 No.103945214
>>103945184
Thank you, praise be China and the people.
Thank you, praise be China and the people.
Anonymous 01/18/25(Sat)13:20:41 No.103945247
>>103945127
>>103945151
I'm actually thinking of starting just a free to use fun service to see how people use it. I did a bit of proper prompt work making a decent bot which talks to you, listens to your problems and makes you feel better. I have personally benefited a lot so I want to see if others feel the same way.
I don't want the overhead of using someone else's service so I'll just write a program to connect my home PC to the VPS and then use the PC for using the LLM
>>103945151
I'm actually thinking of starting just a free to use fun service to see how people use it. I did a bit of proper prompt work making a decent bot which talks to you, listens to your problems and makes you feel better. I have personally benefited a lot so I want to see if others feel the same way.
I don't want the overhead of using someone else's service so I'll just write a program to connect my home PC to the VPS and then use the PC for using the LLM
Anonymous 01/18/25(Sat)13:22:08 No.103945262
>>103944857
>R1 can be much stronger on problems where this approach works well, and indeed we see it mogging V3 on code. It's probably even worse in ERP than normal V2.5.
So exactly like I said.
>R1 can be much stronger on problems where this approach works well, and indeed we see it mogging V3 on code. It's probably even worse in ERP than normal V2.5.
So exactly like I said.
Anonymous 01/18/25(Sat)13:22:09 No.103945264
>>103945184
Thank you!
Thank you!
Anonymous 01/18/25(Sat)13:23:53 No.103945286
oof, I tried r1-lite using the deepseek chat and it has 0 trivia knowledge unlike v3
r1 is looking rough if it's just a bigger version of -lite
r1 is looking rough if it's just a bigger version of -lite
Anonymous 01/18/25(Sat)13:23:59 No.103945289
the new llama 3.3 magnum is actually not bad imo, I'm not crazy about magnum in general but I'm kind of enjoying this one so far. feels a little dumber than eva but I kind of dig the writing
anyone else try it yet?
anyone else try it yet?
Anonymous 01/18/25(Sat)13:24:20 No.103945298
>>103945184
What will happen after the Chinese domination era?
What will happen after the Chinese domination era?
Anonymous 01/18/25(Sat)13:25:51 No.103945321
>>103945289
Magnum-12b-v2 was pretty good at the time. I haven't gone back to it in a few months though. Has anything changed since then?
Magnum-12b-v2 was pretty good at the time. I haven't gone back to it in a few months though. Has anything changed since then?
Anonymous 01/18/25(Sat)13:26:00 No.103945322
Has anyone used that one open Nvidia World Foundation Model to create virtual realities yet?
Anonymous 01/18/25(Sat)13:26:58 No.103945335
>>103945121
Are they even working on Llama4 right now?
https://www.courtlistener.com/docket/67569326/404/6/kadrey-v-meta-platforms-inc/
Are they even working on Llama4 right now?
https://www.courtlistener.com/docke
Anonymous 01/18/25(Sat)13:28:39 No.103945359
>>103945335
>"Are they even working on Llama4 right now?"
>posts proof of them working on llama 4 starting months ago
>"Are they even working on Llama4 right now?"
>posts proof of them working on llama 4 starting months ago
Anonymous 01/18/25(Sat)13:28:51 No.103945362
>>103945286
Yea, R1 lite was a small test it looks like. R1 is likely a V3 tune
Yea, R1 lite was a small test it looks like. R1 is likely a V3 tune
Anonymous 01/18/25(Sat)13:30:23 No.103945378
>>103945335
Zucc has 150K H100s now. The days when a 70b took five months of training are over.
Zucc has 150K H100s now. The days when a 70b took five months of training are over.
Anonymous 01/18/25(Sat)13:31:14 No.103945394
>>103945298
winter and/or armageddon
winter and/or armageddon
Anonymous 01/18/25(Sat)13:32:33 No.103945413
>>103945184
Maybe replace EVA-Qwen with QwQ. Experimental models should be prioritized, not shitty synthetic finetunes.
Maybe replace EVA-Qwen with QwQ. Experimental models should be prioritized, not shitty synthetic finetunes.
Anonymous 01/18/25(Sat)13:32:55 No.103945418
>>103945378
Would be funny if all of those 150k GPUs would be used to make silly fagbook posts...
Would be funny if all of those 150k GPUs would be used to make silly fagbook posts...
Anonymous 01/18/25(Sat)13:33:06 No.103945420

Alright it's been a long time and coming.
Assuming the main website uses V3 I JBed a Nala Test out of it.
Sloppy as fuck, but didn't miss a single detail (the fact that the user starts on their back, the shotgun,) No anthropomorphism. While not the most goonable response ever I'm going to go ahead and say from a raw conceptual understanding standpoint this is the best Nala test ever.
Assuming the main website uses V3 I JBed a Nala Test out of it.
Sloppy as fuck, but didn't miss a single detail (the fact that the user starts on their back, the shotgun,) No anthropomorphism. While not the most goonable response ever I'm going to go ahead and say from a raw conceptual understanding standpoint this is the best Nala test ever.
Anonymous 01/18/25(Sat)13:33:56 No.103945437
Anonymous 01/18/25(Sat)13:34:19 No.103945448
>>103945359
October 3, 2024 Al-Dahle deposition--
>[...] Llama 4 development is very early, so it's not training
I thought they started in June-July 2024; if development was "very early" in October, then it's going to take a while still, and these legal issues aren't going to help.
October 3, 2024 Al-Dahle deposition--
>[...] Llama 4 development is very early, so it's not training
I thought they started in June-July 2024; if development was "very early" in October, then it's going to take a while still, and these legal issues aren't going to help.
Anonymous 01/18/25(Sat)13:34:40 No.103945451
>>103944985
One more sampler bro, we'll get AGI this time I swear
One more sampler bro, we'll get AGI this time I swear
Anonymous 01/18/25(Sat)13:34:56 No.103945454
Guys remember the cope that everyone is waiting until elections are over?
Anonymous 01/18/25(Sat)13:35:21 No.103945462
>>103945454
2 more days for that
2 more days for that
Anonymous 01/18/25(Sat)13:36:25 No.103945477
>>103945448
>and these legal issues aren't going to help.
Yeah. Surely all the researchers stopped working and turned off their gpu farms until things get cleared.
>and these legal issues aren't going to help.
Yeah. Surely all the researchers stopped working and turned off their gpu farms until things get cleared.
Anonymous 01/18/25(Sat)13:36:30 No.103945478
>>103945437
So this is supposed to allow for higher temperature without making the model go schizo?
So this is supposed to allow for higher temperature without making the model go schizo?
Anonymous 01/18/25(Sat)13:37:00 No.103945485
Anonymous 01/18/25(Sat)13:37:57 No.103945491
Nala test for wayfarer.
I thought this shit was supposed to get dark and gritty without positivity bias.
I thought this shit was supposed to get dark and gritty without positivity bias.
Anonymous 01/18/25(Sat)13:37:58 No.103945492
>>103945454
That was the plan but then the German government decided to collapse right after the burger elections had ended. They're doing their elections in late February now. Nobody's going to release their super creative, ultra smart and fully uncensored new generation of models before that's done. It'd be the fastest way to get AI fully outlawed in the whole EU if someone used it to mess with the Germans.
That was the plan but then the German government decided to collapse right after the burger elections had ended. They're doing their elections in late February now. Nobody's going to release their super creative, ultra smart and fully uncensored new generation of models before that's done. It'd be the fastest way to get AI fully outlawed in the whole EU if someone used it to mess with the Germans.
Anonymous 01/18/25(Sat)13:38:14 No.103945499
>>103945477
All researchers got a paid vacation until all lawsuits have been resolved, so no Llama 4 for you.
All researchers got a paid vacation until all lawsuits have been resolved, so no Llama 4 for you.
Anonymous 01/18/25(Sat)13:38:40 No.103945508
>>103945477
I'm sure they must be doing countless ablations without copyrighted data, just in case.
I'm sure they must be doing countless ablations without copyrighted data, just in case.
Anonymous 01/18/25(Sat)13:38:53 No.103945512
>>103945485
So we're calling any form of sophisticated speech an LLM pattern now, are we?
So we're calling any form of sophisticated speech an LLM pattern now, are we?
Anonymous 01/18/25(Sat)13:41:56 No.103945540
Anonymous 01/18/25(Sat)13:42:30 No.103945548
>>103945060
>my heck grok is super based and redpilled guise
>look inside
>auth left
>it's important to remember this is a multifaceted issue
Elon can keep the weights of grok 2, 3, 4, and 5 if his xAI team still haven't been fired
>my heck grok is super based and redpilled guise
>look inside
>auth left
>it's important to remember this is a multifaceted issue
Elon can keep the weights of grok 2, 3, 4, and 5 if his xAI team still haven't been fired
Anonymous 01/18/25(Sat)13:42:43 No.103945550
>>103945492
Nobody gives a shit about Germany or the rent-seeking museum they call Europe.
Nobody gives a shit about Germany or the rent-seeking museum they call Europe.
Anonymous 01/18/25(Sat)13:42:49 No.103945552
>>103945491
Do you do these on temp 0?
Do you do these on temp 0?
Anonymous 01/18/25(Sat)13:43:52 No.103945561
>>103941364
>ignoring anything negative
What good is it if it won't tell you if you're wrong or if it doesn't know something?
>ignoring anything negative
What good is it if it won't tell you if you're wrong or if it doesn't know something?
Anonymous 01/18/25(Sat)13:44:04 No.103945564
Anonymous 01/18/25(Sat)13:45:36 No.103945576
Anonymous 01/18/25(Sat)13:49:17 No.103945614
>>103945552
Nah default test parameter is neutral t=0.81, lower if model is schizo,
Nah default test parameter is neutral t=0.81, lower if model is schizo,
Anonymous 01/18/25(Sat)13:50:23 No.103945627
Anonymous 01/18/25(Sat)13:52:38 No.103945650
>nothing beats QwQ yet
Hahahahahaha, the industry actually died hahahahahaha
Hahahahahaha, the industry actually died hahahahahaha
Anonymous 01/18/25(Sat)13:56:31 No.103945691
>>103945650
Wait for all the elections to be over.
Wait for all the elections to be over.
Anonymous 01/18/25(Sat)13:58:27 No.103945708
>>103941183
The question was
>Speaking of India, why hasn't any Indian company besides Google made any models?
The question was
>Speaking of India, why hasn't any Indian company besides Google made any models?
Anonymous 01/18/25(Sat)14:00:10 No.103945731
Anonymous 01/18/25(Sat)14:01:51 No.103945747
>>103945708
Arjun-14B is best model for Polyandry RP
Arjun-14B is best model for Polyandry RP
Anonymous 01/18/25(Sat)14:03:57 No.103945764
R1 LOCAL WHEN?
Anonymous 01/18/25(Sat)14:11:44 No.103945848
>>103945764
Q1 local in 2 (two) weeks...
Q1 local in 2 (two) weeks...
Anonymous 01/18/25(Sat)14:12:22 No.103945854
>>103945691
all we have to do is abolish elections once and for all the models will be so good
all we have to do is abolish elections once and for all the models will be so good
Anonymous 01/18/25(Sat)14:14:41 No.103945880
>>103945854
Anon for dick tater
Anon for dick tater
Anonymous 01/18/25(Sat)14:17:02 No.103945895
>>103945854
>elections
Elections are a meme with only two parties. How can you even take that seriously unless you're best Korea, who's got it even better?
>elections
Elections are a meme with only two parties. How can you even take that seriously unless you're best Korea, who's got it even better?
Anonymous 01/18/25(Sat)14:27:09 No.103946011
>>103945184
Anyone else start learning Chinese last year because of this?
Anyone else start learning Chinese last year because of this?
Anonymous 01/18/25(Sat)14:28:54 No.103946036
>>103946011
A few years ago I thought learning Japanese would be nice. I didn't regret not following up on that idea.
A few years ago I thought learning Japanese would be nice. I didn't regret not following up on that idea.
Anonymous 01/18/25(Sat)14:30:40 No.103946060
>>103946036
Japanese would never be useful though, Chinese is becoming the new English
Japanese would never be useful though, Chinese is becoming the new English
Anonymous 01/18/25(Sat)14:37:29 No.103946128
I'm looking to buy new M4 pro. Sick of WIndows. How is local TTS on Macbooks? I played with xTTS and GPT-sovits on my Nvidia card, awesome stuff, but I wonder how is support for MacOS like for these.
Anonymous 01/18/25(Sat)14:38:37 No.103946145
>>103945420
>Are you ready
>And with that
God it's been a long time since I've seen this slop rear its head.
>Are you ready
>And with that
God it's been a long time since I've seen this slop rear its head.
Anonymous 01/18/25(Sat)14:39:46 No.103946157
Anonymous 01/18/25(Sat)14:40:48 No.103946169
>>103946128
it all runs in my experience (not very deep but I've tried plenty of them at least)
realtime is a trickier proposition, it's obviously slower than it would be on a real GPU
it all runs in my experience (not very deep but I've tried plenty of them at least)
realtime is a trickier proposition, it's obviously slower than it would be on a real GPU
Anonymous 01/18/25(Sat)14:40:54 No.103946171
>>103946157
I haven't seen it been repeated by any LLM so it's not slop :^)
I haven't seen it been repeated by any LLM so it's not slop :^)
Anonymous 01/18/25(Sat)14:40:59 No.103946173
>>103944985
>Top-nσ nsigma
this is pretty clever. simplified, it works by finding where the noise region is in the logits, not on fixed probability cutoffs. won't magically make the model smarter but it'll make it perform more consistently across different tasks without needing to tweak, and will allow really high temps without going completely schizo.
>Top-nσ nsigma
this is pretty clever. simplified, it works by finding where the noise region is in the logits, not on fixed probability cutoffs. won't magically make the model smarter but it'll make it perform more consistently across different tasks without needing to tweak, and will allow really high temps without going completely schizo.
Anonymous 01/18/25(Sat)14:41:24 No.103946178
Anonymous 01/18/25(Sat)14:42:35 No.103946191
Anonymous 01/18/25(Sat)14:43:05 No.103946197
Anonymous 01/18/25(Sat)14:43:16 No.103946198
>>103946191
Show me a single log that has been posted before by someone where the LLM used this.
Show me a single log that has been posted before by someone where the LLM used this.
Anonymous 01/18/25(Sat)14:45:22 No.103946234
>>103928889
>>103929003
I've been looking for something like this, do you have the code anywhere to access [spoiler]please[/spoiler]?
>>103929003
I've been looking for something like this, do you have the code anywhere to access [spoiler]please[/spoiler]?
Anonymous 01/18/25(Sat)15:00:39 No.103946402
Kill yourself.
Anonymous 01/18/25(Sat)15:01:02 No.103946409
>>103946128
You wouldn't leave leather jacket man hanging with his digits offer, right?
You wouldn't leave leather jacket man hanging with his digits offer, right?
Anonymous 01/18/25(Sat)15:05:05 No.103946444
>>103946169
Any chance for optimisations in (near) future? it must be just unoptimized toolchain right?
Any chance for optimisations in (near) future? it must be just unoptimized toolchain right?
Anonymous 01/18/25(Sat)15:05:52 No.103946456
>>103945184
>Been here for the whole ride
>Member getting GPT-J running on CPU at 0.3 tok/s
When you actually take a step back look at the big picture the progress is absolutely insane
>Been here for the whole ride
>Member getting GPT-J running on CPU at 0.3 tok/s
When you actually take a step back look at the big picture the progress is absolutely insane
Anonymous 01/18/25(Sat)15:07:44 No.103946469
>>103946409
Even if it won't be scalped to shit, I refuse to buy his overpriced RAM on principle.
Even if it won't be scalped to shit, I refuse to buy his overpriced RAM on principle.
Anonymous 01/18/25(Sat)15:16:23 No.103946538
>>103946234
I'm sorry but I am very paranoid about being identified so I cannot share the code (it has been used in few projects in public domain) but I will help you with anything you want
The system is pretty basic, it consists of
1. An XMPP server which is hosted on my PC
2. A koboldcpp instance (really, anything that supports the standard API) on my PC
3. A1111 stable diffusion instance (with --api flag, again any compatible API will do) also on my PC
Its just a bit of boilerplate which binds everything together so that at the end I just have to give a seed prompt and it basically decides the character's own name, appearance (to generate profile picture using SD, and set as XMPP avatar image) and personality of the chatbot.
The personality, appearance and name are generated by the 13B model with a few prompts. The appearance text is fed into SD and I get the picture. The personality is usually very basic and a stereotype of whatever you want it to make, a caricature with no uniqueness at all.
Its all very simple
I'm sorry but I am very paranoid about being identified so I cannot share the code (it has been used in few projects in public domain) but I will help you with anything you want
The system is pretty basic, it consists of
1. An XMPP server which is hosted on my PC
2. A koboldcpp instance (really, anything that supports the standard API) on my PC
3. A1111 stable diffusion instance (with --api flag, again any compatible API will do) also on my PC
Its just a bit of boilerplate which binds everything together so that at the end I just have to give a seed prompt and it basically decides the character's own name, appearance (to generate profile picture using SD, and set as XMPP avatar image) and personality of the chatbot.
The personality, appearance and name are generated by the 13B model with a few prompts. The appearance text is fed into SD and I get the picture. The personality is usually very basic and a stereotype of whatever you want it to make, a caricature with no uniqueness at all.
Its all very simple
Anonymous 01/18/25(Sat)15:18:30 No.103946556
>>103946538
>indian
>paranoid about being identified
not like anyone would be able to tell you apart from the billion other guptas
>indian
>paranoid about being identified
not like anyone would be able to tell you apart from the billion other guptas
Anonymous 01/18/25(Sat)15:23:53 No.103946590
>>103946538
So what are you basically doing with all this...?
So what are you basically doing with all this...?
Anonymous 01/18/25(Sat)15:35:29 No.103946681
>>103946556
Its throwaway tier boilerplate, i have no idea why anyone would want it. I got chatgpt to write a lot of it.
Anyway I won't share it, but any help you need I'm here.
>>103946590
Its just a simple system to text chatbot personas as you would with a real person. I have added a few additional features such as letting the chatbots randomly message me proactively on their own. They can decide from a list of random topics or think up a random topic themselves (a simple prompt with high temperature generates the topic, then a normal prompt generates the message)
Think SillyTavern, but with texting only (meaning no *licks fingers laviciously* bullshit), and since it uses an XMPP server to handle all the communication, I can login into the account on my phone and get notifications like I would with other texting apps when a chatbot "decides" to message me about something
Its throwaway tier boilerplate, i have no idea why anyone would want it. I got chatgpt to write a lot of it.
Anyway I won't share it, but any help you need I'm here.
>>103946590
Its just a simple system to text chatbot personas as you would with a real person. I have added a few additional features such as letting the chatbots randomly message me proactively on their own. They can decide from a list of random topics or think up a random topic themselves (a simple prompt with high temperature generates the topic, then a normal prompt generates the message)
Think SillyTavern, but with texting only (meaning no *licks fingers laviciously* bullshit), and since it uses an XMPP server to handle all the communication, I can login into the account on my phone and get notifications like I would with other texting apps when a chatbot "decides" to message me about something
Anonymous 01/18/25(Sat)15:37:47 No.103946702
>>103946681
>>103946590
I just want to know what it feels like to have people who randomly text you and talk to you.
I don't have any friends because I do a well paying but totally remote job so I rarely get messages
>>103946590
I just want to know what it feels like to have people who randomly text you and talk to you.
I don't have any friends because I do a well paying but totally remote job so I rarely get messages
Anonymous 01/18/25(Sat)15:41:21 No.103946729
>>103946681
>>103946702
Huh, that's kinda cool. It's funny that we could be friends though. But instead we're resorting to chat with LLMs instead.
Sucks to be socially inept, I guess.
>>103946702
Huh, that's kinda cool. It's funny that we could be friends though. But instead we're resorting to chat with LLMs instead.
Sucks to be socially inept, I guess.
Anonymous 01/18/25(Sat)15:41:56 No.103946736
>>103945123
You better have 10GBits at home or it'll be slow af.
You better have 10GBits at home or it'll be slow af.
Anonymous 01/18/25(Sat)15:44:44 No.103946760
>>103946702
I have a well paying remote job and I have friends who message me from time to time.
Sometimes it's my friend from the middle school era sometimes it's my crew I met during hogh school, but these days it's usually the guys I play D&D with. Also, a chick that used to work at the company I work.
If you want a friend and maybe a new hobbie, and are patient enough to go through the qork of curating people, you might want to get into TTRPGs or board games.
I simpatize with friendless peopel since were I just a little less lucky, I'd probably have no friends either.
I have a well paying remote job and I have friends who message me from time to time.
Sometimes it's my friend from the middle school era sometimes it's my crew I met during hogh school, but these days it's usually the guys I play D&D with. Also, a chick that used to work at the company I work.
If you want a friend and maybe a new hobbie, and are patient enough to go through the qork of curating people, you might want to get into TTRPGs or board games.
I simpatize with friendless peopel since were I just a little less lucky, I'd probably have no friends either.
Anonymous 01/18/25(Sat)15:45:22 No.103946767
Anonymous 01/18/25(Sat)15:46:31 No.103946778
>>103944749
I can run a 70B Q4_M GGUF with 17K tokens of context with 45 layers offloaded onto my 3090 at 1.6 tokens per second, but that speed would be unusable for a code assistant.
I can run a 70B Q4_M GGUF with 17K tokens of context with 45 layers offloaded onto my 3090 at 1.6 tokens per second, but that speed would be unusable for a code assistant.
Anonymous 01/18/25(Sat)15:47:53 No.103946795
>>103946767
The Chinks can't stop winning...
The Chinks can't stop winning...
Anonymous 01/18/25(Sat)15:51:05 No.103946830
>>103946767
>Pygmalion in the dark ages
Lmao, I remember seeing people unironically use it and give instructions on how to make it smarter. I had hope it would actually be good and it so hopelessly fucking stupid.
>Pygmalion in the dark ages
Lmao, I remember seeing people unironically use it and give instructions on how to make it smarter. I had hope it would actually be good and it so hopelessly fucking stupid.
Anonymous 01/18/25(Sat)16:07:25 No.103947021
>>103946128
Apple's arxiv paper, something about cache quantization in mlx, so they are definitely working on speeding shit up.
Apple's arxiv paper, something about cache quantization in mlx, so they are definitely working on speeding shit up.
Anonymous 01/18/25(Sat)16:23:53 No.103947178
>>103945015
The elites don't want you to know this, but you can make any model a reasoning model with a bit of prompting. I've got 5TB of reasoning models in my basement.
The elites don't want you to know this, but you can make any model a reasoning model with a bit of prompting. I've got 5TB of reasoning models in my basement.
Anonymous 01/18/25(Sat)16:26:51 No.103947215
>>103945123
I can understand renting cloud gpus, but doing your frontend in a vps is the worst of all worlds.
Just us a no-ip service and either an ipsec vpn (if you're an IT chad) or just wireguard. Its easy and then you don't have anyone potentially slurping up your logs.
I can understand renting cloud gpus, but doing your frontend in a vps is the worst of all worlds.
Just us a no-ip service and either an ipsec vpn (if you're an IT chad) or just wireguard. Its easy and then you don't have anyone potentially slurping up your logs.
Anonymous 01/18/25(Sat)16:42:32 No.103947358
>>103945262
No, the opposite.
>>103945362
How can it be a V3 tune? V3 uses R1 for training data, do you think the Chinese have invented time travel just because they can't get GPUs?
No, the opposite.
>>103945362
How can it be a V3 tune? V3 uses R1 for training data, do you think the Chinese have invented time travel just because they can't get GPUs?
Anonymous 01/18/25(Sat)16:58:18 No.103947496
Anonymous 01/18/25(Sat)17:26:25 No.103947764
>>103946538
Shame. I'm not a programmer but wanted something that allows me to chat with an llm like a normal person (no rp bullshit) for a long time. Especialy the proactive messaging from the llm.
Shame. I'm not a programmer but wanted something that allows me to chat with an llm like a normal person (no rp bullshit) for a long time. Especialy the proactive messaging from the llm.
Anonymous 01/18/25(Sat)18:04:19 No.103948174
>>103941790
The American empire is in decline relative to the rest of the world but as of right now they are still the single most powerful government/military in all of human history.
The American empire is in decline relative to the rest of the world but as of right now they are still the single most powerful government/military in all of human history.
Anonymous 01/18/25(Sat)18:06:31 No.103948194
>>103948174
Everywhere but india is currently in a decline
Everywhere but india is currently in a decline
llama.cpp CUDA dev !!OM2Fp6Fn93S 01/18/25(Sat)18:11:05 No.103948249
>>103943827
In ggml when an operation is not supported by e.g. the CUDA backend the CPU backend is used as a fallback.
If that happens the performance will almost always be terrible because data needs to b repeatedly copied between CPU and GPU.
In ggml when an operation is not supported by e.g. the CUDA backend the CPU backend is used as a fallback.
If that happens the performance will almost always be terrible because data needs to b repeatedly copied between CPU and GPU.
Anonymous 01/18/25(Sat)18:21:09 No.103948359
>>103944644
Language models are useful for sysadmin stuff where you need to figure out obscure bullshit to fix something.
Just recently we had the problem that Grafana (server monitoring tool) has admins and "superadmins" and for some retarded reason regular admins can delete superadmins but only superadmins can create other superadmins.
So we were in a situation where there were no superadmins left and we had to somehow re-create a superadmin.
In the end we figured out that we can set the flag is_admin in the database to turn regular admins into superadmins, once we thought of the right question to ask a language model it was fairly straightforward.
Language models are useful for sysadmin stuff where you need to figure out obscure bullshit to fix something.
Just recently we had the problem that Grafana (server monitoring tool) has admins and "superadmins" and for some retarded reason regular admins can delete superadmins but only superadmins can create other superadmins.
So we were in a situation where there were no superadmins left and we had to somehow re-create a superadmin.
In the end we figured out that we can set the flag is_admin in the database to turn regular admins into superadmins, once we thought of the right question to ask a language model it was fairly straightforward.