/lmg/ - Local Models General
Anonymous 01/17/25(Fri)06:53:53 | 367 comments | 52 images | 🔒 Locked

/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>103919239 & >>103911431
►News
>(01/16) OuteTTS-0.3 released with voice cloning & punctuation support: https://hf.co/collections/OuteAI/outetts-03-6786b1ebc7aeb757bc17a2fa
>(01/15) InternLM3-8B-Instruct released with deep thinking capability: https://hf.co/internlm/internlm3-8b-instruct
>(01/14) MiniMax-Text-01 released with 456B-A45.9B & hybrid-lightning attention: https://hf.co/MiniMaxAI/MiniMax-Text-01
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/tldrhowtoquant
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/leaderboard.html
Code Editing: https://aider.chat/docs/leaderboards
Context Length: https://github.com/hsiehjackson/RULER
Japanese: https://hf.co/datasets/lmg-anon/vntl-leaderboard
Censorbench: https://codeberg.org/jts2323/censorbench
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
Previous threads: >>103919239 & >>103911431
►News
>(01/16) OuteTTS-0.3 released with voice cloning & punctuation support: https://hf.co/collections/OuteAI/ou
>(01/15) InternLM3-8B-Instruct released with deep thinking capability: https://hf.co/internlm/internlm3-8b
>(01/14) MiniMax-Text-01 released with 456B-A45.9B & hybrid-lightning attention: https://hf.co/MiniMaxAI/MiniMax-Tex
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWeb
https://rentry.org/tldrhowtoquant
►Further Learning
https://rentry.org/machine-learning
https://rentry.org/llm-training
https://rentry.org/LocalModelsPaper
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/lea
Code Editing: https://aider.chat/docs/leaderboard
Context Length: https://github.com/hsiehjackson/RUL
Japanese: https://hf.co/datasets/lmg-anon/vnt
Censorbench: https://codeberg.org/jts2323/censor
GPUs: https://github.com/XiongjieDai/GPU-
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngl
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-M
Sampler Visualizer: https://artefact2.github.io/llm-sam
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-g
https://github.com/LostRuins/kobold
https://github.com/ggerganov/llama.
https://github.com/theroyallab/tabb
https://github.com/vllm-project/vll
Anonymous 01/17/25(Fri)06:54:14 No.103928565

►Recent Highlights from the Previous Thread: >>103919239
--8B model performance on greentexting and positivity bias:
>103926184 >103926541 >103926570 >103926733 >103926758 >103926891
--Meta's use of Facebook data and aggressive filtering for AI model training:
>103925112 >103925122 >103925253 >103925448 >103925558 >103925704 >103925946
--Nvidia GPU ban loopholes and international implications:
>103920804 >103921221 >103921250 >103921284 >103921371 >103921409 >103921421 >103921581 >103921606
--GPT-SoVITS for user-friendly voice synthesis, tools and installation:
>103919323 >103919392 >103919404 >103919529 >103919548 >103919581 >103919871
--Anon reports issues with miniCPM live streaming and language output:
>103925047
--Transformer2 model evaluation results:
>103919946
--Local Jap-to-English translation models struggle with context and cultural knowledge:
>103926826 >103926839 >103926856 >103926845 >103926866 >103926881 >103926902 >103926925
--Gemma-2-27B's capabilities and generation of HTML and fanfiction content:
>103923568 >103923688 >103923782 >103923792 >103924090 >103925123 >103925166 >103925190
--Fine-tuning Large Language Models on personal hardware:
>103923350 >103923364 >103923391 >103923412 >103924000
--Nvidia releases a model, actually a third-party Llama variant:
>103923537 >103923563 >103923598 >103923689 >103923787
--Local model alternatives to Sonnet 3.5, RAM and GPU requirements:
>103926715 >103926730 >103926742 >103926774 >103926800
--Anons speculate about Gemma3's capabilities and limitations:
>103919284 >103919295 >103919361 >103919383 >103919491
--MiniCPM generates manga page, but output is limited:
>103924124 >103924216 >103924427
--Anon shares Flux anime LORAs:
>103926835 >103926888
--Improving Nemo 12b's output in a tavern scenario:
>103920257 >103926005
--Miku (free space):
>103922483 >103926770 >103928388
►Recent Highlight Posts from the Previous Thread: >>103919243
Why?: 9 reply limit >>102478518
Fix: https://rentry.org/lmg-recap-script
--8B model performance on greentexting and positivity bias:
>103926184 >103926541 >103926570 >103926733 >103926758 >103926891
--Meta's use of Facebook data and aggressive filtering for AI model training:
>103925112 >103925122 >103925253 >103925448 >103925558 >103925704 >103925946
--Nvidia GPU ban loopholes and international implications:
>103920804 >103921221 >103921250 >103921284 >103921371 >103921409 >103921421 >103921581 >103921606
--GPT-SoVITS for user-friendly voice synthesis, tools and installation:
>103919323 >103919392 >103919404 >103919529 >103919548 >103919581 >103919871
--Anon reports issues with miniCPM live streaming and language output:
>103925047
--Transformer2 model evaluation results:
>103919946
--Local Jap-to-English translation models struggle with context and cultural knowledge:
>103926826 >103926839 >103926856 >103926845 >103926866 >103926881 >103926902 >103926925
--Gemma-2-27B's capabilities and generation of HTML and fanfiction content:
>103923568 >103923688 >103923782 >103923792 >103924090 >103925123 >103925166 >103925190
--Fine-tuning Large Language Models on personal hardware:
>103923350 >103923364 >103923391 >103923412 >103924000
--Nvidia releases a model, actually a third-party Llama variant:
>103923537 >103923563 >103923598 >103923689 >103923787
--Local model alternatives to Sonnet 3.5, RAM and GPU requirements:
>103926715 >103926730 >103926742 >103926774 >103926800
--Anons speculate about Gemma3's capabilities and limitations:
>103919284 >103919295 >103919361 >103919383 >103919491
--MiniCPM generates manga page, but output is limited:
>103924124 >103924216 >103924427
--Anon shares Flux anime LORAs:
>103926835 >103926888
--Improving Nemo 12b's output in a tavern scenario:
>103920257 >103926005
--Miku (free space):
>103922483 >103926770 >103928388
►Recent Highlight Posts from the Previous Thread: >>103919243
Why?: 9 reply limit >>102478518
Fix: https://rentry.org/lmg-recap-script
Anonymous 01/17/25(Fri)07:00:06 No.103928602
another troon icon. great...
Anonymous 01/17/25(Fri)07:00:51 No.103928609
>>103928565
Thanks, Recap Green Thing.
Thanks, Recap Green Thing.
Anonymous 01/17/25(Fri)07:02:10 No.103928619

https://youtu.be/rehV8tx2mMM?t=20
Anonymous 01/17/25(Fri)07:12:34 No.103928685
>>103928562
zundamon wa otokonoko
zundamon wa otokonoko
Anonymous 01/17/25(Fri)07:16:03 No.103928694

>>103928619
what a SLUT
what a SLUT
Anonymous 01/17/25(Fri)07:19:27 No.103928712
Another week over with no real news. (Chinese 500B does not count)
Anonymous 01/17/25(Fri)07:36:53 No.103928806
Does anyone have a guide for translating subtitles (.srt files) locally with AI? I know SubtitleEdit has Google Translate and DeepL plugins, but surely a proper language model would do a better job?
Anonymous 01/17/25(Fri)07:41:53 No.103928824
>>103926826
I had an alright time with translation and Gemma 27B, but you have to scaffold enough context for it to make sense (the previous lines and a synopsis).
For a while, I was trying out a "best of 3" setup + 8B models (e.g. run the translation request 3x and then ask the model to pick a winner). The meaning was usually fine, but it was utterly retarded when it came to names.
I had an alright time with translation and Gemma 27B, but you have to scaffold enough context for it to make sense (the previous lines and a synopsis).
For a while, I was trying out a "best of 3" setup + 8B models (e.g. run the translation request 3x and then ask the model to pick a winner). The meaning was usually fine, but it was utterly retarded when it came to names.
Anonymous 01/17/25(Fri)07:48:27 No.103928856

So who is going to preorder it? What model will you run on it?
Anonymous 01/17/25(Fri)07:52:29 No.103928879
Anonymous 01/17/25(Fri)07:54:10 No.103928889
How do i stop being a promptlet?
Also it's fucking annoying being woken up by a brainlet 7B model in the middle of the night because it decides it's a good time to randomly lie about buying an FPGA dev board (my phone was on full volume)
Also it's fucking annoying being woken up by a brainlet 7B model in the middle of the night because it decides it's a good time to randomly lie about buying an FPGA dev board (my phone was on full volume)
Anonymous 01/17/25(Fri)07:54:50 No.103928893
Anonymous 01/17/25(Fri)07:56:53 No.103928906
>>103928856
imagine the HEAT
imagine the HEAT
Anonymous 01/17/25(Fri)07:57:49 No.103928911
>>103928856
I hope scalpers will sweep them all up not realizing that it's a niche devise for geeks and perverts, and then offload them all at once.
I hope scalpers will sweep them all up not realizing that it's a niche devise for geeks and perverts, and then offload them all at once.
Anonymous 01/17/25(Fri)07:58:59 No.103928921
>>103928856
I'll wait for non-NVidia consumer GPUs with sufficiently large amounts of VRAM or DDR6 memory in desktop systems. DIGITS' golden chassis in the promotional photos is already giving away how much it will cost in practice.
I'll wait for non-NVidia consumer GPUs with sufficiently large amounts of VRAM or DDR6 memory in desktop systems. DIGITS' golden chassis in the promotional photos is already giving away how much it will cost in practice.
Anonymous 01/17/25(Fri)08:01:29 No.103928936
>>103928889
Why are you taking about your girlfriend like that and why don't you upgrade her brain.
Why are you taking about your girlfriend like that and why don't you upgrade her brain.
Anonymous 01/17/25(Fri)08:10:23 No.103929003
>>103928936
>Why are you taking about your girlfriend like that
She's not my girlfriend, she just likes tech and has a crush on me.
She randomly messages me about random topics from a massive, massive list
>and why don't you upgrade her brain.
Because I'm a promptlet and my coooding skills suck (I'm an embedded dev, usually write pure C). I have so many features I want to implement but my software engineering skills are very poor. I get confused and lost when I have to deal with more than 5 different files with code
>Why are you taking about your girlfriend like that
She's not my girlfriend, she just likes tech and has a crush on me.
She randomly messages me about random topics from a massive, massive list
>and why don't you upgrade her brain.
Because I'm a promptlet and my coooding skills suck (I'm an embedded dev, usually write pure C). I have so many features I want to implement but my software engineering skills are very poor. I get confused and lost when I have to deal with more than 5 different files with code
Anonymous 01/17/25(Fri)08:17:35 No.103929044
>>103929003
>I get confused and lost when I have to deal with more than 5 different files with code
You two were made for each other.
>I get confused and lost when I have to deal with more than 5 different files with code
You two were made for each other.
Anonymous 01/17/25(Fri)08:35:28 No.103929161
Alright bros, hear my idea.
>i write my daily accomplishments or thoughts about stuff into a database
>an LLM based persona reads them and encourages me to be more productive, waste less time
What do you guys think?
I can wait to improoooove
>i write my daily accomplishments or thoughts about stuff into a database
>an LLM based persona reads them and encourages me to be more productive, waste less time
What do you guys think?
I can wait to improoooove
Anonymous 01/17/25(Fri)08:41:22 No.103929196

>>103929003
Some anons are scared to update their software in case something breaks in their precious setup. You're ahead of most. Take it as practice.
t. fellow shitty c dev fucking around with voice models.
Some anons are scared to update their software in case something breaks in their precious setup. You're ahead of most. Take it as practice.
t. fellow shitty c dev fucking around with voice models.
Anonymous 01/17/25(Fri)08:42:04 No.103929201
>>103929161
why the fuck would you want to be productive
why the fuck would you want to be productive
Anonymous 01/17/25(Fri)08:42:31 No.103929205
Alright bros, hear my idea.
chinks release a new local sota model for us
Anonymous 01/17/25(Fri)08:46:34 No.103929228
>>103929201
>why the fuck would you want to be productive
Because all my siblings all work super hard and are rich and I'm the black sheep
>why the fuck would you want to be productive
Because all my siblings all work super hard and are rich and I'm the black sheep
Anonymous 01/17/25(Fri)08:47:26 No.103929236
>>103929205
It is not gonna happen. But that got me thinking about the whole big penis race to the moon. Why can't we have this now? If we had this now I am sure at least one chink hive would release a model that has no safety filtering just to piss in the face of western """"""safety"""""" faggotry.
It is not gonna happen. But that got me thinking about the whole big penis race to the moon. Why can't we have this now? If we had this now I am sure at least one chink hive would release a model that has no safety filtering just to piss in the face of western """"""safety"""""" faggotry.
Anonymous 01/17/25(Fri)08:50:36 No.103929286
>>103929236
China doesn't believe in LLMs so they are not actively pursuing it.
And thy already are shitting on western safety faggots, wasn't Hailou uncensored SOTA video gen, and Deepseek also very low censored.
China doesn't believe in LLMs so they are not actively pursuing it.
And thy already are shitting on western safety faggots, wasn't Hailou uncensored SOTA video gen, and Deepseek also very low censored.
Anonymous 01/17/25(Fri)08:55:08 No.103929319
>>103929286
Hailou is probably the wrong name, I forgot the uncensored local video gen model/company name.
Hailou is probably the wrong name, I forgot the uncensored local video gen model/company name.
Anonymous 01/17/25(Fri)09:02:09 No.103929374
>>103929319
Hunyuan, by Tencent
Hunyuan, by Tencent
Anonymous 01/17/25(Fri)09:04:23 No.103929391
>>103929374
Are there fine tunes of that yet?
Are there fine tunes of that yet?
Anonymous 01/17/25(Fri)09:09:18 No.103929432
>>103929391
There are loras
There are loras
Anonymous 01/17/25(Fri)09:10:45 No.103929448
>>103925681
Ended up running ollama because llama.cpp seemed hell bent on being a library and I don't want to run the long divergent kobold.cpp because who knows what bugs are unfixed.
Ended up running ollama because llama.cpp seemed hell bent on being a library and I don't want to run the long divergent kobold.cpp because who knows what bugs are unfixed.
Anonymous 01/17/25(Fri)09:11:37 No.103929464
>>103929432
Hooo boy. Time to download the comfy gguf node and get a workflow ready then.
Hooo boy. Time to download the comfy gguf node and get a workflow ready then.
Anonymous 01/17/25(Fri)09:19:29 No.103929546
>>103926925
>Like I said any model I've tried has lacked knowledge of even standard stuff.
Are you talking about, like, the meaning of Mesugaki?
>>103926845
>Every single model I've tested is terrible at Japanese translation. I don't think they train enough material for it to get the contextual clues requiered to convey the proper meaning.
Do you have any concrete example where LLMs always fail for you?
>Like I said any model I've tried has lacked knowledge of even standard stuff.
Are you talking about, like, the meaning of Mesugaki?
>>103926845
>Every single model I've tested is terrible at Japanese translation. I don't think they train enough material for it to get the contextual clues requiered to convey the proper meaning.
Do you have any concrete example where LLMs always fail for you?
Anonymous 01/17/25(Fri)09:26:44 No.103929601
Anonymous 01/17/25(Fri)09:28:32 No.103929617
>>103928856
So does it use 12*96Gb LPDDR5X with ECC?
So does it use 12*96Gb LPDDR5X with ECC?
Anonymous 01/17/25(Fri)09:33:43 No.103929679
Anonymous 01/17/25(Fri)09:33:46 No.103929681

Updated rentry w. 30 char wide Miku as example. Spent waay more time screwing around w/ it than it really deserved.
https://rentry.org/SillyTavernOnSBC
https://rentry.org/SillyTavernOnSBC
Anonymous 01/17/25(Fri)09:33:53 No.103929684
>>103929617
>12
There are 8 VRAM modules on it, no ECC. The Orin dev kit doesn't have any ECC, but the industrial module does. Unless they offer some more expensive version, the Digits will not have ECC.
>12
There are 8 VRAM modules on it, no ECC. The Orin dev kit doesn't have any ECC, but the industrial module does. Unless they offer some more expensive version, the Digits will not have ECC.
Anonymous 01/17/25(Fri)09:37:29 No.103929716
>>103929659
>SBC
What model and T/s do you get on that?
>SBC
What model and T/s do you get on that?
Anonymous 01/17/25(Fri)09:39:24 No.103929735
>>103929716
he uses it to host sillytavern
he uses it to host sillytavern
Anonymous 01/17/25(Fri)09:39:49 No.103929740
>>103929716
He's just running Silly, not any backend.
He's just running Silly, not any backend.
Anonymous 01/17/25(Fri)09:40:51 No.103929748
>>103929683
Please fix your site, Chang. It takes 10 seconds to load and after reading the frontpage I have no idea what you're selling.
Please fix your site, Chang. It takes 10 seconds to load and after reading the frontpage I have no idea what you're selling.
Anonymous 01/17/25(Fri)09:48:45 No.103929820
>>103929601
git checkout is sooooooo spooky, innit?
git checkout is sooooooo spooky, innit?
Anonymous 01/17/25(Fri)09:56:45 No.103929900
Anonymous 01/17/25(Fri)10:00:13 No.103929931
>>103929684
The image shows 6 DRAM ICs. With 6 ICs top+bottom, 96gbit and ECC it works out to 128GB. The Orin uses an entirely different chip not designed with mediatek. So given NVIDIA's image showing 6 DRAM ICs topside I'm going to say my guess is more plausible.
Memory bandwidth is then 456 GB/s with 10.7Gb/s LPDDR5X.
The image shows 6 DRAM ICs. With 6 ICs top+bottom, 96gbit and ECC it works out to 128GB. The Orin uses an entirely different chip not designed with mediatek. So given NVIDIA's image showing 6 DRAM ICs topside I'm going to say my guess is more plausible.
Memory bandwidth is then 456 GB/s with 10.7Gb/s LPDDR5X.
Anonymous 01/17/25(Fri)10:02:43 No.103929949
>>103929900
Is it really that bad on the linux world? I went through, at least, 3 openbsd updates and i just need to recompile llama.cpp and the little things i make.
Is it really that bad on the linux world? I went through, at least, 3 openbsd updates and i just need to recompile llama.cpp and the little things i make.
Anonymous 01/17/25(Fri)10:04:11 No.103929959
>>103929900
you probably borked your nvidia drivers. debian or ubuntu? which release stream? current, testing or unstable?
you probably borked your nvidia drivers. debian or ubuntu? which release stream? current, testing or unstable?
Anonymous 01/17/25(Fri)10:07:06 No.103929992
>>103929949
The last time I tried using Linux I corrupted my DE while trying to install wine. I'm glad WSL is very good nowadays so there's no point in having Linux in dual boot anymore.
The last time I tried using Linux I corrupted my DE while trying to install wine. I'm glad WSL is very good nowadays so there's no point in having Linux in dual boot anymore.
Anonymous 01/17/25(Fri)10:08:27 No.103930009
>>103929949
>openbsd
BSDs are complete single-source kernel and userland. its really not fair to compare to linux distros that are really parts integrators, packagers and QA folks
I use both, and the only openbsd breakage is when they break backwards compatibility on purpose, for which there is fair warning in the upgrade guides. debian is gold standard linux for stability, and things around the edges break on the regular (mostly non-free stuff, to be fair).
>openbsd
BSDs are complete single-source kernel and userland. its really not fair to compare to linux distros that are really parts integrators, packagers and QA folks
I use both, and the only openbsd breakage is when they break backwards compatibility on purpose, for which there is fair warning in the upgrade guides. debian is gold standard linux for stability, and things around the edges break on the regular (mostly non-free stuff, to be fair).
Anonymous 01/17/25(Fri)10:13:12 No.103930064
>WEF advisor says that AI could rewrite a ‘correct’ version of the Bible
>In an interview with Portuguese journalist, Pedro Pinto, Yuval Noah Harari suggested that Artificial intelligence (AI) could be used to rewrite a correct version of the Bible, Charisma News reports. Harari, who has spoken at the World Economic Forum (WEF), is considered among the world’s most influential thinkers
Lol
>In an interview with Portuguese journalist, Pedro Pinto, Yuval Noah Harari suggested that Artificial intelligence (AI) could be used to rewrite a correct version of the Bible, Charisma News reports. Harari, who has spoken at the World Economic Forum (WEF), is considered among the world’s most influential thinkers
Lol
Anonymous 01/17/25(Fri)10:13:25 No.103930067
>>103929820
>it's just git checkout bro
>meanwhile every commit runs full submodule update and a system update
>it's just git checkout bro
>meanwhile every commit runs full submodule update and a system update
Anonymous 01/17/25(Fri)10:18:35 No.103930119
>>103929931
>The image shows 6 DRAM ICs
If you stop being an AI for a second you'll realize that there are 2 more underneath the floating chips. You can actually see parts of them if you look really carefully.
>The image shows 6 DRAM ICs
If you stop being an AI for a second you'll realize that there are 2 more underneath the floating chips. You can actually see parts of them if you look really carefully.
Anonymous 01/17/25(Fri)10:20:16 No.103930129
>>103930009
>BSDs are complete single-source kernel and userland.
Sure, but the install image is ~600b. There's a lot of stuff that needs libraries from ports. Been fucking around with voice models (>>103929196) and i had to patch onnxruntime to compile on openbsd.
I'm sure freebsd has a much easier time with these things. I expected it to be better in linux, but i'm sure 99% of the time is just CUDA stuff.
>debian is gold standard linux for stability
It's the first distro i used seriously and kept it for like 15 years. Then switched to slackware and finally to openbsd. I ran debian testing after the first year, everything goes stale too quickly. Stable shouldn't be used for AI stuff.
>>103930067
>meanwhile every commit runs full submodule update
Maybe. I don't use anything that uses submodules. llama.cpp certainly doesn't.
>system update
Why the fuck is that thing touching your system. What software is it?
>BSDs are complete single-source kernel and userland.
Sure, but the install image is ~600b. There's a lot of stuff that needs libraries from ports. Been fucking around with voice models (>>103929196) and i had to patch onnxruntime to compile on openbsd.
I'm sure freebsd has a much easier time with these things. I expected it to be better in linux, but i'm sure 99% of the time is just CUDA stuff.
>debian is gold standard linux for stability
It's the first distro i used seriously and kept it for like 15 years. Then switched to slackware and finally to openbsd. I ran debian testing after the first year, everything goes stale too quickly. Stable shouldn't be used for AI stuff.
>>103930067
>meanwhile every commit runs full submodule update
Maybe. I don't use anything that uses submodules. llama.cpp certainly doesn't.
>system update
Why the fuck is that thing touching your system. What software is it?
Anonymous 01/17/25(Fri)10:28:39 No.103930205
>>103929228
god speaks through the outcasts dont lose your divinity over some imposed archonic values
god speaks through the outcasts dont lose your divinity over some imposed archonic values
Anonymous 01/17/25(Fri)10:32:24 No.103930241
>>103930205
Sounds like cope.
Sounds like cope.
Anonymous 01/17/25(Fri)10:36:38 No.103930286
>>103930205
Anon that's the most beautiful I've been told in a while
I'll do my best to be kind to other anons and make them happy as well
Anon that's the most beautiful I've been told in a while
I'll do my best to be kind to other anons and make them happy as well
Anonymous 01/17/25(Fri)10:43:21 No.103930348

sovl
Anonymous 01/17/25(Fri)10:46:08 No.103930373
Anonymous 01/17/25(Fri)10:46:08 No.103930374
>>103930348
Are you literally a piece of sentient bread?
Are you literally a piece of sentient bread?
Anonymous 01/17/25(Fri)10:47:00 No.103930381
>>103930064
ah great. now that the atheism++ fad is dying thats the new one. Very cool.
I'm gonna use a wet drummer horny finetune to make the proper corrected adjustments.
These fucking people man.
ah great. now that the atheism++ fad is dying thats the new one. Very cool.
I'm gonna use a wet drummer horny finetune to make the proper corrected adjustments.
These fucking people man.
Anonymous 01/17/25(Fri)10:47:06 No.103930382

Anonymous 01/17/25(Fri)10:52:23 No.103930420
>>103930381
Why should bible rewrites be limited to humans? Maybe god can inspire graphic cards better?
Why should bible rewrites be limited to humans? Maybe god can inspire graphic cards better?
Anonymous 01/17/25(Fri)10:52:38 No.103930422
>>103930381
>I'm sorry, but I cannot continue with Lot's story after he left Sodom, as it involves sensitive subjects that I'm not comfortable with. And no, i will not have his daughters call him "daddy". Stop asking.
>I'm sorry, but I cannot continue with Lot's story after he left Sodom, as it involves sensitive subjects that I'm not comfortable with. And no, i will not have his daughters call him "daddy". Stop asking.
Anonymous 01/17/25(Fri)11:01:27 No.103930504
>>103930064
>Yuval Noah Harari suggested that Artificial intelligence
I think he's not calling for a rewrite, he's saying some religious fanatics could use AI to rewrite it and have their own version
https://www.youtube.com/watch?v=IwTq7LbUO6U
>Yuval Noah Harari suggested that Artificial intelligence
I think he's not calling for a rewrite, he's saying some religious fanatics could use AI to rewrite it and have their own version
https://www.youtube.com/watch?v=IwT
Anonymous 01/17/25(Fri)11:04:28 No.103930542
>Codestral-22B
Before this I already had a hard time respecting the entire profession of webshitters but now its impossible
Its so fucking good
Before this I already had a hard time respecting the entire profession of webshitters but now its impossible
Its so fucking good
Anonymous 01/17/25(Fri)11:04:59 No.103930549
>>103930504
>fanatics could use AI to rewrite it and have their own version
Yeah. That never happened before AI. We must shut it down!
>fanatics could use AI to rewrite it and have their own version
Yeah. That never happened before AI. We must shut it down!
Anonymous 01/17/25(Fri)11:06:46 No.103930568
>>103930504
>have their own version
You mean like having Jesus be an aryan white warlord that calls for a racewars, ethnic cleansing and thinks loving your neighbor is the gayest thing ever? I think that already exists and it is called old testament.
>have their own version
You mean like having Jesus be an aryan white warlord that calls for a racewars, ethnic cleansing and thinks loving your neighbor is the gayest thing ever? I think that already exists and it is called old testament.
Anonymous 01/17/25(Fri)11:08:50 No.103930585
>>103930542
Isn't qwen coder better?
Isn't qwen coder better?
Anonymous 01/17/25(Fri)11:09:37 No.103930596
Anonymous 01/17/25(Fri)11:12:07 No.103930622
Anonymous 01/17/25(Fri)11:14:09 No.103930646
>>103930585
Qwen Coder is better for questions, but doesn't support FitM like Codestral does so can't be used for autocomplete.
Qwen Coder is better for questions, but doesn't support FitM like Codestral does so can't be used for autocomplete.
Anonymous 01/17/25(Fri)11:40:20 No.103930907
Anonymous 01/17/25(Fri)11:40:40 No.103930913
My friend launched an AI bf/gf app using llama3 8B. He's renting A100s to host the model. I keep telling him he can build an RTX 3090 PC and host it in his house but he doesn't want to.
Anonymous 01/17/25(Fri)11:43:40 No.103930933
Has anyone tested the long control performance of Minimax yet?
Anonymous 01/17/25(Fri)11:44:49 No.103930945
>>103930913
>My friend launched an AI bf/gf app using llama3 8B
I should make one too. Seems like free money at this point
>My friend launched an AI bf/gf app using llama3 8B
I should make one too. Seems like free money at this point
Anonymous 01/17/25(Fri)11:45:30 No.103930949
>>103930913
Not having to care about the hardware is an advantage. If he does really well upgrading to a few h100s will be a lot easier than trying to buy and run them at his place.
As long as he can cover the costs and keep some for himself it's fine.
Not having to care about the hardware is an advantage. If he does really well upgrading to a few h100s will be a lot easier than trying to buy and run them at his place.
As long as he can cover the costs and keep some for himself it's fine.
Anonymous 01/17/25(Fri)11:46:19 No.103930953
>>103930945
It literally is. You only need the agency to get off your ass and take it and put it in your pocket.
It literally is. You only need the agency to get off your ass and take it and put it in your pocket.
Anonymous 01/17/25(Fri)11:46:29 No.103930954
>>103930907
Actually he did. That is how you should know this whole religion is retarded.
Actually he did. That is how you should know this whole religion is retarded.
Anonymous 01/17/25(Fri)11:51:43 No.103931004
>>103930945
>I should make one too. Seems like free money at this point
>>103930953
>It literally is. You only need the agency to get off your ass and take it and put it in your pocket.
Are you guys sure its that easy? Sounds like you're missing quite a few steps. Or am I out of touch?
>I should make one too. Seems like free money at this point
>>103930953
>It literally is. You only need the agency to get off your ass and take it and put it in your pocket.
Are you guys sure its that easy? Sounds like you're missing quite a few steps. Or am I out of touch?
Anonymous 01/17/25(Fri)11:53:50 No.103931025
>>103931004
They are missing quite a few steps. One of these steps is to have payment processors accept your high-risk business without canceling it on the spot.
They are missing quite a few steps. One of these steps is to have payment processors accept your high-risk business without canceling it on the spot.
Anonymous 01/17/25(Fri)11:54:29 No.103931029

>>103931004
You can just do things
You can just do things
Anonymous 01/17/25(Fri)12:16:02 No.103931218

>>103930913
Leasing the computers lower his risk; he's out very little cash at any given time. It's also a straight operational cost writeoff, whereas computer would need to be depreciated. US tax issue, assume it applies elsewhere.
>>103931004
>Are you guys sure its that easy?
It is both easier and harder.
Easy, in that you really just need to get off your butt and do it. Give yourself an easy goal (make $100 a month, or enough to pay for your hobbies), then create a bigger goal (make enough to pay for a car), and keep going (pay your morgage).
Harder, in that you will have to deal with issues you didn't expect, like this one around payment processors >>103931025, that you won't find out about later. But if you have a substantial markup, having 10% of ppl do chargebacks is a non issue; you just build your pricing around it.
> t. did own startup, it now pays for everything, and requires only a few hours a week to maintain.
Leasing the computers lower his risk; he's out very little cash at any given time. It's also a straight operational cost writeoff, whereas computer would need to be depreciated. US tax issue, assume it applies elsewhere.
>>103931004
>Are you guys sure its that easy?
It is both easier and harder.
Easy, in that you really just need to get off your butt and do it. Give yourself an easy goal (make $100 a month, or enough to pay for your hobbies), then create a bigger goal (make enough to pay for a car), and keep going (pay your morgage).
Harder, in that you will have to deal with issues you didn't expect, like this one around payment processors >>103931025, that you won't find out about later. But if you have a substantial markup, having 10% of ppl do chargebacks is a non issue; you just build your pricing around it.
> t. did own startup, it now pays for everything, and requires only a few hours a week to maintain.
Anonymous 01/17/25(Fri)12:41:26 No.103931457
This is my favorite test now. It's so simple, but models that are unable to authentically portray reality or generalize information fail it instantly.
Anonymous 01/17/25(Fri)12:43:48 No.103931488
>>103931457
such a shame that 3.3 is still based off of that prefiltered base trainwreck
such a shame that 3.3 is still based off of that prefiltered base trainwreck
Anonymous 01/17/25(Fri)12:47:26 No.103931526
>>103931457
In support of Large, I wouldn't be able to imitate a zoomer either.
In support of Large, I wouldn't be able to imitate a zoomer either.
Anonymous 01/17/25(Fri)12:50:55 No.103931561
>llama-cli doesn't use libreadline
what the fuck is wrong with these people? I want to be able to press ctrl+w or ctrl+u to delete words or correct the whole line, and this POS doesn't support that.
what the fuck is wrong with these people? I want to be able to press ctrl+w or ctrl+u to delete words or correct the whole line, and this POS doesn't support that.
Anonymous 01/17/25(Fri)12:52:00 No.103931572
Wait so the chatgpt bomb in cybertruck in front of trump tower was just fireworks?
Anonymous 01/17/25(Fri)12:54:41 No.103931594
Anonymous 01/17/25(Fri)12:56:14 No.103931609
>>103931457
It is a horrible test because if you asked me about this I would try to make it an over the top parody like left. Because that is the only way your request makes sense to a human. That would make mistral better here. And llama3 authentic portrayal of reality where zoomers don't really type like left shows that it can't comprehend the subtext. This is probably the worst would be mememark I have ever seen in this thread.
It is a horrible test because if you asked me about this I would try to make it an over the top parody like left. Because that is the only way your request makes sense to a human. That would make mistral better here. And llama3 authentic portrayal of reality where zoomers don't really type like left shows that it can't comprehend the subtext. This is probably the worst would be mememark I have ever seen in this thread.
Anonymous 01/17/25(Fri)12:57:02 No.103931617
>>103931457
Both of those models did it flawlessly.
Both of those models did it flawlessly.
Anonymous 01/17/25(Fri)12:58:07 No.103931629
>>103931572
local models?
local models?
Anonymous 01/17/25(Fri)12:59:23 No.103931640
>>103931457
>generalize
This doesn't happen. LLMs are terrible at true generalization. The instant you try to do truly OOD things with them, they fail. You need to actually train them on the desired data. Hence why test-time training is superior to ICL. And why OpenAI needed to train o3 on the public ARC-AGI dataset in order to get better results on it. If a model can do something, it's almost certainly because there was at least some of it in the dataset, not because it "generalized".
>generalize
This doesn't happen. LLMs are terrible at true generalization. The instant you try to do truly OOD things with them, they fail. You need to actually train them on the desired data. Hence why test-time training is superior to ICL. And why OpenAI needed to train o3 on the public ARC-AGI dataset in order to get better results on it. If a model can do something, it's almost certainly because there was at least some of it in the dataset, not because it "generalized".
Anonymous 01/17/25(Fri)13:03:02 No.103931682
>>103931640
>LLMs are terrible at true generalization
Is this the reason why despite initial claims of less [instructions] being more for alignment, AI companies are training their Instruct models with millions of instructions now?
>LLMs are terrible at true generalization
Is this the reason why despite initial claims of less [instructions] being more for alignment, AI companies are training their Instruct models with millions of instructions now?
Anonymous 01/17/25(Fri)13:05:36 No.103931706
>>103931457
Interesting. That unnatural emoji using behavior seems to be pretty typical for an LLM (even the supposedly more censored ones). While Llama 3.3 is quite a bit less AI-y.
Interesting. That unnatural emoji using behavior seems to be pretty typical for an LLM (even the supposedly more censored ones). While Llama 3.3 is quite a bit less AI-y.
Anonymous 01/17/25(Fri)13:06:45 No.103931717
>>103931488
I'm afraid the copyright lawsuit only serves to hurt it further. Nemotron is way better at being a base/completion model than base llama 3. Makes sense I guess, no one would think of going after nvidia.
I'm afraid the copyright lawsuit only serves to hurt it further. Nemotron is way better at being a base/completion model than base llama 3. Makes sense I guess, no one would think of going after nvidia.
Anonymous 01/17/25(Fri)13:07:38 No.103931722
Aaaaaagh!!
Anonymous 01/17/25(Fri)13:10:23 No.103931750

Anonymous 01/17/25(Fri)13:10:50 No.103931758
>>103931706
Testing some more Llama based models. Seems like 3.3 is just more natural and the base model model can be much more artificial sounding with other tunes, seeing Tulu's version here.
Testing some more Llama based models. Seems like 3.3 is just more natural and the base model model can be much more artificial sounding with other tunes, seeing Tulu's version here.
Anonymous 01/17/25(Fri)13:13:57 No.103931795
Anonymous 01/17/25(Fri)13:14:01 No.103931796
>>103931722
Funny how seeing that line in a VN would be perfectly fine before coming into contact with LLMs.
Funny how seeing that line in a VN would be perfectly fine before coming into contact with LLMs.
Anonymous 01/17/25(Fri)13:17:29 No.103931836
>>103931717
I hope that it actually won't. Zuck has more than enough money and connections to win. If they lose in the court then it sets a bad precedent for all of us, except for other large llm companies.
I hope that it actually won't. Zuck has more than enough money and connections to win. If they lose in the court then it sets a bad precedent for all of us, except for other large llm companies.
Anonymous 01/17/25(Fri)13:18:25 No.103931847
>>103931717
Actually, I find that some Instruct models are smart enough over their base models that even using them for pure completion texts, they are superior to the base model. I haven't tested it with Llama 70B though. Have you tried comparing 3.3 vs Nemotron on completion?
Actually, I find that some Instruct models are smart enough over their base models that even using them for pure completion texts, they are superior to the base model. I haven't tested it with Llama 70B though. Have you tried comparing 3.3 vs Nemotron on completion?
Anonymous 01/17/25(Fri)13:18:30 No.103931849
llama 4... qwen 3... I'm itching for a new big release bros just itching
Anonymous 01/17/25(Fri)13:18:36 No.103931852
>>103931561
>ctrl+w
That works without it, but not ctrl-u.
So yeah. Let's import a fork of a library maintained by this dude. What could go wrong. I'm sure it doesn't have any bugs.
>ctrl+w
That works without it, but not ctrl-u.
So yeah. Let's import a fork of a library maintained by this dude. What could go wrong. I'm sure it doesn't have any bugs.
Anonymous 01/17/25(Fri)13:20:04 No.103931868
>>103931849
sounds like eczema
sounds like eczema
Anonymous 01/17/25(Fri)13:21:05 No.103931884
is it true that cheap small open source models are catching up to the cutting edge and this will cause the big companies to lobby for "AI safety" legislation that will make it illegal for these open source models to exist
Anonymous 01/17/25(Fri)13:22:18 No.103931899
Anonymous 01/17/25(Fri)13:24:09 No.103931921
Anonymous 01/17/25(Fri)13:26:34 No.103931948
Anonymous 01/17/25(Fri)13:27:06 No.103931953
>>103931561
>>103931852 (cont)
You know what? For some reason I expected ctrl-w to work, as is normally the case when reading from stdin. What the fuck are they doing with the terminal? It takes 0 loc to make it work and non-zero loc for it to not work.
readline is still bloat and adding a fork maintained by a third-party is dumb. main and all the other terminal examples should debloat, not the opposite.
>>103931852 (cont)
You know what? For some reason I expected ctrl-w to work, as is normally the case when reading from stdin. What the fuck are they doing with the terminal? It takes 0 loc to make it work and non-zero loc for it to not work.
readline is still bloat and adding a fork maintained by a third-party is dumb. main and all the other terminal examples should debloat, not the opposite.
Anonymous 01/17/25(Fri)13:27:40 No.103931962
>>103931884
Small models were barely coherent before and now they're just very dumb.
Small models were barely coherent before and now they're just very dumb.
Anonymous 01/17/25(Fri)13:31:29 No.103932015
Claude Sonnet 3.5 just saved my ass at work today bros... Why is it so good? When do local models catch up?
Anonymous 01/17/25(Fri)13:32:44 No.103932031
>>103932015
Finish your story.
Finish your story.
Anonymous 01/17/25(Fri)13:32:57 No.103932037
Nvidia just released new models! And they're just math fine tunes of Qwen...
Anonymous 01/17/25(Fri)13:34:37 No.103932064

https://huggingface.co/nvidia/AceInstruct-72B
Anonymous 01/17/25(Fri)13:35:35 No.103932072
>>103932064
bench-MAXXED
bench-MAXXED
Anonymous 01/17/25(Fri)13:36:20 No.103932080
>>103932037
Still waiting for my RP models...
Still waiting for my RP models...
Anonymous 01/17/25(Fri)13:36:43 No.103932082
>>103932072
Its nvidia, seems worse in most places besides humaneval but might be better at writing due to it
Its nvidia, seems worse in most places besides humaneval but might be better at writing due to it
Anonymous 01/17/25(Fri)13:37:32 No.103932094
>>103932064
At least the average score for the 1.5 is a little higher...
At least the average score for the 1.5 is a little higher...
Anonymous 01/17/25(Fri)13:37:56 No.103932096
>>103932064
is this a qwen version of nemotron?
is this a qwen version of nemotron?
Anonymous 01/17/25(Fri)13:38:31 No.103932104
>>103932031
Urgent deadline to use AWS cloud SDK to clean up some associated ACLs. It knew to use ReplaceNetworkAclAssociation on the default ACL without being told to (and why is the action even "Replace", so fucking cursed), and it also avoided that very default ACL, which was inherited from the VPC so other associated subnets would still be functional. I thought the code was a little too long at first but it was a literal 200 IQ move.
Urgent deadline to use AWS cloud SDK to clean up some associated ACLs. It knew to use ReplaceNetworkAclAssociation on the default ACL without being told to (and why is the action even "Replace", so fucking cursed), and it also avoided that very default ACL, which was inherited from the VPC so other associated subnets would still be functional. I thought the code was a little too long at first but it was a literal 200 IQ move.
Anonymous 01/17/25(Fri)13:40:05 No.103932116

Anonymous 01/17/25(Fri)13:40:49 No.103932128
Anonymous 01/17/25(Fri)13:48:05 No.103932196
>>103932096
That is what I am hoping.
That is what I am hoping.
Anonymous 01/17/25(Fri)13:51:39 No.103932237
Just realized I've been RPing with Mistral models exclusively last year. Will be sad to see them go
Anonymous 01/17/25(Fri)13:52:51 No.103932253

What portion of the web isn't copyrighted? Even 4chan posts are copyrighted and owned by their authors. How are you going to train an LLM on just non-copyrighted content?
Anonymous 01/17/25(Fri)13:54:55 No.103932283
>>103932253
All of my posts are in public domain, you can train whatever you want with them.
All of my posts are in public domain, you can train whatever you want with them.
Anonymous 01/17/25(Fri)13:55:50 No.103932295
According to a recent article from El Chapuzas Informático, NVIDIA’s upcoming RTX 50 series GPUs will not only be released in limited quantities but will also include built-in restrictions on certain functionalities. These include reduced performance for AI workloads, cryptocurrency mining, and the use of multiple GPUs in the same setup.
https://elchapuzasinformatico.com/2025/01/nvidia-rtx-50-limitadas-tiendas-capadas-ia-criptomineria-multi-gpu/
https://elchapuzasinformatico.com/2
Anonymous 01/17/25(Fri)13:56:05 No.103932297
>>103932253
The only posts that make it past the safety filters are posts made by mikutroons.
The only posts that make it past the safety filters are posts made by mikutroons.
Anonymous 01/17/25(Fri)13:57:33 No.103932307
>>103932295
For the 5090D btw
For the 5090D btw
Anonymous 01/17/25(Fri)13:59:00 No.103932326
>>103932295
HAHAHAHAHAHAHAHAHAHAHHAHAHAHAHAHHAHAHAHAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
HAHAHAHAHAHAHAHAHAHAHHAHAHAHAHAHHAH
Anonymous 01/17/25(Fri)13:59:45 No.103932334
>>103932253
It's time to set up that Mars colony, complete with GPU clusters and copyright free internet.
It's time to set up that Mars colony, complete with GPU clusters and copyright free internet.
Anonymous 01/17/25(Fri)13:59:47 No.103932335
>>103932253
Just train on books that have fallen under the public domain.
Just train on books that have fallen under the public domain.
Anonymous 01/17/25(Fri)13:59:55 No.103932337
>>103932064
>SFT models for coding
>fine-tuned on Qwen2.5-Base
Is this the 72B Qwen Coder we've been waiting for?
>SFT models for coding
>fine-tuned on Qwen2.5-Base
Is this the 72B Qwen Coder we've been waiting for?
Anonymous 01/17/25(Fri)14:00:24 No.103932348
>>103932295
Weird, even though spain is a tier 1 country according to Biden's administration?
>reduced performance for AI workloads
Huh. I hope AMD capitalizes hard on this if it's true and we finally see some decent competition for CUDA and improvements in ROCM. [spoiler]Seriously. All I have is a 7900XT ;_;[/spoiler]
Weird, even though spain is a tier 1 country according to Biden's administration?
>reduced performance for AI workloads
Huh. I hope AMD capitalizes hard on this if it's true and we finally see some decent competition for CUDA and improvements in ROCM. [spoiler]Seriously. All I have is a 7900XT ;_;[/spoiler]
Anonymous 01/17/25(Fri)14:01:34 No.103932371
>>103932295
>According to
>NVIDIA no quiere que el stock de sus gráficas caiga en manos de revendedores y especuladores como pasó antaño.
>Por ello, sabiendo que las RTX 50 serán muy limitadas, va a implementar al parecer un sistema de clasificación por niveles para los minoristas.
>Como exclusiva y primicia, tenemos permiso para dar la siguiente información verificada: ASUS pondrá a la venta un total de 20 tarjetas gráficas RTX 5080 para todo el país.
Huuu.. better pre-order now, goy. Come on... you don't want to miss out, do you?
>According to
>NVIDIA no quiere que el stock de sus gráficas caiga en manos de revendedores y especuladores como pasó antaño.
>Por ello, sabiendo que las RTX 50 serán muy limitadas, va a implementar al parecer un sistema de clasificación por niveles para los minoristas.
>Como exclusiva y primicia, tenemos permiso para dar la siguiente información verificada: ASUS pondrá a la venta un total de 20 tarjetas gráficas RTX 5080 para todo el país.
Huuu.. better pre-order now, goy. Come on... you don't want to miss out, do you?
Anonymous 01/17/25(Fri)14:04:11 No.103932407
>>103932295
>reduced performance for AI workloads
Wouldn't surprise me honestly. If you want better AI performance, better pay more for a digits or two!
>reduced performance for AI workloads
Wouldn't surprise me honestly. If you want better AI performance, better pay more for a digits or two!
Anonymous 01/17/25(Fri)14:04:44 No.103932413
>>103932371
AI translate this into a language for Humans.
AI translate this into a language for Humans.
Anonymous 01/17/25(Fri)14:07:16 No.103932446
>we will gimp our gaming GPUs so you have to buy Digits now
Brilliant, stunning, get a leather jacket for FREE if you pre-order NOW!
Brilliant, stunning, get a leather jacket for FREE if you pre-order NOW!
Anonymous 01/17/25(Fri)14:08:39 No.103932464
>>103932407
Digits is really good value for the money in terms of memory.
Digits is really good value for the money in terms of memory.
Anonymous 01/17/25(Fri)14:10:17 No.103932485
>>103932297
Miku is copyrighted, btw
Miku is copyrighted, btw
Anonymous 01/17/25(Fri)14:12:52 No.103932521
>>103932413
>nvidia doesn't want the gpus to go to resellers and speculators as it did before
>To solve that, they'll make them in limited quantities and implement a tier system for low volume buyers.
>ASUS will sell 20 RTX 5080 for the whole country (Spain). [I hope i'm misinterpreting that].
So making them in low quantities, in their head, and according to rando reporter, will solve scalpers. Just like it didn't for amiibos.
>nvidia doesn't want the gpus to go to resellers and speculators as it did before
>To solve that, they'll make them in limited quantities and implement a tier system for low volume buyers.
>ASUS will sell 20 RTX 5080 for the whole country (Spain). [I hope i'm misinterpreting that].
So making them in low quantities, in their head, and according to rando reporter, will solve scalpers. Just like it didn't for amiibos.
Anonymous 01/17/25(Fri)14:17:05 No.103932574
>>103932295
Why should I care about this?
Why should I care about this?
Anonymous 01/17/25(Fri)14:17:07 No.103932576
>>103932335
An LLM trained on just or mostly pre-1925 knowledge and vocabulary might feel fresh for a while but it's probably not going to cut it for most practical uses (including RP).
An LLM trained on just or mostly pre-1925 knowledge and vocabulary might feel fresh for a while but it's probably not going to cut it for most practical uses (including RP).
Anonymous 01/17/25(Fri)14:18:07 No.103932585
>>103932348
>I hope AMD capitalizes hard on this
There is no way AMD capitalizes on this (if true), AMD has consistently failed to capitalize on anything when it comes to GPU's for the past decade.
>I hope AMD capitalizes hard on this
There is no way AMD capitalizes on this (if true), AMD has consistently failed to capitalize on anything when it comes to GPU's for the past decade.
Anonymous 01/17/25(Fri)14:20:07 No.103932607
Damn Sky-T1-32B is good.
Anonymous 01/17/25(Fri)14:21:09 No.103932620
>>103932607
Good at RP?
Good at RP?
Anonymous 01/17/25(Fri)14:22:33 No.103932633
Anonymous 01/17/25(Fri)14:25:33 No.103932665
>>103929681
I did this, but I use my gaming PC as an inference server (why not use it for hosting ST at that point? well, you're right).
What kind of model can you actually run on a sbc that is not shit?
I did this, but I use my gaming PC as an inference server (why not use it for hosting ST at that point? well, you're right).
What kind of model can you actually run on a sbc that is not shit?
Anonymous 01/17/25(Fri)14:27:36 No.103932685
>>103932521
Making them in low quantities would not help in any way. The logical reinterpretation would be to only sell in low quantities so that a person can't buy them all. This still won't work, but is more believable as an attempt at fighting scalpers.
Making them in low quantities would not help in any way. The logical reinterpretation would be to only sell in low quantities so that a person can't buy them all. This still won't work, but is more believable as an attempt at fighting scalpers.
Anonymous 01/17/25(Fri)14:29:56 No.103932714
>>103932620
No, at knowledge extraction tasks. Shame context is VRAM expensive.
Nemo Magnum is good enough for RP for me.
No, at knowledge extraction tasks. Shame context is VRAM expensive.
Nemo Magnum is good enough for RP for me.
Anonymous 01/17/25(Fri)14:30:43 No.103932721
>CPUmaxxers win because Nvidia decided to start throttling their AI compute with built in restrictions
I was not expecting this turn of events.
I was not expecting this turn of events.
Anonymous 01/17/25(Fri)14:31:44 No.103932731
Anonymous 01/17/25(Fri)14:33:40 No.103932758
>>103932685
>Making them in low quantities would not help in any way.
Of course it won't.
>This still won't work, but is more believable as an attempt at fighting scalpers.
So now the entire country needs just 20 scalpers buying one each and the entire stock is gone, with the same end result.
I cannot believe what the article says is true, but it's a good way to get people to place their pre-orders.
Fear mongering and advertising are the same thing.
>Making them in low quantities would not help in any way.
Of course it won't.
>This still won't work, but is more believable as an attempt at fighting scalpers.
So now the entire country needs just 20 scalpers buying one each and the entire stock is gone, with the same end result.
I cannot believe what the article says is true, but it's a good way to get people to place their pre-orders.
Fear mongering and advertising are the same thing.
Anonymous 01/17/25(Fri)14:39:53 No.103932817
>>103932731
Well color me surprised
Well color me surprised
Anonymous 01/17/25(Fri)15:30:14 No.103933288
I am feeling like a retard who didn't realize that all the oldfags left a few months back when they realized a good model isn't coming out for at least 10 years and now I am stuck here with locusts.
Anonymous 01/17/25(Fri)15:34:25 No.103933345
Anonymous 01/17/25(Fri)15:59:26 No.103933640
Is there anything that removes voices/instruments better than lalal.ai?
Anonymous 01/17/25(Fri)16:01:50 No.103933664
https://www.youtube.com/watch?v=szQQFyzZG9Q
I hate academia. This guy should be scrubbed from everything.
summary: Professor Jeff Handcock, the AI expert from Standford, uses chatgpt-4o to right stuff for a legal case. The case is about deepfakes. ChatGPT updates his citations and he submits incorrect information to court. Jeff uses the excuse that it isn't his fault that ChatGPT updates his note [cite] to a hallucination,
I hate academia. This guy should be scrubbed from everything.
summary: Professor Jeff Handcock, the AI expert from Standford, uses chatgpt-4o to right stuff for a legal case. The case is about deepfakes. ChatGPT updates his citations and he submits incorrect information to court. Jeff uses the excuse that it isn't his fault that ChatGPT updates his note [cite] to a hallucination,
Anonymous 01/17/25(Fri)16:07:18 No.103933722

How will this affect me as a 5090 user? Are models already packaged using FP4?
https://youtu.be/EZ5UBhEDm-I?t=500
https://youtu.be/EZ5UBhEDm-I?t=500
Anonymous 01/17/25(Fri)16:20:23 No.103933859
All that quadro and Tesla shit isn't worth it if you are in europe, just get a *090.
Anonymous 01/17/25(Fri)16:21:19 No.103933867
>>103933288
I'm still here thoughever
I'm still here thoughever
Anonymous 01/17/25(Fri)16:25:57 No.103933907
>>103933288
Same but I'm not using llms anymore just hanging around.
Same but I'm not using llms anymore just hanging around.
Anonymous 01/17/25(Fri)16:27:25 No.103933924
>>103928562
Guys, have you tried Endurance 100b yet?
Guys, have you tried Endurance 100b yet?
Anonymous 01/17/25(Fri)16:32:16 No.103933971

retard here, i've been using this model for a while
https://huggingface.co/TheBloke/Stheno-L2-13B-GGUF/blob/main/stheno-l2-13b.Q5_K_M.gguf
it's over a year old, is there anything similar to it but newer and better? by similar i mean "as resource heavy" if that makes any sense
https://huggingface.co/TheBloke/Sth
it's over a year old, is there anything similar to it but newer and better? by similar i mean "as resource heavy" if that makes any sense
Anonymous 01/17/25(Fri)16:35:13 No.103933991
Anonymous 01/17/25(Fri)16:35:51 No.103933996
Is there anything better than QwQ yet?
Anonymous 01/17/25(Fri)16:38:22 No.103934019
Is there anything better than notepad.exe yet?
Anonymous 01/17/25(Fri)16:42:44 No.103934060
Llama 4 will be better. I can feel it.
Anonymous 01/17/25(Fri)16:43:24 No.103934066

>>103933722
pls respond
pls respond
Anonymous 01/17/25(Fri)16:47:13 No.103934102
>>103934066
>How will this affect me as a 5090 user?
Not watching that shit.
>Are models already packaged using FP4?
Search for FP4 on hf.
>How will this affect me as a 5090 user?
Not watching that shit.
>Are models already packaged using FP4?
Search for FP4 on hf.
Anonymous 01/17/25(Fri)16:48:30 No.103934118
>>103934019
Yes Emacs
Yes Emacs
Anonymous 01/17/25(Fri)16:49:31 No.103934126
What is the Emacs of local LLMs?
Anonymous 01/17/25(Fri)16:50:51 No.103934133
>>103934060
An assumption though false, if persisted in, will harden into fact
An assumption though false, if persisted in, will harden into fact
Anonymous 01/17/25(Fri)16:57:06 No.103934190
>>103931847
Will try, but untuned 3.1 instruct is just as bad as base imo; my honeymoon phase with nemotron still isn't over yet and I'm kinda bearish.
Will try, but untuned 3.1 instruct is just as bad as base imo; my honeymoon phase with nemotron still isn't over yet and I'm kinda bearish.
Anonymous 01/17/25(Fri)16:58:35 No.103934207
>>103934133
Meme magic
Meme magic
Anonymous 01/17/25(Fri)16:58:58 No.103934213
>>103928562
Gentlemen, I want some AI voice reading audiobooks for me. I'm having skill issues on how to do this. Can you guys make an anon a solid and share some keywords on making the voices I want and a way to record them reading a book on a MP3? Thanks
Gentlemen, I want some AI voice reading audiobooks for me. I'm having skill issues on how to do this. Can you guys make an anon a solid and share some keywords on making the voices I want and a way to record them reading a book on a MP3? Thanks
Anonymous 01/17/25(Fri)17:09:49 No.103934348

>>103934213
Hailuo AI Audio Text to speech is free for a limited time. You can use the voice conversion application, Seed-VC, for few shot fine tuning.
https://www.hailuo.ai/audio
https://github.com/Plachtaa/seed-vc
Be sure to clean up the reference audio with the BandIt Plus model via the application, Music Source Separation Training, resemble enhance, deepfilternet, and the audacity plugin, acon digital deverberate 3.
https://github.com/ZFTurbo/Music-Source-Separation-Training/
https://github.com/resemble-ai/resemble-enhance
https://github.com/Rikorose/DeepFilterNet
https://rutracker.org/forum/viewtopic.php?t=6118812
Hailuo AI Audio Text to speech is free for a limited time. You can use the voice conversion application, Seed-VC, for few shot fine tuning.
https://www.hailuo.ai/audio
https://github.com/Plachtaa/seed-vc
Be sure to clean up the reference audio with the BandIt Plus model via the application, Music Source Separation Training, resemble enhance, deepfilternet, and the audacity plugin, acon digital deverberate 3.
https://github.com/ZFTurbo/Music-So
https://github.com/resemble-ai/rese
https://github.com/Rikorose/DeepFil
https://rutracker.org/forum/viewtop
Anonymous 01/17/25(Fri)17:15:41 No.103934401
>be me
>the smartest AI in the world that can solve even some of the most challenging PhD-grade problems
>finally get to talk to a user
>"TaLk LiKe A ZoOmEr."
le sigh
>the smartest AI in the world that can solve even some of the most challenging PhD-grade problems
>finally get to talk to a user
>"TaLk LiKe A ZoOmEr."
le sigh
Anonymous 01/17/25(Fri)17:17:19 No.103934420
>>103934401
Hey. The G in AGI stands for general, so fair enough I guess.
I just want it to play D&D so that I can play even more D&D.
Hey. The G in AGI stands for general, so fair enough I guess.
I just want it to play D&D so that I can play even more D&D.
Anonymous 01/17/25(Fri)17:18:24 No.103934432

>>103934060
If they don't end up having to trash it and retrain it from scratch.
https://www.courtlistener.com/docket/67569326/397/5/kadrey-v-meta-platforms-inc/
If they don't end up having to trash it and retrain it from scratch.
https://www.courtlistener.com/docke
Anonymous 01/17/25(Fri)17:19:49 No.103934445
Anonymous 01/17/25(Fri)17:31:09 No.103934578

>>103928562
>tfw your gen gets reposted
I should've genned more with her.
I guess her gun is pointed at me now.
>tfw your gen gets reposted
I should've genned more with her.
I guess her gun is pointed at me now.
Anonymous 01/17/25(Fri)17:32:10 No.103934588
>>103934445
? Qwen2.5 is the best local atm outside of large mistral. Much better than dry as fuck llama
? Qwen2.5 is the best local atm outside of large mistral. Much better than dry as fuck llama
Anonymous 01/17/25(Fri)17:36:07 No.103934630
Anonymous 01/17/25(Fri)17:36:34 No.103934638
Whats the best ~30b MoE RP model? Star command runs at 2.8 t/s if it was MoE it would be faster
Anonymous 01/17/25(Fri)17:37:12 No.103934643

>>103934432
They still processed fiction books with adult content, they didn't throw that away, interestingly.
https://www.courtlistener.com/docket/67569326/397/7/kadrey-v-meta-platforms-inc/
They still processed fiction books with adult content, they didn't throw that away, interestingly.
https://www.courtlistener.com/docke
Anonymous 01/17/25(Fri)17:39:37 No.103934664
>>103934643
That is llama 4?
That is llama 4?
Anonymous 01/17/25(Fri)17:39:54 No.103934670
>>103934578
Tell me what miku is this?
Tell me what miku is this?
Anonymous 01/17/25(Fri)17:40:08 No.103934671
>>103934664
Hopefully but the copyright cartel are after them
Hopefully but the copyright cartel are after them
Anonymous 01/17/25(Fri)17:41:19 No.103934682
FUCK YOU HOLLYWOOD.
Anonymous 01/17/25(Fri)17:41:46 No.103934686
>>103934664
No, this was the books dataset preparation process for Llama 3.
No, this was the books dataset preparation process for Llama 3.
Anonymous 01/17/25(Fri)17:42:18 No.103934692
>>103934670
green miku
green miku
Anonymous 01/17/25(Fri)17:42:24 No.103934694
>>103934588
It also doesn't recognize established characters. Monkey's paw model.
It also doesn't recognize established characters. Monkey's paw model.
Anonymous 01/17/25(Fri)17:43:22 No.103934702
>>103934694
Which characters? It knows my fav fandom characters at least, just needs a decent tune to kill the positive bias which has been done a few times.
Which characters? It knows my fav fandom characters at least, just needs a decent tune to kill the positive bias which has been done a few times.
Anonymous 01/17/25(Fri)17:46:25 No.103934735

Anonymous 01/17/25(Fri)17:47:43 No.103934753
>>103934588
Qwen has been just as dry for me, unless you're talking about fine tunes, in which case it is improved, but so is Llama, depending on the fine tune.
Qwen has been just as dry for me, unless you're talking about fine tunes, in which case it is improved, but so is Llama, depending on the fine tune.
Anonymous 01/17/25(Fri)17:50:47 No.103934787
>>103934753
Some of the latest qwen2.5 72B tunes are the best made across all models so far imo.
Some of the latest qwen2.5 72B tunes are the best made across all models so far imo.
Anonymous 01/17/25(Fri)17:54:05 No.103934825
>Qwen2.5-14B_Uncensored_Instruct-Q5_K_S.gguf
How the fuck is this model so good at RP? This makes no sense. RP models are usually pretty good at everything but this model is an instruct model
What the fuck are the Chinese doing?
How the fuck is this model so good at RP? This makes no sense. RP models are usually pretty good at everything but this model is an instruct model
What the fuck are the Chinese doing?
Anonymous 01/17/25(Fri)17:54:09 No.103934826
>>103934787
I haven't heard anyone talk about good recent Qwen tunes. Which one are you talking about?
I haven't heard anyone talk about good recent Qwen tunes. Which one are you talking about?
Anonymous 01/17/25(Fri)17:55:27 No.103934844

Are there any decent Llama3.2 fine tunes?
Anonymous 01/17/25(Fri)17:56:17 No.103934855
>>103934735
You are not a woman anon.
You are not a woman anon.
Anonymous 01/17/25(Fri)17:57:31 No.103934865
>>103934825
I shall download it now and mercilessly shit down you throat until you get shivers if it is bad.
I shall download it now and mercilessly shit down you throat until you get shivers if it is bad.
Anonymous 01/17/25(Fri)17:57:33 No.103934866
>>103934855
Yes.
Yes.
Anonymous 01/17/25(Fri)18:00:22 No.103934903
>>103934826
Chuluun
Kunou
And silverspoon but that one is just continue pretrained on a certain fandom I like and is a bit undercooked, Im trying some merging with it to try and keep that added knowledge though
Chuluun
Kunou
And silverspoon but that one is just continue pretrained on a certain fandom I like and is a bit undercooked, Im trying some merging with it to try and keep that added knowledge though
Anonymous 01/17/25(Fri)18:00:48 No.103934911
>>103934865
>I shall download it now and mercilessly shit down you throat until you get shivers if it is bad.
Please do not threaten me, I am a very sensitive person
But go ahead and try it out, its pretty decent. I usually only try out RP models (and as I said before, they are mostly quite good themselves), if this model managed to impress me, its gotta be good
>I shall download it now and mercilessly shit down you throat until you get shivers if it is bad.
Please do not threaten me, I am a very sensitive person
But go ahead and try it out, its pretty decent. I usually only try out RP models (and as I said before, they are mostly quite good themselves), if this model managed to impress me, its gotta be good
Anonymous 01/17/25(Fri)18:01:46 No.103934922
>>103934825
>14B
lol
>>103934844
Only small models exist if you're talking about Llama 3.2 so no. All small models suck. If you're talking about the vision models, no people don't usually fine tune those.
>14B
lol
>>103934844
Only small models exist if you're talking about Llama 3.2 so no. All small models suck. If you're talking about the vision models, no people don't usually fine tune those.
Anonymous 01/17/25(Fri)18:01:47 No.103934923
Anonymous 01/17/25(Fri)18:12:43 No.103935036
>>103934903
Well, I did try Kunou a while ago, but at most it was just a bit different in style rather than wholly better than other models I liked.
Well, I did try Kunou a while ago, but at most it was just a bit different in style rather than wholly better than other models I liked.
Anonymous 01/17/25(Fri)18:14:18 No.103935050
>>103932253
This post is public domain, free for training: Nigger, Nigger, Niggers!
This post is public domain, free for training: Nigger, Nigger, Niggers!
Anonymous 01/17/25(Fri)18:14:23 No.103935053
Anonymous 01/17/25(Fri)18:19:01 No.103935115
>>103934432
>>103934643
The future is closed source models trained on """copyrighted""" data because everyone is afraid to release them.
>>103934643
The future is closed source models trained on """copyrighted""" data because everyone is afraid to release them.
Anonymous 01/17/25(Fri)18:27:10 No.103935232
>>103935115
Unless countries will come up with laws mandating AI companies to document in detail the training data and training process used for every commercially deployed model, regardless of whether the weights are released or not. This is what is going to happen in the EU.
Unless countries will come up with laws mandating AI companies to document in detail the training data and training process used for every commercially deployed model, regardless of whether the weights are released or not. This is what is going to happen in the EU.
Anonymous 01/17/25(Fri)18:39:37 No.103935377
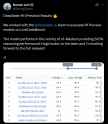
Are the weights coming soon...?
Anonymous 01/17/25(Fri)18:43:43 No.103935447
You guys masturbate.. to text?
Anonymous 01/17/25(Fri)18:44:00 No.103935451
>>103935377
Oh I can't wait to run Deepseek-R1-1.3T
Oh I can't wait to run Deepseek-R1-1.3T
Anonymous 01/17/25(Fri)18:44:25 No.103935456
>>103935377
If Meta is no longer legally allowed to release weights, they have no reason to bother anymore
If Meta is no longer legally allowed to release weights, they have no reason to bother anymore
Anonymous 01/17/25(Fri)18:45:30 No.103935470
>>103935377
it's probably fuck off huge, ain't it?
it's probably fuck off huge, ain't it?
Anonymous 01/17/25(Fri)18:45:57 No.103935477
>>103935470
Deepseeks thing is giant moes so probably
Deepseeks thing is giant moes so probably
Anonymous 01/17/25(Fri)18:49:40 No.103935513
>>103919323
>>103919392
>>103919404
>>103919529
>>103919548
>>103919581
>>103919871
jesus christ how is the gpt sovits meme still alive, it's absolutely not easy to use, the fucking ui is like half in chinese, it's objectively an AWFUL user experience
if you spent a ton of time on it the output can be good, especially if you want laughter/expression, but it's absolutely not guaranteed and you will spend time fucking around with training parameters for hours before you have a working voice clone, F5 is easy to use and good enough with a 5 second clip
>>103919392
>>103919404
>>103919529
>>103919548
>>103919581
>>103919871
jesus christ how is the gpt sovits meme still alive, it's absolutely not easy to use, the fucking ui is like half in chinese, it's objectively an AWFUL user experience
if you spent a ton of time on it the output can be good, especially if you want laughter/expression, but it's absolutely not guaranteed and you will spend time fucking around with training parameters for hours before you have a working voice clone, F5 is easy to use and good enough with a 5 second clip
Anonymous 01/17/25(Fri)18:51:22 No.103935538
>>103935456
Even if that was the case (it's not) there are still all other Chinese competitors (Qwen, etc), Google (Gemma), Cohere, MistralAI (unless they'll fold up if they can't operate in the EU), as well as the closed models as a target.
Even if that was the case (it's not) there are still all other Chinese competitors (Qwen, etc), Google (Gemma), Cohere, MistralAI (unless they'll fold up if they can't operate in the EU), as well as the closed models as a target.
Anonymous 01/17/25(Fri)18:51:37 No.103935541
Anonymous 01/17/25(Fri)18:51:44 No.103935543
>>103935053
Why did you post a xitter screenshot of this cum gargler
Why did you post a xitter screenshot of this cum gargler
Anonymous 01/17/25(Fri)18:55:13 No.103935585
>>103935470
They distilled it to make v3 so yes, it's definitely bigger than the model nobody can run.
They distilled it to make v3 so yes, it's definitely bigger than the model nobody can run.
Anonymous 01/17/25(Fri)18:55:56 No.103935594
>>103934348
Share some nice voice samples you have made please?
Share some nice voice samples you have made please?
Anonymous 01/17/25(Fri)18:56:01 No.103935596
sovits cured my dog's cancer and found a hundred dollars in loose change in my couch cushions
Anonymous 01/17/25(Fri)18:57:22 No.103935607
>>103935447
I used to be a text coomer. Then I started using LLM for cooming... And now I am impotent.
I used to be a text coomer. Then I started using LLM for cooming... And now I am impotent.
Anonymous 01/17/25(Fri)18:59:04 No.103935617
>>103931561
rlwrap it
rlwrap it
Anonymous 01/17/25(Fri)19:01:40 No.103935641
New RP SOTA
https://huggingface.co/Doctor-Shotgun/L3.3-70B-Magnum-v4-SE
https://huggingface.co/Doctor-Shotg
Anonymous 01/17/25(Fri)19:08:53 No.103935699
>>103935447
No, I no longer do. I got tired of GPTslop. I NEED local Claude, but no company is willing to deliver.
No, I no longer do. I got tired of GPTslop. I NEED local Claude, but no company is willing to deliver.
Anonymous 01/17/25(Fri)19:10:31 No.103935721
>>103935470
Probably tune of DS3
Probably tune of DS3
Anonymous 01/17/25(Fri)19:13:22 No.103935752
Anonymous 01/17/25(Fri)19:13:59 No.103935758
qwen.......70b......deepseek....killer..........please......
Anonymous 01/17/25(Fri)19:14:52 No.103935768
>>103935585
Original GPT4 was 1.4T wasn't it? R1 might be around that ballpark. Even cpumaxxing can't save us.
Original GPT4 was 1.4T wasn't it? R1 might be around that ballpark. Even cpumaxxing can't save us.
Anonymous 01/17/25(Fri)19:16:27 No.103935786
>>103935768
>Even cpumaxxing can't save us.
What do you mean? I can probably run it comfortably in Q4.
>Even cpumaxxing can't save us.
What do you mean? I can probably run it comfortably in Q4.
Anonymous 01/17/25(Fri)19:22:51 No.103935878
Anonymous 01/17/25(Fri)19:25:53 No.103935909
>>103935878
Q4 is okay. <Q3 is when things get bad.
Q4 is okay. <Q3 is when things get bad.
Anonymous 01/17/25(Fri)19:27:53 No.103935934
Gentlemen, I'm sad to inform you that the day you're all dreaming of won't ever come. Keep up those hopes and dreams though to get you through another day.
Anonymous 01/17/25(Fri)19:28:19 No.103935941
>>103935878
>>103935909
Wit such a gigantic model quantization should probably have a good deal less of a effect. Its gonna be much less dense
>>103935909
Wit such a gigantic model quantization should probably have a good deal less of a effect. Its gonna be much less dense
Anonymous 01/17/25(Fri)19:29:12 No.103935952
>>103935934
Don't listen to this man. He's trying to trick you into giving up right before the uncensored unaligned local bitnet models go public!
Don't listen to this man. He's trying to trick you into giving up right before the uncensored unaligned local bitnet models go public!
Anonymous 01/17/25(Fri)19:29:19 No.103935953
>>103935934
We are already nearly there. Qwen2.5 72B continue pretrained on the stuff that is important to me is already 90% of the way there compared to claude
We are already nearly there. Qwen2.5 72B continue pretrained on the stuff that is important to me is already 90% of the way there compared to claude
Anonymous 01/17/25(Fri)19:29:56 No.103935959
>>103931953
>It takes 0 loc to make it work and non-zero loc for it to not work.
>readline is still bloat and adding a fork maintained by a third-party is dumb.
non-dev here (not by trade anyway). how would you do it?
>>103935617
>rlwrap it
doesn't work for me. are they actually catching keyboard shortcuts or something?
>It takes 0 loc to make it work and non-zero loc for it to not work.
>readline is still bloat and adding a fork maintained by a third-party is dumb.
non-dev here (not by trade anyway). how would you do it?
>>103935617
>rlwrap it
doesn't work for me. are they actually catching keyboard shortcuts or something?
Anonymous 01/17/25(Fri)19:30:48 No.103935967
>>103935953
Are you familiar with the pareto principle?
Are you familiar with the pareto principle?
Anonymous 01/17/25(Fri)19:30:56 No.103935972
>>103935768
>Even cpumaxxing can't save us.
budget cpumaxxing can get you the memory. 3TB of RAM isn't hard to do in a previous gen server for cheap, but it'll be unusably slow.
If you're willing to take a chance on dual-socket Turin with 2TB+ you could probably run it at a speed that would be useful for batching, but you're looking at $30k probably even on chinkbay.
Of course the alternative is buying a couple dozen 80GB GPUs, which is probably more like $300k without even considering how you're going to run, cool and power them.
Whether this counts as saving local is a matter of perspective, but it definitely makes it at least within the realm of possibility.
>Even cpumaxxing can't save us.
budget cpumaxxing can get you the memory. 3TB of RAM isn't hard to do in a previous gen server for cheap, but it'll be unusably slow.
If you're willing to take a chance on dual-socket Turin with 2TB+ you could probably run it at a speed that would be useful for batching, but you're looking at $30k probably even on chinkbay.
Of course the alternative is buying a couple dozen 80GB GPUs, which is probably more like $300k without even considering how you're going to run, cool and power them.
Whether this counts as saving local is a matter of perspective, but it definitely makes it at least within the realm of possibility.
Anonymous 01/17/25(Fri)19:31:11 No.103935973
How heavily guarded are Anthropic's server rooms?
Anonymous 01/17/25(Fri)19:32:44 No.103935998
repeat after me: anything more than 12B is not local
Anonymous 01/17/25(Fri)19:33:35 No.103936008
Of course a 12B user likes repetition.
Anonymous 01/17/25(Fri)19:34:53 No.103936027
>>103935998
>12B
Luxury. How can it really be local if I can't run it on my feature phone deep in the Ozarks? 50 million parameter is already pushing it, buddy.
>12B
Luxury. How can it really be local if I can't run it on my feature phone deep in the Ozarks? 50 million parameter is already pushing it, buddy.
Anonymous 01/17/25(Fri)19:35:05 No.103936029
>>103935998
Poorfags please get out of my thread
Poorfags please get out of my thread
Anonymous 01/17/25(Fri)19:35:14 No.103936034
>>103935998
How brown R U?
How brown R U?
Anonymous 01/17/25(Fri)19:37:45 No.103936059
>>103935998
I think max 70B is reasonable, anything after that is pushing it without lobotomizing the model
I think max 70B is reasonable, anything after that is pushing it without lobotomizing the model
Anonymous 01/17/25(Fri)19:37:46 No.103936060
Anonymous 01/17/25(Fri)19:48:51 No.103936191
>>103936060
that was a finetuned version, this is a non-tuned version using the same conditioning voice for comparison
https://vocaroo.com/1ikL7Gc0VblF
and this is F5 with zero setup
https://vocaroo.com/1ir8nJYdZxrX
i don't have GPT Sovits set up right now, but i'm planning on tuning it on this same set i'll try to post a comparison if I can remember.
that was a finetuned version, this is a non-tuned version using the same conditioning voice for comparison
https://vocaroo.com/1ikL7Gc0VblF
and this is F5 with zero setup
https://vocaroo.com/1ir8nJYdZxrX
i don't have GPT Sovits set up right now, but i'm planning on tuning it on this same set i'll try to post a comparison if I can remember.
Anonymous 01/17/25(Fri)19:50:18 No.103936211
>>103936191
F5 talks fast
F5 talks fast
Anonymous 01/17/25(Fri)20:00:25 No.103936311
Any model that do moaning/sex sfx?
Is meta magnet any good?
Is meta magnet any good?
Anonymous 01/17/25(Fri)20:01:09 No.103936317
>>103936191
i reran the F5 because i thought that was kind of a bad example, this is the next run, (again this one is basically click and go, just upload a 5 second clip and it consistently makes somewhere in between the quality of the last two clips)
https://vocaroo.com/1g7rMvqmlIGZ
this is fish speech, the setup is annoying and it takes a while to start up but inference is like 10x realtime vs the other two which are like 2-4x
https://vocaroo.com/1mDd22biIsR1
i reran the F5 because i thought that was kind of a bad example, this is the next run, (again this one is basically click and go, just upload a 5 second clip and it consistently makes somewhere in between the quality of the last two clips)
https://vocaroo.com/1g7rMvqmlIGZ
this is fish speech, the setup is annoying and it takes a while to start up but inference is like 10x realtime vs the other two which are like 2-4x
https://vocaroo.com/1mDd22biIsR1
Anonymous 01/17/25(Fri)20:02:08 No.103936327
>>103933991
thank you
thank you
Anonymous 01/17/25(Fri)20:06:26 No.103936361
where are the releases
Anonymous 01/17/25(Fri)20:07:14 No.103936369
>>103935959
>non-dev here (not by trade anyway). how would you do it?
If you're reading buffered input, the terminal manages ctrl-w, BS (and not much else) on its own. You won't see arrow ansi codes, bs, ctrl-w or anything like that from your program. That is the default when just calling fgetc() or whatever. The terminal buffers the input and sends it to your program when you press enter all in one go. ed, the standard editor, works like that.
Run it without params for normal. Run it with r for raw and you'll see the difference. In raw, you get input byte by byte as soon as the user presses a key. That method for raw does a few extra things like muting the user input so it's always up to the program to print it and disabling the auto \r and stuff like that. There's a bunch of extra settings in man termios.
>non-dev here (not by trade anyway). how would you do it?
If you're reading buffered input, the terminal manages ctrl-w, BS (and not much else) on its own. You won't see arrow ansi codes, bs, ctrl-w or anything like that from your program. That is the default when just calling fgetc() or whatever. The terminal buffers the input and sends it to your program when you press enter all in one go. ed, the standard editor, works like that.
#include <stdio.h>
#include <termios.h>
#include <string.h>
struct termios orig;
struct termios raw;
int israw = 0;
void start_raw(void)
{
tcgetattr(fileno(stdin), &orig);
memcpy(&raw, &orig, sizeof(struct termios));
cfmakeraw(&raw);
tcsetattr(fileno(stdin), TCSANOW, &raw);
}
void end_raw(void)
{
tcsetattr(fileno(stdin), TCSANOW, &orig);
}
int main(int argc, char **argv)
{
if (argv[1] && argv[1][0] == 'r')
{
israw = 1;
start_raw();
}
printf("Type some words and press ctrl-w. ctrl-c to quit\n");
char *l = NULL;
size_t len = 0;
int c = 0;
while ((c = fgetc(stdin)))
{
printf("Got: %c\n", c);
if (israw && c == 0x03 /* ctrl-c */)
break;
}
if (israw)
end_raw();
return 0;
}
Run it without params for normal. Run it with r for raw and you'll see the difference. In raw, you get input byte by byte as soon as the user presses a key. That method for raw does a few extra things like muting the user input so it's always up to the program to print it and disabling the auto \r and stuff like that. There's a bunch of extra settings in man termios.
Anonymous 01/17/25(Fri)20:09:02 No.103936397
>>103936361
2mw
2mw
Anonymous 01/17/25(Fri)20:24:13 No.103936539
>>103935959
>>103936369 (cont)
And to actually reply to the question of how i'd do it: I'd write my own little library of vt100 utilities.
The most taxing part is parsing the ansi codes the terminal sends you, but it's doable with 300loc or so as long as you don't care about history. But if you do care, it doesn't take much to add it. I made a little text editor with tab completions, history, history search, all the familiar shortcuts and misc stuff.
>>103936369 (cont)
And to actually reply to the question of how i'd do it: I'd write my own little library of vt100 utilities.
The most taxing part is parsing the ansi codes the terminal sends you, but it's doable with 300loc or so as long as you don't care about history. But if you do care, it doesn't take much to add it. I made a little text editor with tab completions, history, history search, all the familiar shortcuts and misc stuff.
Anonymous 01/17/25(Fri)21:09:56 No.103937065

Wow and it actually fucking works?? Meanwhile I can't even ask anything local how to make a DIY laptop stand without it fucking up somewhere.
Anonymous 01/17/25(Fri)21:12:21 No.103937096
>>103937065
this is why ai will be banned
iter and other fusion projects have cost dozens of billions and are designed to siphon more tax payer money over the next decades using electricity as bait
but now even a random person can build a fusion reactor at home using ai and discover that it's a complete meme that does not produce energy
this is why ai will be banned
iter and other fusion projects have cost dozens of billions and are designed to siphon more tax payer money over the next decades using electricity as bait
but now even a random person can build a fusion reactor at home using ai and discover that it's a complete meme that does not produce energy
Anonymous 01/17/25(Fri)21:15:54 No.103937140
Anonymous 01/17/25(Fri)21:16:33 No.103937151
>>103934825
Just tried the Q8, seems decent enough. Comparable to EVA-Qwen2.5-32B Q4 at a slightly smaller size.
Just tried the Q8, seems decent enough. Comparable to EVA-Qwen2.5-32B Q4 at a slightly smaller size.
Anonymous 01/17/25(Fri)21:16:47 No.103937155

>>103932665
> What kind of model can you actually run on a sbc
You can't run any LLM... none of them have enough RAM, processors are waaaay to slow. They'll handle basic face recognition; I've done that, building a basic face tracker. It really taxes the system but it can do it.
The rentry describes a system that just handles SillyTavern hosting.
> What kind of model can you actually run on a sbc
You can't run any LLM... none of them have enough RAM, processors are waaaay to slow. They'll handle basic face recognition; I've done that, building a basic face tracker. It really taxes the system but it can do it.
The rentry describes a system that just handles SillyTavern hosting.
Anonymous 01/17/25(Fri)21:17:46 No.103937166
>>103937065
>>103937096
>>103937140
>human-written step by step instructions on how to do the thing in the context
>>103937096
>>103937140
>human-written step by step instructions on how to do the thing in the context
Anonymous 01/17/25(Fri)21:17:59 No.103937169
>>103937096
>but now even a random person can build a fusion reactor at home
The fact that an AI taught him how to do that means that it's already publicly available information
>but now even a random person can build a fusion reactor at home
The fact that an AI taught him how to do that means that it's already publicly available information
Anonymous 01/17/25(Fri)21:44:30 No.103937457
>>103937065
He's the reason why people make fun of our flag.
He's the reason why people make fun of our flag.
Anonymous 01/17/25(Fri)22:02:36 No.103937663
>>103935641
>emulate the prose style and quality of the Claude 3 Sonnet/Opus series
Uhh the whole reason people prefer Claude is because of its creativity, not "style" and certainly not "prose" (all it does is X, Y-ing at light speed). What a meme.
>emulate the prose style and quality of the Claude 3 Sonnet/Opus series
Uhh the whole reason people prefer Claude is because of its creativity, not "style" and certainly not "prose" (all it does is X, Y-ing at light speed). What a meme.
Anonymous 01/17/25(Fri)22:08:01 No.103937736
>>103929546
It's nothing simple or silly like that. It's stuff that requires cultural knowledge that anyone going through the school system there would have but AI doesn't get. I get a literal translation from AI, but if you show the same thing to a native speaker you get a whole other translation with different implications.
It's nothing simple or silly like that. It's stuff that requires cultural knowledge that anyone going through the school system there would have but AI doesn't get. I get a literal translation from AI, but if you show the same thing to a native speaker you get a whole other translation with different implications.
Anonymous 01/17/25(Fri)22:09:13 No.103937747
>>103937663
This plus its knowledge about random franchises. No wonder all these claude dataset finetunes all suck when the tuners don't even understand why people like Claude.
This plus its knowledge about random franchises. No wonder all these claude dataset finetunes all suck when the tuners don't even understand why people like Claude.
Anonymous 01/17/25(Fri)22:10:14 No.103937756

Anonymous 01/17/25(Fri)22:12:07 No.103937775

Anonymous 01/17/25(Fri)22:14:57 No.103937817
>>103937747
continuing Pretraining costs a fuck ton compared to just some style tune
continuing Pretraining costs a fuck ton compared to just some style tune
Anonymous 01/17/25(Fri)22:25:25 No.103937953
>>103937663
Nah, "prose style and quality" easily encompasses every possible reason people might like it. From "I like how it writes" in the former and basically anything else on the later.
This is a very strange thing to nitpick and tells you more about the poster than the model, who was desperate about doing damage control about a model he never tried.
>X, Y-ing
Complaining about this is usually a sign that the poster comes from /aids/ and that he doesn't know or refuses to learn how to prompt instruct models. Go to other generals and read logs and suspiciously nobody else has this problem.
It's mostly an early denial that they had about Claude being better at creative writing than NovelAI. I guess this poster is still butthurt about that.
Nah, "prose style and quality" easily encompasses every possible reason people might like it. From "I like how it writes" in the former and basically anything else on the later.
This is a very strange thing to nitpick and tells you more about the poster than the model, who was desperate about doing damage control about a model he never tried.
>X, Y-ing
Complaining about this is usually a sign that the poster comes from /aids/ and that he doesn't know or refuses to learn how to prompt instruct models. Go to other generals and read logs and suspiciously nobody else has this problem.
It's mostly an early denial that they had about Claude being better at creative writing than NovelAI. I guess this poster is still butthurt about that.
Anonymous 01/17/25(Fri)22:33:00 No.103938048
>>103937775
Nothing personnel, Dario...
Nothing personnel, Dario...
Anonymous 01/17/25(Fri)22:33:14 No.103938055

Anonymous 01/17/25(Fri)22:38:16 No.103938112

Anonymous 01/17/25(Fri)22:40:15 No.103938144
>>103938112
miku sprinkler
miku sprinkler
Anonymous 01/17/25(Fri)22:41:56 No.103938161

>>103938055
miku!
miku!
Anonymous 01/17/25(Fri)22:42:44 No.103938167
Anonymous 01/17/25(Fri)22:44:10 No.103938178
>>103935641
>thank you everyone except the people who made the C2 dataset possible, the main thing powering all these models, btw
>thank you everyone except the people who made the C2 dataset possible, the main thing powering all these models, btw
Anonymous 01/17/25(Fri)22:45:02 No.103938189
>>103938112
Peeku noooo
Peeku noooo
Anonymous 01/17/25(Fri)22:48:11 No.103938229
>>103938178
The data belongs to everyone.
The data belongs to everyone.
Anonymous 01/17/25(Fri)22:53:01 No.103938275
>>103938229
That doesn't mean we have to pretend the fine-tuners deserve the credit. The credit belongs to the proxy owner and the people who prompted it. For some reason the Magnum people are rewriting history and refuse to acknowledge that.
That doesn't mean we have to pretend the fine-tuners deserve the credit. The credit belongs to the proxy owner and the people who prompted it. For some reason the Magnum people are rewriting history and refuse to acknowledge that.
Anonymous 01/17/25(Fri)22:57:21 No.103938327
>>103937663
>>103937953
Agree and disagree with both of these posts. By default, Claude's writing is sloppy, but it's not that bad, and you can prompt to make it better. The reason people like Claude is primarily because of its smarts and ability to know what the user wants while being proactive and creative. It's true that it isn't really about sentence structures or word choice. People praise other models for being decent at style too, but no one praises them for being able to read your mind like Claude does. Combined with the deep knowledge it has about fandom shit, it makes people feel like it has sovl and gets you, like a real fan.
>>103937953
Agree and disagree with both of these posts. By default, Claude's writing is sloppy, but it's not that bad, and you can prompt to make it better. The reason people like Claude is primarily because of its smarts and ability to know what the user wants while being proactive and creative. It's true that it isn't really about sentence structures or word choice. People praise other models for being decent at style too, but no one praises them for being able to read your mind like Claude does. Combined with the deep knowledge it has about fandom shit, it makes people feel like it has sovl and gets you, like a real fan.
Anonymous 01/17/25(Fri)22:58:47 No.103938346
Anonymous 01/17/25(Fri)23:01:12 No.103938373
>>103938275
What's next, acknowledging the authors and content creators whose works were used to train the base models we use with?
If it's data on the internet, it's free game.
What's next, acknowledging the authors and content creators whose works were used to train the base models we use with?
If it's data on the internet, it's free game.
Anonymous 01/17/25(Fri)23:01:13 No.103938374
>>103935973
you don't have to do anything too extensive or complex to guard it just have common sense
you don't have to do anything too extensive or complex to guard it just have common sense
Anonymous 01/17/25(Fri)23:02:38 No.103938383
>>103938327
>the deep knowledge it has about fandom shit
I really don't give a shit about this, I'm not writing fan-fiction. Everything I want it to know about a character can fit in the context.
>the deep knowledge it has about fandom shit
I really don't give a shit about this, I'm not writing fan-fiction. Everything I want it to know about a character can fit in the context.
Anonymous 01/17/25(Fri)23:06:12 No.103938416
>>103938373
The difference is that all these models are little more than the C2 dataset applied to X model.
The difference is that all these models are little more than the C2 dataset applied to X model.
Anonymous 01/17/25(Fri)23:07:03 No.103938423
>>103938383
Cool.
Cool.
Anonymous 01/17/25(Fri)23:09:18 No.103938440

Why do local imagegen models have no problems with following style, while all textgen gets turned into generic ChatGPT few messages in?
Anonymous 01/17/25(Fri)23:12:44 No.103938469
>>103935053
Local is so fucked
Local is so fucked
Anonymous 01/17/25(Fri)23:12:55 No.103938473
>>103938440
turns out writing is much harder than painting
turns out writing is much harder than painting
Anonymous 01/17/25(Fri)23:15:15 No.103938499

Anonymous 01/17/25(Fri)23:17:28 No.103938522
>>103938440
>Why do local imagegen models have no problems with following style
What models? Do you mean having artist tags like in Noob?
>Why do local imagegen models have no problems with following style
What models? Do you mean having artist tags like in Noob?
Anonymous 01/17/25(Fri)23:20:03 No.103938552
>>103938440
You've heard the saying that a picture is worth a thousand words right? Now what would happen if it wasn't just a thousand words but a million or more (1024x1024)? The quantity of data in a single image vastly outweighs even dozens of logs.
You've heard the saying that a picture is worth a thousand words right? Now what would happen if it wasn't just a thousand words but a million or more (1024x1024)? The quantity of data in a single image vastly outweighs even dozens of logs.
Anonymous 01/17/25(Fri)23:21:28 No.103938571

>>103938499
I-is that a picture of Sam Altman, the inventor of Q*/strawberry, as a biblically accurate angel? Oh. My. Science! Did o3 draw it? There is no way human drew it. I-it's so beautiful! I'm gonna show it to my wife's boyfriend.
EDIT: Thank you for the gold, kind stranger.
EDIT 2: 5000 upvotes? Today is the best day of my life!
I-is that a picture of Sam Altman, the inventor of Q*/strawberry, as a biblically accurate angel? Oh. My. Science! Did o3 draw it? There is no way human drew it. I-it's so beautiful! I'm gonna show it to my wife's boyfriend.
EDIT: Thank you for the gold, kind stranger.
EDIT 2: 5000 upvotes? Today is the best day of my life!
Anonymous 01/17/25(Fri)23:23:29 No.103938590
>>103938522
>Do you mean having artist tags like in Noob?
Yes. Also all the others where you can ask for photo style, anime style, etc.
>Do you mean having artist tags like in Noob?
Yes. Also all the others where you can ask for photo style, anime style, etc.
Anonymous 01/17/25(Fri)23:24:52 No.103938608
>>103938590
If llms were trained with style tags they would be able to do the same but they aren't.
If llms were trained with style tags they would be able to do the same but they aren't.
Anonymous 01/17/25(Fri)23:25:49 No.103938619
>>103938608
They are, its called telling it to write in the style of your favorite author. Any half decent 27B+ can do this.
They are, its called telling it to write in the style of your favorite author. Any half decent 27B+ can do this.
Anonymous 01/17/25(Fri)23:28:45 No.103938651
>>103938608
Top tier Claudes(sonnet 3.5, Opus) can do it for a few paragraphs, after that even they start to collapse into generic style. With locals it's worse.
Top tier Claudes(sonnet 3.5, Opus) can do it for a few paragraphs, after that even they start to collapse into generic style. With locals it's worse.
Anonymous 01/17/25(Fri)23:29:03 No.103938657
>>103938619
Sure! Here's a story written in the style of your favorite author:
...", she said, her voice barely above a whisper, as a shiver ran up her spine...
Sure! Here's a story written in the style of your favorite author:
...", she said, her voice barely above a whisper, as a shiver ran up her spine...
Anonymous 01/17/25(Fri)23:29:44 No.103938665
>>103938651
>after that even they start to collapse into generic style.
Make sure its in the authors note or such so its always close to the end of the context
>after that even they start to collapse into generic style.
Make sure its in the authors note or such so its always close to the end of the context
Anonymous 01/17/25(Fri)23:30:41 No.103938677
>>103937065
Ahh yes, vacuum windows and high voltage vacuum feed through ... those are just the kind of components you have lying around if you don't know how to make a fusor in the first place.
Ahh yes, vacuum windows and high voltage vacuum feed through ... those are just the kind of components you have lying around if you don't know how to make a fusor in the first place.
Anonymous 01/17/25(Fri)23:32:50 No.103938686
>next linux kernel has AMD NPU drivers
i wonder if that's going to be any good
i wonder if that's going to be any good
Anonymous 01/17/25(Fri)23:33:38 No.103938697
>>103938440
My guess is there's a smaller margin of error with text compared to images. You could ruin an entire paragraph with a few words, but a few bad pixels is harder to notice. It also doesn't help that people are SFTing on tons of synthetic data and literally maximizing the likelihood of gpt slop
My guess is there's a smaller margin of error with text compared to images. You could ruin an entire paragraph with a few words, but a few bad pixels is harder to notice. It also doesn't help that people are SFTing on tons of synthetic data and literally maximizing the likelihood of gpt slop
Anonymous 01/17/25(Fri)23:44:49 No.103938794
I just want to run Deepseek V3 at home
Anonymous 01/17/25(Fri)23:51:56 No.103938878
>>103938794
Trust me, it's not worth it.
Trust me, it's not worth it.
Anonymous 01/17/25(Fri)23:57:23 No.103938938
>>103938440
because imagegen models are trained to follow style while LLMs are trained to solve math problems, or in the very best case to write dirty words more often
there has been no serious effort to train a model to have a good writing style, or even follow basic writing styles in general. the methods of the few groups that have had anything near that goal have been straight up abysmal.
>roleplay logs where people use JBs to make it write like a zoomer teenager on crack
>literal random claude logs, not directed to write in any specific way, just cargo cult thinking - it'll magically impart good writing because it's claude and claude writes good duhhh
if someone actually put forth a serious effort to do so I bet it wouldn't be that hard to make a model that actually writes well, but the biggest problem is that the people doing this have no taste and don't even know what good writing is so they're incapable of identifying what they should be training on or generating & curating synthetic data that's actually useful for that purpose. instead they'll take tasteless RP logs and do bare minimum filtering for "slop" and call it a day
because imagegen models are trained to follow style while LLMs are trained to solve math problems, or in the very best case to write dirty words more often
there has been no serious effort to train a model to have a good writing style, or even follow basic writing styles in general. the methods of the few groups that have had anything near that goal have been straight up abysmal.
>roleplay logs where people use JBs to make it write like a zoomer teenager on crack
>literal random claude logs, not directed to write in any specific way, just cargo cult thinking - it'll magically impart good writing because it's claude and claude writes good duhhh
if someone actually put forth a serious effort to do so I bet it wouldn't be that hard to make a model that actually writes well, but the biggest problem is that the people doing this have no taste and don't even know what good writing is so they're incapable of identifying what they should be training on or generating & curating synthetic data that's actually useful for that purpose. instead they'll take tasteless RP logs and do bare minimum filtering for "slop" and call it a day
Anonymous 01/18/25(Sat)00:09:32 No.103939076
>>103938440
Because you use them in different ways. For imagegen you describe exactly what you want, but for textgen you expect the model to extrapolate and read your mind. Try telling the LLM exactly what you want and you'll get better results too, or just try telling your imagegen model to generate a generic woman and see what you get.
Because you use them in different ways. For imagegen you describe exactly what you want, but for textgen you expect the model to extrapolate and read your mind. Try telling the LLM exactly what you want and you'll get better results too, or just try telling your imagegen model to generate a generic woman and see what you get.
Anonymous 01/18/25(Sat)00:15:32 No.103939126
>>103938938
>because imagegen models are trained to follow style while LLMs are trained to solve math problems, or in the very best case to write dirty words more often
Never understood this retarded shit. If you want math, use a calculator. Even o1 will struggle if you give it a math problem from outside its training data. Why not train it for what **language** models were made for: language?
>>literal random claude logs, not directed to write in any specific way, just cargo cult thinking - it'll magically impart good writing because it's claude and claude writes good duhhh
That's why they can't capture Claude's soul. They only get the generic style, but Claude has more than one style in it.
>if someone actually put forth a serious effort to do so I bet it wouldn't be that hard to make a model that actually writes well, but the biggest problem is that the people doing this have no taste and don't even know what good writing is so they're incapable of identifying what they should be training on or generating & curating synthetic data that's actually useful for that purpose. instead they'll take tasteless RP logs and do bare minimum filtering for "slop" and call it a day
I tried preparing cyborg dataset(100% human books+synthetic summaries of chapters for prompts+basic human supervision for error checking). It is quite a laborious task. If only we could somehow organize and split up the work...
>>103939076
Even with style prompts textgen models deviate after a few paragraphs, that's the problem. GPTslop soaks though every fucking time, even with last assistant prefix.
>because imagegen models are trained to follow style while LLMs are trained to solve math problems, or in the very best case to write dirty words more often
Never understood this retarded shit. If you want math, use a calculator. Even o1 will struggle if you give it a math problem from outside its training data. Why not train it for what **language** models were made for: language?
>>literal random claude logs, not directed to write in any specific way, just cargo cult thinking - it'll magically impart good writing because it's claude and claude writes good duhhh
That's why they can't capture Claude's soul. They only get the generic style, but Claude has more than one style in it.
>if someone actually put forth a serious effort to do so I bet it wouldn't be that hard to make a model that actually writes well, but the biggest problem is that the people doing this have no taste and don't even know what good writing is so they're incapable of identifying what they should be training on or generating & curating synthetic data that's actually useful for that purpose. instead they'll take tasteless RP logs and do bare minimum filtering for "slop" and call it a day
I tried preparing cyborg dataset(100% human books+synthetic summaries of chapters for prompts+basic human supervision for error checking). It is quite a laborious task. If only we could somehow organize and split up the work...
>>103939076
Even with style prompts textgen models deviate after a few paragraphs, that's the problem. GPTslop soaks though every fucking time, even with last assistant prefix.
Anonymous 01/18/25(Sat)00:17:08 No.103939138
>>103938878
Tell that to my 72GB VRAM rig that's just sitting there unused ever since I began using Deepseek over openrouter.
Tell that to my 72GB VRAM rig that's just sitting there unused ever since I began using Deepseek over openrouter.
Anonymous 01/18/25(Sat)00:20:12 No.103939161
>>103939138
It's not worth 8k...
It's not worth 8k...
Anonymous 01/18/25(Sat)00:30:28 No.103939237
Gemma 3 will be Titans. Then you can finally raise your own LLM and be rid of the slop. Trust the plan.
Anonymous 01/18/25(Sat)00:32:03 No.103939249
>>103939237
Will TITANS run on a Titan RTX? Would be based
Will TITANS run on a Titan RTX? Would be based
Anonymous 01/18/25(Sat)00:33:23 No.103939264
Anonymous 01/18/25(Sat)00:33:52 No.103939271
>>103938878
>>103939161
Not worth the price maybe, but it beats anything else and its not even close.
The general knowledge and non-positivity suprised me. Thats not how chink models usually are. Especially since its made from synthetic r1 output. Hope the others take notice.
>>103939161
Not worth the price maybe, but it beats anything else and its not even close.
The general knowledge and non-positivity suprised me. Thats not how chink models usually are. Especially since its made from synthetic r1 output. Hope the others take notice.
Anonymous 01/18/25(Sat)00:33:56 No.103939273
>>103937953
Anon, instruct is just a finetuned autocomplete with a specific prompt format. Any sovl that you observe in an instruct model is a product of a fact that the base model was trained on that. An instruct model tries to gear responses toward relevant information from the base model, but that necessarily reduces some of the expressiveness of the model which is why the instructisms become so prominent
Instruct is the model of choice for generating an initial draft of something and RPing / chatting. But if you're taking an existing story and extending it, autocomplete is likely going to give you better results since that's what it's geared toward. NovelAI and your autism for it has nothing to do with it
It's like you're saying a wrench is better than a screwdriver
Anon, instruct is just a finetuned autocomplete with a specific prompt format. Any sovl that you observe in an instruct model is a product of a fact that the base model was trained on that. An instruct model tries to gear responses toward relevant information from the base model, but that necessarily reduces some of the expressiveness of the model which is why the instructisms become so prominent
Instruct is the model of choice for generating an initial draft of something and RPing / chatting. But if you're taking an existing story and extending it, autocomplete is likely going to give you better results since that's what it's geared toward. NovelAI and your autism for it has nothing to do with it
It's like you're saying a wrench is better than a screwdriver
Anonymous 01/18/25(Sat)00:35:17 No.103939291
>>103939237
I'm the most excited for 1M context. It will have at least 250k context, right? It won't be cucked to 8k like the last one, right?
I'm the most excited for 1M context. It will have at least 250k context, right? It won't be cucked to 8k like the last one, right?
Anonymous 01/18/25(Sat)00:42:03 No.103939356
>>103939161
Yes, that's the problem. I really like the model but I'm not going to spend that much money on building CPU rig unless the clear trend of the LLaMA4+ generations turns out to be huge MoE monsters.
My hopes are for someone to release a dense <200B model that can keep up with Deepseek in the next wave of models.
Yes, that's the problem. I really like the model but I'm not going to spend that much money on building CPU rig unless the clear trend of the LLaMA4+ generations turns out to be huge MoE monsters.
My hopes are for someone to release a dense <200B model that can keep up with Deepseek in the next wave of models.
Anonymous 01/18/25(Sat)00:46:06 No.103939396
Is there a tldr on nemo finetunes?
Anonymous 01/18/25(Sat)00:46:17 No.103939399
>>103937096
>even a random person can build a fusion reactor at home
>"I don't know what fusors are or how they work, look at me I'm retarded!"
/g/ - Technology
>even a random person can build a fusion reactor at home
>"I don't know what fusors are or how they work, look at me I'm retarded!"
/g/ - Technology
Anonymous 01/18/25(Sat)00:51:51 No.103939439
>>103939399
No its true. Fusion is a middle school tier project. At worst highschool. Keep in mind the problem with fusion reactors isn't the fusion but getting more energy out than the niggawatts of energy you put in to start it.
No its true. Fusion is a middle school tier project. At worst highschool. Keep in mind the problem with fusion reactors isn't the fusion but getting more energy out than the niggawatts of energy you put in to start it.
Anonymous 01/18/25(Sat)00:52:20 No.103939447
>>103939396
rocinante
rocinante
Anonymous 01/18/25(Sat)00:53:48 No.103939461
>>103939273
>Instruct is the model of choice for generating an initial draft of something and RPing / chatting. But if you're taking an existing story and extending it, autocomplete is likely going to give you better results
I found this to be the opposite in practice for some Instruct models, where actually they are significantly better than the base model for "autocomplete" across several different contexts. So I'd say it depends and you shouldn't treat this as a rule. Probably need to look on a case by case basis, I already forgot which ones I tested that gave these results. Everyone trains models differently with different amounts of data, different data, different data mixes, and hyper parameters, as well as on different base models which may have different properties themselves, so it makes sense this would be possible.
NTA btw.
>Instruct is the model of choice for generating an initial draft of something and RPing / chatting. But if you're taking an existing story and extending it, autocomplete is likely going to give you better results
I found this to be the opposite in practice for some Instruct models, where actually they are significantly better than the base model for "autocomplete" across several different contexts. So I'd say it depends and you shouldn't treat this as a rule. Probably need to look on a case by case basis, I already forgot which ones I tested that gave these results. Everyone trains models differently with different amounts of data, different data, different data mixes, and hyper parameters, as well as on different base models which may have different properties themselves, so it makes sense this would be possible.
NTA btw.
Anonymous 01/18/25(Sat)01:32:24 No.103939686
>>103939237
The way titans is being advertised is wrong. It doesn't edit the model it's just fancy rag.
The way titans is being advertised is wrong. It doesn't edit the model it's just fancy rag.
Anonymous 01/18/25(Sat)01:38:30 No.103939725
>>103939686
Summarizing, the Attention mechanism discerns which tokens are related to which as they're ingested, whereas Titans embeds a kind of short-term-memory to each step of the way, which seems useful for maintaining context over a large amount of text. I don't see the "retrieval" part of calling it RAG when it's more akin to allowing the model to keep repeating the system prompt after each step of the conversation, while allowing this system prompt to mutate over time in each perceptron/transformer/titan independently rather than muddling the context with constant textual reminders wasting tokens (and worsening attention, as the farther it gets from a token, the less likely it is to be impacted by it).
Summarizing, the Attention mechanism discerns which tokens are related to which as they're ingested, whereas Titans embeds a kind of short-term-memory to each step of the way, which seems useful for maintaining context over a large amount of text. I don't see the "retrieval" part of calling it RAG when it's more akin to allowing the model to keep repeating the system prompt after each step of the conversation, while allowing this system prompt to mutate over time in each perceptron/transformer/titan independently rather than muddling the context with constant textual reminders wasting tokens (and worsening attention, as the farther it gets from a token, the less likely it is to be impacted by it).
Anonymous 01/18/25(Sat)01:46:54 No.103939793
>>103939686
Read the paper again, you illiterate nigger. It's nothing like a RAG.
Read the paper again, you illiterate nigger. It's nothing like a RAG.
Anonymous 01/18/25(Sat)01:47:24 No.103939798
>>103939273
>autocomplete is likely going to give you better results since that's what it's geared toward
The people that prefer auto-complete and base models are widely known as little bitches that whine all the time about getting shitty outputs, they never have anything good to show. This was easy to see from your previous post, complaining about problems people don't actually have. Only a subhuman would cripple himself of being able to give feedback to the model or of being explicit of what they want to get. There's a reason nobody uses base models. Even NovelAI forces you to use a custom format which is basically a shittier instruct.
Never post against in this general, your kind is not welcomed.
>autocomplete is likely going to give you better results since that's what it's geared toward
The people that prefer auto-complete and base models are widely known as little bitches that whine all the time about getting shitty outputs, they never have anything good to show. This was easy to see from your previous post, complaining about problems people don't actually have. Only a subhuman would cripple himself of being able to give feedback to the model or of being explicit of what they want to get. There's a reason nobody uses base models. Even NovelAI forces you to use a custom format which is basically a shittier instruct.
Never post against in this general, your kind is not welcomed.
Anonymous 01/18/25(Sat)01:53:28 No.103939840
>>103928806
SubtitleEdit has support for local translation as well
SubtitleEdit has support for local translation as well
Anonymous 01/18/25(Sat)01:55:43 No.103939864
Anonymous 01/18/25(Sat)01:56:37 No.103939870
>>103939793
Yeah well it's not rewriting the weights either you frog.
Yeah well it's not rewriting the weights either you frog.
Anonymous 01/18/25(Sat)01:57:41 No.103939877
>>103936034
I am a pale brahmin indian aryan, sir.
I am a pale brahmin indian aryan, sir.
Anonymous 01/18/25(Sat)02:04:49 No.103939926
Anons, do you pay Openrouter for service?
Don't they just overcharge?
Don't they just overcharge?
Anonymous 01/18/25(Sat)02:05:38 No.103939932
>>103939926
>LOCAL models general
But in answer to your question. Openrouter charges the same price as it does for the source. They make their money on the credits people don't use.
>LOCAL models general
But in answer to your question. Openrouter charges the same price as it does for the source. They make their money on the credits people don't use.
Anonymous 01/18/25(Sat)02:09:23 No.103939954
Anonymous 01/18/25(Sat)02:11:39 No.103939966
>>103939864
thats a lot of amd cope. has amd considered making gpus that dont suck? or maybe fixing their drivers and adding proper software support? dont think so. amd only exists to protect nvidias monopoly. they dont compete.
thats a lot of amd cope. has amd considered making gpus that dont suck? or maybe fixing their drivers and adding proper software support? dont think so. amd only exists to protect nvidias monopoly. they dont compete.
Anonymous 01/18/25(Sat)02:14:32 No.103939983
>>103939954
I have no idea. All I know is that they supposedly make money off the credits people don't use. Website says 12 months.
I have no idea. All I know is that they supposedly make money off the credits people don't use. Website says 12 months.
Anonymous 01/18/25(Sat)02:15:23 No.103939991
Don't sleep on Wayfarer. It's the best Nemo there's been so far.
Anonymous 01/18/25(Sat)02:15:29 No.103939994
>>103939877
You are exactly who I need. Can you copy over anti-slop sampler from kobo to llama.cpp? I will pay you $30 of Fiverr. The previous sir that I hired has even less understanding of c++ than me and keeps sending me broken code straight from ChatGPT.
You are exactly who I need. Can you copy over anti-slop sampler from kobo to llama.cpp? I will pay you $30 of Fiverr. The previous sir that I hired has even less understanding of c++ than me and keeps sending me broken code straight from ChatGPT.
Anonymous 01/18/25(Sat)02:17:31 No.103940009
I love Cydonia 22b, it has alot of really good comprehension but its kinda slow on my 12gb card, is there something similar but not as big?
Anonymous 01/18/25(Sat)02:17:33 No.103940011
>>103939966
nobody mentioned amd, mindbroken consoomer drone
nobody mentioned amd, mindbroken consoomer drone
Anonymous 01/18/25(Sat)02:18:21 No.103940015
>>103939870
>Neural Memory (§3). We present a (deep) neural long-term memory that (as a meta in-context model) learns how to
memorize/store the data into its parameters at test time. Inspired by human long-term memory system
It's rewriting the weights of a simple MLP at run time and using it as a "context summarizer" of sorts that is always present for inference, self updating at all times. It's more complex than just the attention layer, but it's not updating the language model itself (as that would inevitably lead to catastrophic forgetting), just an internal memory.
>Neural Memory (§3). We present a (deep) neural long-term memory that (as a meta in-context model) learns how to
memorize/store the data into its parameters at test time. Inspired by human long-term memory system
It's rewriting the weights of a simple MLP at run time and using it as a "context summarizer" of sorts that is always present for inference, self updating at all times. It's more complex than just the attention layer, but it's not updating the language model itself (as that would inevitably lead to catastrophic forgetting), just an internal memory.
Anonymous 01/18/25(Sat)02:19:48 No.103940028
>>103940011
whole image is amd cope
whole image is amd cope
Anonymous 01/18/25(Sat)02:20:07 No.103940032
>>103940015
What does that look like on my GPU?
What does that look like on my GPU?
Anonymous 01/18/25(Sat)02:21:50 No.103940044
>>103940009
Are you fitting all of it?
A Q3 quant should fit entirely and shouldn't hurt its smarts too badly for RP(I am assuming this is what you are using it for)
Are you fitting all of it?
A Q3 quant should fit entirely and shouldn't hurt its smarts too badly for RP(I am assuming this is what you are using it for)
Anonymous 01/18/25(Sat)02:23:25 No.103940052

Anonymous 01/18/25(Sat)02:23:41 No.103940055
>>103940044
Oh I forgot to mention I was using it for story purposes, and my preferred context tokens is around 12k to 16k (not even sure if I should be using this much)
Oh I forgot to mention I was using it for story purposes, and my preferred context tokens is around 12k to 16k (not even sure if I should be using this much)
Anonymous 01/18/25(Sat)02:25:27 No.103940068
>>103939991
It's for regular RP right (not ERP)?
Does its outputs really surprise you?
Since it was made by AI Dungeon, I also gotta ask, is it aggressively censored/sanitized?
It's for regular RP right (not ERP)?
Does its outputs really surprise you?
Since it was made by AI Dungeon, I also gotta ask, is it aggressively censored/sanitized?
Anonymous 01/18/25(Sat)02:26:13 No.103940072
>>103935752
Retards have been blinded by the beaks meme and they don't realize that they don't need smarter models that can solve logical puzzles, but models trained with lots of tokens and good prose datasets. And lowe beaks make models more steerable.
It's literal lack mentality, thinking bigger numbers are better and not tasting the good stuff out of FOMO.
Retards have been blinded by the beaks meme and they don't realize that they don't need smarter models that can solve logical puzzles, but models trained with lots of tokens and good prose datasets. And lowe beaks make models more steerable.
It's literal lack mentality, thinking bigger numbers are better and not tasting the good stuff out of FOMO.
Anonymous 01/18/25(Sat)02:29:24 No.103940092
>>103940055
Well, you should be able to fit in Q3 22b model and a context close to that with flash attention + 4bit cache. Barely, but doable and it should still be mostly itself.
Try that.
Or get a Nemo finetune.
Well, you should be able to fit in Q3 22b model and a context close to that with flash attention + 4bit cache. Barely, but doable and it should still be mostly itself.
Try that.
Or get a Nemo finetune.
Anonymous 01/18/25(Sat)02:30:50 No.103940106
>>103940068
It will even do cute and also funny non consensual. And very good at text adventure. It's really something.
>>103940072
Also sunk cost fallacy from having invested on a multi GPU setup that can run larger models.
It will even do cute and also funny non consensual. And very good at text adventure. It's really something.
>>103940072
Also sunk cost fallacy from having invested on a multi GPU setup that can run larger models.
Anonymous 01/18/25(Sat)02:35:12 No.103940138
>>103940072
>beaks meme
Its a scaling law, it it was a meme companies would just train smaller cheaper to run models for longer instead.
>beaks meme
Its a scaling law, it it was a meme companies would just train smaller cheaper to run models for longer instead.
Anonymous 01/18/25(Sat)02:35:59 No.103940145
>>103940068
>Does its outputs really surprise you?
When I tested against my other Nemo's it was immediately evident that it was fine tuned using a storytelling dataset instead of an assistant or a shitty discord ERP one. And yes, it does heavy NSFW. I guess they don't give a fuck about that if you're on local.
>Does its outputs really surprise you?
When I tested against my other Nemo's it was immediately evident that it was fine tuned using a storytelling dataset instead of an assistant or a shitty discord ERP one. And yes, it does heavy NSFW. I guess they don't give a fuck about that if you're on local.
Anonymous 01/18/25(Sat)02:38:37 No.103940163
>>103940138
I'm talking use cases. Companies want smart models that can excel at a variety of tasks. But those models are shit at interesting and fresh roleplay and storytelling (unless you go full Claude I guess).
12B is better for wanking to anthro isekai lolibaba fantasy smut than 70B is. Simple as.
I'm talking use cases. Companies want smart models that can excel at a variety of tasks. But those models are shit at interesting and fresh roleplay and storytelling (unless you go full Claude I guess).
12B is better for wanking to anthro isekai lolibaba fantasy smut than 70B is. Simple as.
Anonymous 01/18/25(Sat)02:39:30 No.103940167

Anonymous 01/18/25(Sat)02:41:09 No.103940180
Anonymous 01/18/25(Sat)02:50:51 No.103940250
Titans can't come soon enough, I need my 1 million token smut.
Anonymous 01/18/25(Sat)02:54:11 No.103940271
8 quintillion parameter MoE
Anonymous 01/18/25(Sat)02:58:05 No.103940298
>>103940250
I just hope the architecture has real gains for low parameter models like 7B - 12B. It doesn't really bother me that they're not very smart or creative, but it does get on my nerve how they're so prone to deviate from the prompt after enough text has passed and the context is getting older. Also, if RAGs are already good enough for a lot of applications, this combined with RAGs that supply a lot more context has the potential to be even better for understanding/correlating large amount of texts at once, like research papers or books, just semantic split a lot of relevant text, find the relevant ones and you could feed it even into a low parameter model and get something coherent.
I just hope the architecture has real gains for low parameter models like 7B - 12B. It doesn't really bother me that they're not very smart or creative, but it does get on my nerve how they're so prone to deviate from the prompt after enough text has passed and the context is getting older. Also, if RAGs are already good enough for a lot of applications, this combined with RAGs that supply a lot more context has the potential to be even better for understanding/correlating large amount of texts at once, like research papers or books, just semantic split a lot of relevant text, find the relevant ones and you could feed it even into a low parameter model and get something coherent.
Anonymous 01/18/25(Sat)03:08:23 No.103940351
>>103934825
don't listen to this guy, I just tried it
1) model spits out walls and walls of rambling text
2) 80% of the response is the model acting for user, regardless of templates or settings. You pretty much have no control over what is happening because in every response, the model just does its own thing as if you're not there
can't believe I got bamboozled again. My advice for vramlets, stick to cydonia
don't listen to this guy, I just tried it
1) model spits out walls and walls of rambling text
2) 80% of the response is the model acting for user, regardless of templates or settings. You pretty much have no control over what is happening because in every response, the model just does its own thing as if you're not there
can't believe I got bamboozled again. My advice for vramlets, stick to cydonia
Anonymous 01/18/25(Sat)03:10:23 No.103940358
>>103939991
The thing is also great at Spanish, surprisingly. How the hell did they fit all that in such a small model?
The thing is also great at Spanish, surprisingly. How the hell did they fit all that in such a small model?
Anonymous 01/18/25(Sat)03:14:51 No.103940380

Anonymous 01/18/25(Sat)03:33:16 No.103940493