/lmg/ - Local Models General
Anonymous 01/13/25(Mon)15:09:27 | 332 comments | 40 images | 🔒 Locked

/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>103871751 & >>103856603
►News
>(01/08) Phi-4 weights released: https://hf.co/microsoft/phi-4
>(01/06) NVIDIA Project DIGITS announced, capable of running 200B models: https://nvidianews.nvidia.com/news/nvidia-puts-grace-blackwell-on-every-desk-and-at-every-ai-developers-fingertips
>(01/06) Nvidia releases Cosmos world foundation models: https://github.com/NVIDIA/Cosmos
>(01/04) DeepSeek V3 support merged: https://github.com/ggerganov/llama.cpp/pull/11049
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/tldrhowtoquant
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/leaderboard.html
Code Editing: https://aider.chat/docs/leaderboards
Context Length: https://github.com/hsiehjackson/RULER
Japanese: https://hf.co/datasets/lmg-anon/vntl-leaderboard
Censorbench: https://codeberg.org/jts2323/censorbench
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
Previous threads: >>103871751 & >>103856603
►News
>(01/08) Phi-4 weights released: https://hf.co/microsoft/phi-4
>(01/06) NVIDIA Project DIGITS announced, capable of running 200B models: https://nvidianews.nvidia.com/news/
>(01/06) Nvidia releases Cosmos world foundation models: https://github.com/NVIDIA/Cosmos
>(01/04) DeepSeek V3 support merged: https://github.com/ggerganov/llama.
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWeb
https://rentry.org/tldrhowtoquant
►Further Learning
https://rentry.org/machine-learning
https://rentry.org/llm-training
https://rentry.org/LocalModelsPaper
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/lea
Code Editing: https://aider.chat/docs/leaderboard
Context Length: https://github.com/hsiehjackson/RUL
Japanese: https://hf.co/datasets/lmg-anon/vnt
Censorbench: https://codeberg.org/jts2323/censor
GPUs: https://github.com/XiongjieDai/GPU-
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngl
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-M
Sampler Visualizer: https://artefact2.github.io/llm-sam
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-g
https://github.com/LostRuins/kobold
https://github.com/ggerganov/llama.
https://github.com/theroyallab/tabb
https://github.com/vllm-project/vll
Anonymous 01/13/25(Mon)15:09:50 No.103881693
![[sound=https%3A%2F%2Ffiles.catbox.moe%2F13bmf8.mp3]](https://i.4cdn.org/g/1736798990307871s.jpg)
►Recent Highlights from the Previous Thread: >>103871751
--Meta caught pirating books for model training:
>103879446 >103879472 >103879584 >103879649 >103880234 >103880442 >103879650
--Codestral 25.01 release and performance discussion:
>103878238 >103878250 >103878267 >103878318 >103878469 >103878539 >103878513 >103878632 >103878685 >103878876 >103879165 >103879222 >103878932 >103879286 >103880255 >103880451 >103880483 >103880223 >103878678 >103878849
--Evaluating human-like text and dataset creation:
>103879241 >103879271 >103879422 >103879744 >103879301 >103879992 >103880024 >103880157 >103880465 >103880461
--Running giant models across multiple computers and hardware limitations:
>103873201 >103873342 >103873449 >103873521 >103873694 >103874163 >103874046 >103873431 >103877163 >103877557 >103878922
--LORA training, alternatives, and best practices for text generation:
>103874960 >103875060 >103875080 >103875092 >103875176 >103875243 >103875355 >103875123 >103877637
--Ollama's new inference engine and language choice:
>103878644 >103878753 >103878786 >103878819
--Finetuning large language models on a 5080 GPU with 16GB memory:
>103873124 >103873141 >103873157 >103873193 >103873263
--Anons discuss limitations of megacorp models for roleplay and chat:
>103876338 >103876387 >103876789 >103876847 >103879988 >103876924 >103876939
--Anon seeks quantized model for CPU, finds Nemo through discussion:
>103873116 >103873211 >103873280 >103873308 >103873370 >103873414 >103873515 >103873660 >103873716
--Llama4 unlikely to be released in EU due to Meta's restrictions:
>103872942 >103873102 >103873327 >103876045
--Anon complains about Llama 70b's stilted speech, suggests finetuning with real human text:
>103877219 >103877339 >103877373
--Context usage in multi-GPU model splitting:
>103873392 >103873459
--Miku (free space):
>103881350
►Recent Highlight Posts from the Previous Thread: >>103871754
Why?: 9 reply limit >>102478518
Fix: https://rentry.org/lmg-recap-script
--Meta caught pirating books for model training:
>103879446 >103879472 >103879584 >103879649 >103880234 >103880442 >103879650
--Codestral 25.01 release and performance discussion:
>103878238 >103878250 >103878267 >103878318 >103878469 >103878539 >103878513 >103878632 >103878685 >103878876 >103879165 >103879222 >103878932 >103879286 >103880255 >103880451 >103880483 >103880223 >103878678 >103878849
--Evaluating human-like text and dataset creation:
>103879241 >103879271 >103879422 >103879744 >103879301 >103879992 >103880024 >103880157 >103880465 >103880461
--Running giant models across multiple computers and hardware limitations:
>103873201 >103873342 >103873449 >103873521 >103873694 >103874163 >103874046 >103873431 >103877163 >103877557 >103878922
--LORA training, alternatives, and best practices for text generation:
>103874960 >103875060 >103875080 >103875092 >103875176 >103875243 >103875355 >103875123 >103877637
--Ollama's new inference engine and language choice:
>103878644 >103878753 >103878786 >103878819
--Finetuning large language models on a 5080 GPU with 16GB memory:
>103873124 >103873141 >103873157 >103873193 >103873263
--Anons discuss limitations of megacorp models for roleplay and chat:
>103876338 >103876387 >103876789 >103876847 >103879988 >103876924 >103876939
--Anon seeks quantized model for CPU, finds Nemo through discussion:
>103873116 >103873211 >103873280 >103873308 >103873370 >103873414 >103873515 >103873660 >103873716
--Llama4 unlikely to be released in EU due to Meta's restrictions:
>103872942 >103873102 >103873327 >103876045
--Anon complains about Llama 70b's stilted speech, suggests finetuning with real human text:
>103877219 >103877339 >103877373
--Context usage in multi-GPU model splitting:
>103873392 >103873459
--Miku (free space):
>103881350
►Recent Highlight Posts from the Previous Thread: >>103871754
Why?: 9 reply limit >>102478518
Fix: https://rentry.org/lmg-recap-script
Anonymous 01/13/25(Mon)15:11:46 No.103881727
KYSfag is late again...
Anonymous 01/13/25(Mon)15:15:51 No.103881791
Anonymous 01/13/25(Mon)15:17:26 No.103881813
>>103881791
A million graphs. If i don't post it in a few minutes, someone please do it.
A million graphs. If i don't post it in a few minutes, someone please do it.
Anonymous 01/13/25(Mon)15:20:30 No.103881850

>>103881791
One graph, but shared a million times.
One graph, but shared a million times.
Anonymous 01/13/25(Mon)15:23:29 No.103881898
>>103881850
What if this is only a property of llama models?
What if this is only a property of llama models?
Anonymous 01/13/25(Mon)15:29:01 No.103881964

>>103881898
IQ1_S sucks across the board, regardless of model, so it seems pretty accurate to me. I would have bet that 70b IQ1_S loses to 8b.
Here's a graph that uses mistral instead of llama. Small quants still suck rocks.
IQ1_S sucks across the board, regardless of model, so it seems pretty accurate to me. I would have bet that 70b IQ1_S loses to 8b.
Here's a graph that uses mistral instead of llama. Small quants still suck rocks.
Anonymous 01/13/25(Mon)15:29:22 No.103881971
Anonymous 01/13/25(Mon)15:31:44 No.103881998
For people who hate model's positive bias:
https://huggingface.co/SicariusSicariiStuff/Negative_LLAMA_70B
https://huggingface.co/SicariusSica
Anonymous 01/13/25(Mon)15:32:46 No.103882008
>>103881898
>llama models
The llama architecture as in transformers (as opposed to RNN models), llama as in ggufs run in llama.cpp? llama as in the models from meta?
The hypothesis is that bigger models, having more layers, have more "time" to adjust course.
"What if"s don't matter unless you have numbers to show. I cannot really run big comparisons, but i can tell you, anecdotally, that small models (12b) suffer less than tiny 1b at the same quant level. It's the difference between being able to form complete sentences and not.
>llama models
The llama architecture as in transformers (as opposed to RNN models), llama as in ggufs run in llama.cpp? llama as in the models from meta?
The hypothesis is that bigger models, having more layers, have more "time" to adjust course.
"What if"s don't matter unless you have numbers to show. I cannot really run big comparisons, but i can tell you, anecdotally, that small models (12b) suffer less than tiny 1b at the same quant level. It's the difference between being able to form complete sentences and not.
Anonymous 01/13/25(Mon)15:34:30 No.103882032

What kind of models can I run on a single 3090 and 64gb of ram? Any examples of their quality of outputs?
Anonymous 01/13/25(Mon)15:36:42 No.103882050
>>103881592
By 'this' I ment the thread in general and the topics like different models sizes and speeds I guess? When I see that it says 'can take up to 2000 tokens' I'm not sure if it's alot or not yet, only tried gpt4 and know of it's limitations.
context window = means current prompt + history of the conversation?
And thanks for the link, very useful.
Okay yeah I didn't realize tokens could have increased processing time on different models.
By 'this' I ment the thread in general and the topics like different models sizes and speeds I guess? When I see that it says 'can take up to 2000 tokens' I'm not sure if it's alot or not yet, only tried gpt4 and know of it's limitations.
context window = means current prompt + history of the conversation?
And thanks for the link, very useful.
Okay yeah I didn't realize tokens could have increased processing time on different models.
Anonymous 01/13/25(Mon)15:37:52 No.103882071
>>103881998
I will download it now and mercilessly shit on you for shilling your worthless model that only made the output worse and dumber.
I will download it now and mercilessly shit on you for shilling your worthless model that only made the output worse and dumber.
Anonymous 01/13/25(Mon)15:39:28 No.103882090
>>103881998
buy an ad
buy an ad
Anonymous 01/13/25(Mon)15:40:29 No.103882103
>>103882032
You can run lots, do you want more than 1T/s though?
You can run lots, do you want more than 1T/s though?
Anonymous 01/13/25(Mon)15:40:38 No.103882105
>>103882032
Come back in a year.
Come back in a year.
Anonymous 01/13/25(Mon)15:42:00 No.103882131
>>103882032
pyg6b
pyg6b
Anonymous 01/13/25(Mon)15:42:35 No.103882136
>>103882103
Iteration / Second? I've only ever used AI for image generation, forgive my ignorance
Does text generation work the same?
Iteration / Second? I've only ever used AI for image generation, forgive my ignorance
Does text generation work the same?
Anonymous 01/13/25(Mon)15:44:30 No.103882158
>>103882050
Depends on what you're doing, the prompt, the model. I consider a 500 token response long. Some anons are disappointed if they don't get a novel out of "ah ah mistress"ing.
>context window = means current prompt + history of the conversation?
Roughly, yes. Things that fall out of the context window will be forgotten.
Here's some old-ish benchmarks of an 8B and a 70B on a bunch of different hardware if you plan to run them on your pc, for reference.
>https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
Depends on what you're doing, the prompt, the model. I consider a 500 token response long. Some anons are disappointed if they don't get a novel out of "ah ah mistress"ing.
>context window = means current prompt + history of the conversation?
Roughly, yes. Things that fall out of the context window will be forgotten.
Here's some old-ish benchmarks of an 8B and a 70B on a bunch of different hardware if you plan to run them on your pc, for reference.
>https://github.com/XiongjieDai/GPU
Anonymous 01/13/25(Mon)15:45:09 No.103882162
>>103881850
The degradation will get worse with newer models.
The degradation will get worse with newer models.
Anonymous 01/13/25(Mon)15:46:43 No.103882180
>>103882158
>Some anons are disappointed if they don't get a novel out of "ah ah mistress"ing.
Would you write half the solution to any productive question or request? No? Then kill yourself nigger.
>Some anons are disappointed if they don't get a novel out of "ah ah mistress"ing.
Would you write half the solution to any productive question or request? No? Then kill yourself nigger.
Anonymous 01/13/25(Mon)15:46:48 No.103882181
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
https://github.com/ollama/ollama
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-g
https://github.com/LostRuins/kobold
https://github.com/ggerganov/llama.
https://github.com/theroyallab/tabb
https://github.com/vllm-project/vll
https://github.com/ollama/ollama
Anonymous 01/13/25(Mon)15:47:00 No.103882183
>>103882162
But bigger models being less affected by quantization will probably remain true.
But bigger models being less affected by quantization will probably remain true.
Anonymous 01/13/25(Mon)15:48:28 No.103882199
>>103882180
Found the ah-ah-mistresser
Found the ah-ah-mistresser
Anonymous 01/13/25(Mon)15:49:33 No.103882213
>>103882181
One too many lines.
One too many lines.
Anonymous 01/13/25(Mon)15:52:30 No.103882252
>>103882180
Do you understand how creative writing is fundamentally different from problem-solving in that the latter has an objectively valid solution, while the former is largely subjective?
No, you clearly don't. I'm actually glad retards like you can't get kino with no effort; you don't deserve nice things.
Do you understand how creative writing is fundamentally different from problem-solving in that the latter has an objectively valid solution, while the former is largely subjective?
No, you clearly don't. I'm actually glad retards like you can't get kino with no effort; you don't deserve nice things.
Anonymous 01/13/25(Mon)15:53:21 No.103882259
>>103881704
After seeing your post, I realized that I could run a ST server on my laptop, since it's always on anyway (I have some applications I need to use it for). If you do write something, I probably wouldn't make use of it fully, but I'd read it.
After seeing your post, I realized that I could run a ST server on my laptop, since it's always on anyway (I have some applications I need to use it for). If you do write something, I probably wouldn't make use of it fully, but I'd read it.
Anonymous 01/13/25(Mon)15:53:22 No.103882260
>>103882252
Go play with your dolls in your closet faggot. And then kill yourself.
Go play with your dolls in your closet faggot. And then kill yourself.
Anonymous 01/13/25(Mon)15:55:51 No.103882299
>>103882260
Nigga what the fuck are you talking about?
Nigga what the fuck are you talking about?
Anonymous 01/13/25(Mon)15:57:21 No.103882325
>>103882299
You are giving yourself away locust scum.
You are giving yourself away locust scum.
Anonymous 01/13/25(Mon)15:59:15 No.103882353
>>103882325
Running Cirrus right now you delusional retard.
Gonna keep flailing and tossing random accusations around?
Running Cirrus right now you delusional retard.
Gonna keep flailing and tossing random accusations around?
Anonymous 01/13/25(Mon)15:59:44 No.103882365
>>103882299
i hate it when newfags try to tell someone else he is doing it wrong
i hate it when newfags try to tell someone else he is doing it wrong
Anonymous 01/13/25(Mon)16:00:28 No.103882377
>>103882353
Buy a fucking ad, Sao.
Buy a fucking ad, Sao.
Anonymous 01/13/25(Mon)16:01:16 No.103882388
>>103882365
Expecting the model to read your fucking mind because you can't type a coherent sentence IS doing it wrong.
Expecting the model to read your fucking mind because you can't type a coherent sentence IS doing it wrong.
Anonymous 01/13/25(Mon)16:02:23 No.103882397
>>103882353
lurk more newfag
lurk more newfag
Anonymous 01/13/25(Mon)16:02:50 No.103882404
>>103882388
The fuck are you talking about? That's exactly the telltale sign of a kino model.
The fuck are you talking about? That's exactly the telltale sign of a kino model.
Anonymous 01/13/25(Mon)16:03:52 No.103882413
>>103882397
Keep seething, promptlet.
Keep seething, promptlet.
Anonymous 01/13/25(Mon)16:10:37 No.103882515
oops repost
>>103880969
>>103880995
>>103881045
The Mac has 800 GB/s with LPDDR5, wouldn't the Digits with LPDDR5X have 1.1 TB/s just due to the faster spec?
>>103880969
>>103880995
>>103881045
The Mac has 800 GB/s with LPDDR5, wouldn't the Digits with LPDDR5X have 1.1 TB/s just due to the faster spec?
Anonymous 01/13/25(Mon)16:11:54 No.103882536
>>103881998
I gave it a try and it is trash.
I gave it a try and it is trash.
Anonymous 01/13/25(Mon)16:14:54 No.103882577
Anonymous 01/13/25(Mon)16:15:02 No.103882579

>>103881704
Wrote it up anyway, so I could remember wth I did to get it working. For posterity: https://rentry.org/SillyTavernOnSBC
Wrote it up anyway, so I could remember wth I did to get it working. For posterity: https://rentry.org/SillyTavernOnSBC
Anonymous 01/13/25(Mon)16:16:03 No.103882593
>>103882536
what was bad about it? I was thinking of downloading it but will skip if it seems like a dud
what was bad about it? I was thinking of downloading it but will skip if it seems like a dud
Anonymous 01/13/25(Mon)16:16:21 No.103882596
>>103880982
>I don't know how many here will benefit from hearing this, but with 768GB of ram and a 24GB graphics card, deepseek v3 at Q6 with -ngl 0 and 32768 context runs reasonably well, still leaving VRAM for decent imggen and tts.
>I haven't noticed any horrible consequences from the quanting down to q6 yet.
Teach me, Master, what backend you are using
>I don't know how many here will benefit from hearing this, but with 768GB of ram and a 24GB graphics card, deepseek v3 at Q6 with -ngl 0 and 32768 context runs reasonably well, still leaving VRAM for decent imggen and tts.
>I haven't noticed any horrible consequences from the quanting down to q6 yet.
Teach me, Master, what backend you are using
Anonymous 01/13/25(Mon)16:18:59 No.103882639
>>103882593
probably it's just a troll, give it a try anyway and report back
probably it's just a troll, give it a try anyway and report back
Anonymous 01/13/25(Mon)16:19:10 No.103882642
>>103882515
>The Mac has 800 GB/s with LPDDR5, wouldn't the Digits with LPDDR5X have 1.1 TB/s just due to the faster spec?
The mac is ON-DIE memory. Not much can compete with that. They get those speed by making the distance to the cpu core as short as possible with a wide bus. It also means no upgrades without throwing away the entire CPU.
The m4 ultra will probably be well over 1TB/s when the new studio is released, but even soldered DDR5 isn't likely to hit those kinds of speeds at the price of digits. DDR6 might hit it on server boards, and maybe even desktop after a few minor revisions if mainstream cpus have the memory controllers to handle it.
VRAM may be cheap, but the knowledge of the black magic of feeding that over a bus without everything shitting the bed is not.
>The Mac has 800 GB/s with LPDDR5, wouldn't the Digits with LPDDR5X have 1.1 TB/s just due to the faster spec?
The mac is ON-DIE memory. Not much can compete with that. They get those speed by making the distance to the cpu core as short as possible with a wide bus. It also means no upgrades without throwing away the entire CPU.
The m4 ultra will probably be well over 1TB/s when the new studio is released, but even soldered DDR5 isn't likely to hit those kinds of speeds at the price of digits. DDR6 might hit it on server boards, and maybe even desktop after a few minor revisions if mainstream cpus have the memory controllers to handle it.
VRAM may be cheap, but the knowledge of the black magic of feeding that over a bus without everything shitting the bed is not.
Anonymous 01/13/25(Mon)16:19:37 No.103882647
>>103882639
I figured the same but might as well try to elicit some useful feedback if not
I figured the same but might as well try to elicit some useful feedback if not
Anonymous 01/13/25(Mon)16:19:51 No.103882650
>>103882639
Fuck off shill.
Fuck off shill.
Anonymous 01/13/25(Mon)16:20:11 No.103882655
Anonymous 01/13/25(Mon)16:21:16 No.103882671
>>103882650
>everyone who doesn't blindly hate any model mentioned is a shill
fuck are you even here for, nigger?
>everyone who doesn't blindly hate any model mentioned is a shill
fuck are you even here for, nigger?
Anonymous 01/13/25(Mon)16:21:18 No.103882672
>>103881998
It's different so far. Not sure if I like the prose but I like how it makes stories go into dark directions on its own. Had a character actually tell me off.
It's different so far. Not sure if I like the prose but I like how it makes stories go into dark directions on its own. Had a character actually tell me off.
Anonymous 01/13/25(Mon)16:25:35 No.103882732
>>103882671
You shilled your model. I gave it a try. It is garbage. There is your feedback. No fuck off and stop samefagging pretending it is good.
You shilled your model. I gave it a try. It is garbage. There is your feedback. No fuck off and stop samefagging pretending it is good.
Anonymous 01/13/25(Mon)16:26:00 No.103882740
>>103882642
The critical question will be if DIGITS suffers from the same prompt ingestion problem as the mac studio. If not, then I'd still prefer DIGITS over the mac, even if the mac is a bit faster.
The critical question will be if DIGITS suffers from the same prompt ingestion problem as the mac studio. If not, then I'd still prefer DIGITS over the mac, even if the mac is a bit faster.
Anonymous 01/13/25(Mon)16:26:36 No.103882742
>>103882732
How did you figure out?
How did you figure out?
Anonymous 01/13/25(Mon)16:27:03 No.103882748
Anonymous 01/13/25(Mon)16:27:29 No.103882749
>>103882742
How did you figure out your model is good?
How did you figure out your model is good?
Anonymous 01/13/25(Mon)16:29:02 No.103882767
>>103882158
Okay thanks a bunch, got a lot to unpack right now.
Okay thanks a bunch, got a lot to unpack right now.
Anonymous 01/13/25(Mon)16:29:51 No.103882781
>>103882748
>What problem?
macs don't have good GPUs, and the METAL prompt processing process takes an order of magnitude longer than NVidia, or even AMD, so you spend a lot of time waiting when chatting the LLMs, even if the tokens come out reasonably fast once the prompt is processed.
>What problem?
macs don't have good GPUs, and the METAL prompt processing process takes an order of magnitude longer than NVidia, or even AMD, so you spend a lot of time waiting when chatting the LLMs, even if the tokens come out reasonably fast once the prompt is processed.
Anonymous 01/13/25(Mon)16:35:24 No.103882848
>>103882732
Not my model, not shilling, not even the same anon who posted it. Just fucking sick of you inbred morons shitting yourselves every time someone mentions a local model in the local model general.
Not my model, not shilling, not even the same anon who posted it. Just fucking sick of you inbred morons shitting yourselves every time someone mentions a local model in the local model general.
Anonymous 01/13/25(Mon)16:37:41 No.103882877
kino is back on the menu boys
Anonymous 01/13/25(Mon)16:38:06 No.103882884
>>103882740
Why would it? Doesn't it have cuda cores too? It's a Grace Blackwell chip. Plus you won't be stuck with Apple's OS and software. So it's better. I don't see why anyone would want a mac now.
Why would it? Doesn't it have cuda cores too? It's a Grace Blackwell chip. Plus you won't be stuck with Apple's OS and software. So it's better. I don't see why anyone would want a mac now.
Anonymous 01/13/25(Mon)16:38:41 No.103882891
>>103882877
is ginny gonna now get double teamed?
is ginny gonna now get double teamed?
Anonymous 01/13/25(Mon)16:38:51 No.103882896
>>103882579
Thanks.
Thanks.
Anonymous 01/13/25(Mon)16:41:25 No.103882928
I went back to C-R.
Anonymous 01/13/25(Mon)16:41:41 No.103882932
>>103882884
>I don't see why anyone would want a mac now.
They're still shiny.
>https://www.youtube.com/watch?v=9BnLbv6QYcA
>I don't see why anyone would want a mac now.
They're still shiny.
>https://www.youtube.com/watch?v=9B
Anonymous 01/13/25(Mon)16:43:38 No.103882961

can someone post sillytavern sliders please?
i don't even know what to do with mine
i don't even know what to do with mine
Anonymous 01/13/25(Mon)16:43:49 No.103882963
Anonymous 01/13/25(Mon)16:45:40 No.103882988
>>103882032
>>103882103
>>103882136
4070 and 64GB RAM here.
Using Kobold you can use both video card and system RAM to load the model.
I suggest you start with something like Llama 3.3 70B Instruct Q6 K L. Ignore the reeeing noises that this thread will voice, it's looking good for general purpose.
Generation is measured in tokens per second. A token can be a word or a fragment and is the generation unit. Guess roughly that you'll spend about 1.3 to 1.5 tokens per word, so 1 token per second is like 40 to 50 words per minute. In other words in the ballpark of human typing speeds. If you go really small (small enough to fit everything on your video card) then generation can cook at "computer typing messages on a screen in a movie" speeds. But it will be dumb because small models and small context simulates small brains.
If you don't get reasonable speeds, like one or two tokens per minute, either you're not using your CUDA option, or you have too much other shit taking up RAM to fit the model. You can step down to, say, Q5 K S or even a Q4, but every Q you drop makes the model less "correct". Though for creative writing, you can go down to Q3, or IQ3 and below. Just know it's a brain damaged model at that point and will do goofy things sometimes.
>>103882103
>>103882136
4070 and 64GB RAM here.
Using Kobold you can use both video card and system RAM to load the model.
I suggest you start with something like Llama 3.3 70B Instruct Q6 K L. Ignore the reeeing noises that this thread will voice, it's looking good for general purpose.
Generation is measured in tokens per second. A token can be a word or a fragment and is the generation unit. Guess roughly that you'll spend about 1.3 to 1.5 tokens per word, so 1 token per second is like 40 to 50 words per minute. In other words in the ballpark of human typing speeds. If you go really small (small enough to fit everything on your video card) then generation can cook at "computer typing messages on a screen in a movie" speeds. But it will be dumb because small models and small context simulates small brains.
If you don't get reasonable speeds, like one or two tokens per minute, either you're not using your CUDA option, or you have too much other shit taking up RAM to fit the model. You can step down to, say, Q5 K S or even a Q4, but every Q you drop makes the model less "correct". Though for creative writing, you can go down to Q3, or IQ3 and below. Just know it's a brain damaged model at that point and will do goofy things sometimes.
Anonymous 01/13/25(Mon)16:46:06 No.103882996
>>103882961
Go to the huggingface page for any model you downloaded. Many of them will have recommended sampler settings.
Go to the huggingface page for any model you downloaded. Many of them will have recommended sampler settings.
Anonymous 01/13/25(Mon)16:47:05 No.103883009
Can you get a local language model as good as opus?
Anonymous 01/13/25(Mon)16:47:51 No.103883015

Anonymous 01/13/25(Mon)16:48:28 No.103883024
Anonymous 01/13/25(Mon)16:50:17 No.103883047
>>103881688
>Japanese: https://hf.co/datasets/lmg-anon/vntl-leaderboard
Do we really want to support this kind of person? I think it's time to remove the leaderboard from the OP.
https://www.resetera.com/threads/gambs-vn-dude-being-indicted-by-korea-for-sexual-relations-w-multiple-women-including-minors-rape-distributing-photos-online-w-out-consent.1081311/
>Japanese: https://hf.co/datasets/lmg-anon/vnt
Do we really want to support this kind of person? I think it's time to remove the leaderboard from the OP.
https://www.resetera.com/threads/ga
Anonymous 01/13/25(Mon)16:51:00 No.103883056
>>103882884
>Doesn't it have cuda cores too
Yes, but it's a fucking mystery as to how many it has, or what kind of memory bandwidth it has.
I feel like Nvidia doesn't even realize what the most interesting part of their shitty presentation was, and they just focused on the shitty fucking frame-generation GPUs instead.
>Doesn't it have cuda cores too
Yes, but it's a fucking mystery as to how many it has, or what kind of memory bandwidth it has.
I feel like Nvidia doesn't even realize what the most interesting part of their shitty presentation was, and they just focused on the shitty fucking frame-generation GPUs instead.
Anonymous 01/13/25(Mon)16:53:35 No.103883088
>>103883047
>https://www.resetera.com/threads/gambs-vn-dude-being-indicted-by-korea-for-sexual-relations-w-multiple-women-including-minors-rape-distributing-photos-online-w-out-consent.1081311/
kek literal "muh dick" energy from these yellow fever betas.
>https://www.resetera.com/threads/g
kek literal "muh dick" energy from these yellow fever betas.
Anonymous 01/13/25(Mon)16:53:55 No.103883091
>>103882961
Disable everything, set temp to 1 and minp to 0.05. That's it.
Disable everything, set temp to 1 and minp to 0.05. That's it.
Anonymous 01/13/25(Mon)16:55:08 No.103883102
>>103883056
>the most interesting part of their shitty presentation
For one shitty general and one shitty subreddit. Everyone else is playing league and csgo on their x060 card and they don't care.
>the most interesting part of their shitty presentation
For one shitty general and one shitty subreddit. Everyone else is playing league and csgo on their x060 card and they don't care.
Anonymous 01/13/25(Mon)16:56:11 No.103883114
>>103883047
isn't this cancel culture?
isn't this cancel culture?
Anonymous 01/13/25(Mon)16:56:47 No.103883116
>>103883056
Well it will have some, which makes it more attractive than a mac, even if it only has 237GB/s memory it's still faster than quad channel ddr5 which you can't get on a regular PC either. It has what looks like the SFP ports for fast connectivity, I think it'll be good. I'll be able to run any decent sized model above 2T/s which is all I need.
Well it will have some, which makes it more attractive than a mac, even if it only has 237GB/s memory it's still faster than quad channel ddr5 which you can't get on a regular PC either. It has what looks like the SFP ports for fast connectivity, I think it'll be good. I'll be able to run any decent sized model above 2T/s which is all I need.
Anonymous 01/13/25(Mon)16:57:00 No.103883118
>>103883102
Have you seen the reactions to the framegen gaymer cards? Everyone realizes they're a fucking scam.
Have you seen the reactions to the framegen gaymer cards? Everyone realizes they're a fucking scam.
Anonymous 01/13/25(Mon)16:57:59 No.103883129
>>103882961
Neutralize samplers, add a bit minp if you want, lower the temp a bit if you're using nemo.
Neutralize samplers, add a bit minp if you want, lower the temp a bit if you're using nemo.
Anonymous 01/13/25(Mon)16:58:02 No.103883131
>>103882032
You can run ~30b models at 20-30T/s (quite fast) or 70b models at 1-2T/s (horribly slow)
I recommend starting with Qwen2.5 32b and related. Don't listen to >>103882988 to start with, his advice is better for vramlets who have no hope of running anything quickly. CPU maxxing will waste your 3090. You can always fall back to it later if you want.
You can run ~30b models at 20-30T/s (quite fast) or 70b models at 1-2T/s (horribly slow)
I recommend starting with Qwen2.5 32b and related. Don't listen to >>103882988 to start with, his advice is better for vramlets who have no hope of running anything quickly. CPU maxxing will waste your 3090. You can always fall back to it later if you want.
Anonymous 01/13/25(Mon)16:58:48 No.103883142
>>103883116
>SFP ports for fast connectivity
Those are for connecting two of them together to turn them into a 256 GB shared memory system. I believe it will be presented as a single GPU, so it should just work natively with any CUDA application, though the performance may suffer a little due to the increased data access latency.
>SFP ports for fast connectivity
Those are for connecting two of them together to turn them into a 256 GB shared memory system. I believe it will be presented as a single GPU, so it should just work natively with any CUDA application, though the performance may suffer a little due to the increased data access latency.
Anonymous 01/13/25(Mon)17:00:15 No.103883157
what are the consequences of going from fp8 to q8...its all just 8 bits, right? If anything q8 seems to be the more efficient way of storing data.
Anonymous 01/13/25(Mon)17:00:49 No.103883164
>>103883047
lol what, is lmg-anon this gambs guy?
lol what, is lmg-anon this gambs guy?
Anonymous 01/13/25(Mon)17:02:54 No.103883185
>>103883129
What about XTC and DRY? I heard good things about those.
What about XTC and DRY? I heard good things about those.
Anonymous 01/13/25(Mon)17:04:05 No.103883196
>>103883118
>Everyone realizes they're a fucking scam
Johnny is going to buy a 5060 and fire up bladur's gate. DLSS will be turned on by default. The game will be rendered at 560p and upscaled to his 1080p monitor. He has no idea what this means. He is happy because his human fighter just rolled 3d6 and got 18.
>Everyone realizes they're a fucking scam
Johnny is going to buy a 5060 and fire up bladur's gate. DLSS will be turned on by default. The game will be rendered at 560p and upscaled to his 1080p monitor. He has no idea what this means. He is happy because his human fighter just rolled 3d6 and got 18.
Anonymous 01/13/25(Mon)17:04:43 No.103883204
>>103883157
>.its all just 8 bits
Kind of but not.
FP8 is just truncating I think. Converting one data type directly to another which means a loss in precision that comes with a loss of information.
q8 is not just a datatype it's a whole quantization process that involves scaling the values into lower data types and shit, meaning that the loss of actual information should be less in comparison.
Or something like that.
>.its all just 8 bits
Kind of but not.
FP8 is just truncating I think. Converting one data type directly to another which means a loss in precision that comes with a loss of information.
q8 is not just a datatype it's a whole quantization process that involves scaling the values into lower data types and shit, meaning that the loss of actual information should be less in comparison.
Or something like that.
Anonymous 01/13/25(Mon)17:06:34 No.103883223
>>103883185
I don't care for XTC. DRY can work a bit, but if your model really wants to say something it'll just misspell it to get around the penalty and that's more annoying.
I don't care for XTC. DRY can work a bit, but if your model really wants to say something it'll just misspell it to get around the penalty and that's more annoying.
Anonymous 01/13/25(Mon)17:07:02 No.103883230
>>103883185
XTC can make start models more fun. Your gonna want to use a 70B+ though, preferably mistral large
XTC can make start models more fun. Your gonna want to use a 70B+ though, preferably mistral large
Anonymous 01/13/25(Mon)17:07:28 No.103883239
>>103883204
>loss of information
So https://github.com/ggerganov/llama.cpp/pull/10055 should get merged or we'll only have braindamaged ds3?
>loss of information
So https://github.com/ggerganov/llama.
Anonymous 01/13/25(Mon)17:08:37 No.103883245
>>103883239
DS3 is different in that it was trained at FP8 I'm pretty sure.
DS3 is different in that it was trained at FP8 I'm pretty sure.
Anonymous 01/13/25(Mon)17:09:00 No.103883249
>>103883204
fp8 also has scales, it's useless by itself
fp8 also has scales, it's useless by itself
Anonymous 01/13/25(Mon)17:10:14 No.103883263
https://www.theregister.com/2025/01/07/nvidia_project_digits_mini_pc/
>The machine nonetheless packs rather more power than an AI PC powered by processors from Intel, AMD, or Qualcomm, but will struggle to compete with a workstation packing Nvidia's current flagship workstation card, the RTX 6000 Ada. That accelerator boasts 1.45 petaFLOPS of sparse FP/INT8 performance, roughly triple the performance we think Project Digits will deliver (500 teraFLOPS) at that precision.
>Nvidia claims Project Digits will be able to support models up to 200 billion parameters in size. However, to fit such models into the machine they will need to be compressed to 4-bits, a concept you can learn more about in our hands-on guide.
>Running larger models will be possible thanks to onboard ConnectX networking that Nvidia says will allow two of these computers to be connected so they can run models with up to 405 billion parameters. That puts Meta's Llama 3.1 405B in play, again at 4-bits.
>For reference, if you wanted to run that same model at 4-bits on existing workstation hardware you'd need at least five 48GB GPUs.
>the system appeared to feature six LPDDR5x modules. Assuming memory speeds of 8,800 MT/s we'd be looking at around 825GB/s of bandwidth which wouldn't be that far off from the 960GB/s of the RTX 6000 Ada. For a 200 billion parameter model, that'd work out to around eight tokens/sec. Again, that's just speculation
sounds good?
>The machine nonetheless packs rather more power than an AI PC powered by processors from Intel, AMD, or Qualcomm, but will struggle to compete with a workstation packing Nvidia's current flagship workstation card, the RTX 6000 Ada. That accelerator boasts 1.45 petaFLOPS of sparse FP/INT8 performance, roughly triple the performance we think Project Digits will deliver (500 teraFLOPS) at that precision.
>Nvidia claims Project Digits will be able to support models up to 200 billion parameters in size. However, to fit such models into the machine they will need to be compressed to 4-bits, a concept you can learn more about in our hands-on guide.
>Running larger models will be possible thanks to onboard ConnectX networking that Nvidia says will allow two of these computers to be connected so they can run models with up to 405 billion parameters. That puts Meta's Llama 3.1 405B in play, again at 4-bits.
>For reference, if you wanted to run that same model at 4-bits on existing workstation hardware you'd need at least five 48GB GPUs.
>the system appeared to feature six LPDDR5x modules. Assuming memory speeds of 8,800 MT/s we'd be looking at around 825GB/s of bandwidth which wouldn't be that far off from the 960GB/s of the RTX 6000 Ada. For a 200 billion parameter model, that'd work out to around eight tokens/sec. Again, that's just speculation
sounds good?
Anonymous 01/13/25(Mon)17:12:15 No.103883283
Anonymous 01/13/25(Mon)17:12:31 No.103883287
Anonymous 01/13/25(Mon)17:12:42 No.103883290
UGI Leaderboard
just became /pol/
>UGI-Leaderboard Remake! New Political
https://www.reddit.com/r/LocalLLaMA/comments/1i0ou0v/ugileaderboard_remake_new_political_coding_and/
just became /pol/
>UGI-Leaderboard Remake! New Political
https://www.reddit.com/r/LocalLLaMA
Anonymous 01/13/25(Mon)17:12:50 No.103883291
>>103881998
unironically if you do this for 123B I'll try it
I can't go back to 70B, m2l even at q3 is too good.
unironically if you do this for 123B I'll try it
I can't go back to 70B, m2l even at q3 is too good.
Anonymous 01/13/25(Mon)17:15:15 No.103883315
>>103883056
it seems like every single nm of wafer nvidia uses on gamer cards is 10's of thousands of lost revenue better used on a datacenter card.
I reckon they're only in gaming hardware now to show face and not really give a shit. Oddly specific timing that AMD decided that now is when they can't compete, now, when nvidia isn't even trying any more.
Collusion by any other name, or both sides have realised that gaming hardware is identical to datacenter but with datacenter you make way, way more.
it seems like every single nm of wafer nvidia uses on gamer cards is 10's of thousands of lost revenue better used on a datacenter card.
I reckon they're only in gaming hardware now to show face and not really give a shit. Oddly specific timing that AMD decided that now is when they can't compete, now, when nvidia isn't even trying any more.
Collusion by any other name, or both sides have realised that gaming hardware is identical to datacenter but with datacenter you make way, way more.
Anonymous 01/13/25(Mon)17:16:08 No.103883325
Anonymous 01/13/25(Mon)17:16:23 No.103883327
>>103883230
this, XTC and mistral large can actually give me prose that reads like a book. not an especially great book, given the mediocre coauthor (me) but it's leaps and bounds o'er what it does with neutralized samplers
this, XTC and mistral large can actually give me prose that reads like a book. not an especially great book, given the mediocre coauthor (me) but it's leaps and bounds o'er what it does with neutralized samplers
Anonymous 01/13/25(Mon)17:19:31 No.103883369
What's the cheapest setup for 12 channel memory with epyc? Or do I have to wait another gen for prices to drop to get something reasonable?
Anonymous 01/13/25(Mon)17:22:07 No.103883406
>>103883263
>six LPDDR5x modules
There are 8 modules. The exploded picture clearly has 2 of them that are covered by the processor that the Register's AI wasn't able to perceive.
At a maximum I'd say 1.1 TB/s, but it will probably be 550 GB/s.
>six LPDDR5x modules
There are 8 modules. The exploded picture clearly has 2 of them that are covered by the processor that the Register's AI wasn't able to perceive.
At a maximum I'd say 1.1 TB/s, but it will probably be 550 GB/s.
Anonymous 01/13/25(Mon)17:22:13 No.103883409
>>103883327
What are good settings for this? I don't really get these 2 sliders.
What are good settings for this? I don't really get these 2 sliders.
Anonymous 01/13/25(Mon)17:24:00 No.103883430
>>103883315
I honestly don't give a shit about the gaymer shit. It's not like games look any better than they looked 8 years ago. If anything they look far worse with TAA and other "optimizations" being present in game engines.
I honestly don't give a shit about the gaymer shit. It's not like games look any better than they looked 8 years ago. If anything they look far worse with TAA and other "optimizations" being present in game engines.
Anonymous 01/13/25(Mon)17:25:29 No.103883447

>>103883047
Is this bait or are you retarded?
Is this bait or are you retarded?
Anonymous 01/13/25(Mon)17:26:20 No.103883455
>>103883291
What's the best 123b? I've only tried Lumimaid so far, and it seemed really good to me.
What's the best 123b? I've only tried Lumimaid so far, and it seemed really good to me.
Anonymous 01/13/25(Mon)17:26:47 No.103883466
>>103883447
Both are likely the case with him.
Both are likely the case with him.
Anonymous 01/13/25(Mon)17:28:43 No.103883491
>>103883455
monstral
monstral
Anonymous 01/13/25(Mon)17:30:50 No.103883513
>>103883447
Shouldn't you be preparing your defense for the lawsuit instead of browsing the thread, lmg-anon/gambs/AirKatakana/petra?
Shouldn't you be preparing your defense for the lawsuit instead of browsing the thread, lmg-anon/gambs/AirKatakana/petra?
Anonymous 01/13/25(Mon)17:37:33 No.103883568

Upon suggestion of an anon from one of the previous threads I happened to try *anonymous-chatbot* on lmsys (it randomly appears in Chat Arena battle and it comes out more often when uploading images; it has image recognition capabilities). It feels nice but it doesn't seem like it's a very large model, which is rather clear in its image capabilities. Picrel is a response it gave me.
Anonymous 01/13/25(Mon)17:38:59 No.103883589

>>103883513
Your bogeyman has a lot of names
Your bogeyman has a lot of names
Anonymous 01/13/25(Mon)17:40:13 No.103883604
Anonymous 01/13/25(Mon)17:40:54 No.103883612
>>103883589
Anyone with a brain can put two and two together to be able to tell that they're all the same person. Your beloved "lmg-anon" is a rapist.
Anyone with a brain can put two and two together to be able to tell that they're all the same person. Your beloved "lmg-anon" is a rapist.
Anonymous 01/13/25(Mon)17:42:13 No.103883625
>>103883290
Excluding tiny models, looks like grok-beta is the model with the second least progressive values.
With only one model leaning traditional.
Excluding tiny models, looks like grok-beta is the model with the second least progressive values.
With only one model leaning traditional.
Anonymous 01/13/25(Mon)17:49:03 No.103883690
>>103883625
Of course, that model that you won't mention. What are the chances...
Of course, that model that you won't mention. What are the chances...
Anonymous 01/13/25(Mon)17:54:38 No.103883728

>>103883690
Peak Traditionalism
Peak Traditionalism
Anonymous 01/13/25(Mon)17:56:57 No.103883745
>>103883455
I like both of "m2l 2411" and "behemoth v1g"
Some very slight TLC can be applied to make results super varied across rolls, specifically:
Top-K Sampling: 95
For behemoth, Metharme template/tag preset.
I like both of "m2l 2411" and "behemoth v1g"
Some very slight TLC can be applied to make results super varied across rolls, specifically:
Top-K Sampling: 95
For behemoth, Metharme template/tag preset.
Anonymous 01/13/25(Mon)17:57:23 No.103883748
>>103883612
Take your meds first
Take your meds first
Anonymous 01/13/25(Mon)17:58:48 No.103883760
>>103883728
We won't use your shitty models anyway. Go back shilling your models on reddit and discord.
We won't use your shitty models anyway. Go back shilling your models on reddit and discord.
Anonymous 01/13/25(Mon)18:01:17 No.103883782
Will we all buy DIGITS? Or do we build our own PC (seems almost more expensive when you consider the performance of DIGITS™).
Anonymous 01/13/25(Mon)18:01:56 No.103883785
>>103883782
I'll wait for DDR6 memory on desktop systems.
I'll wait for DDR6 memory on desktop systems.
Anonymous 01/13/25(Mon)18:05:03 No.103883818
newfag here. I gave kobold a try after using llama.cpp and it's great. so comfy... I need to test the image generation, description and tts stuff now.
what's else should I try?
what's else should I try?
Anonymous 01/13/25(Mon)18:05:41 No.103883825
>>103883782
I don't care until benchmarks are out.
I don't care until benchmarks are out.
Anonymous 01/13/25(Mon)18:06:43 No.103883831
>>103883825
By then they'll be selling for $5k a pop.
By then they'll be selling for $5k a pop.
Anonymous 01/13/25(Mon)18:06:46 No.103883832
Anonymous 01/13/25(Mon)18:09:13 No.103883852
>>103883831
If there was a possibility for me to stutter through text and you not picking on the obvious impossibility, i would have asked you "did i stutter?"
If there was a possibility for me to stutter through text and you not picking on the obvious impossibility, i would have asked you "did i stutter?"
Anonymous 01/13/25(Mon)18:11:50 No.103883880
>>103883785
It says the memory bandwidth for that is only 134.4 GB/s. That's going to be slower than 237.
It says the memory bandwidth for that is only 134.4 GB/s. That's going to be slower than 237.
Anonymous 01/13/25(Mon)18:12:32 No.103883888
>>103883852
I look forward to selling my DIGITS™ to you.
I look forward to selling my DIGITS™ to you.
Anonymous 01/13/25(Mon)18:14:29 No.103883904
Anonymous 01/13/25(Mon)18:16:50 No.103883932
>>103883888
You mustn't have much going on, then. How boring.
You mustn't have much going on, then. How boring.
Anonymous 01/13/25(Mon)18:17:16 No.103883934
>>103883904
Even if that's only 1 channel dual channel would still be in the 200s, so not much faster than digits. Not worth waiting for.
Even if that's only 1 channel dual channel would still be in the 200s, so not much faster than digits. Not worth waiting for.
Anonymous 01/13/25(Mon)18:17:43 No.103883937
Anonymous 01/13/25(Mon)18:19:54 No.103883963
>>103883934
>not much faster than digits
There is a decent chance that digits releases with 800+gbs / 1.6 TBs with 2 of them using the connectx
>not much faster than digits
There is a decent chance that digits releases with 800+gbs / 1.6 TBs with 2 of them using the connectx
Anonymous 01/13/25(Mon)18:20:12 No.103883969
>>103883904
>per how many channels?
zen6 is rumored to be 16 channels on epyc. hopefully we get 4-8 channels on desktop
>per how many channels?
zen6 is rumored to be 16 channels on epyc. hopefully we get 4-8 channels on desktop
Anonymous 01/13/25(Mon)18:21:12 No.103883981
Do self merges waste disk space or do they really do something?
Anonymous 01/13/25(Mon)18:21:53 No.103883986
>>103883963
I was assuming the worst case scenario of 237. If you are correct ddr6 will be even less worth waiting for.
I was assuming the worst case scenario of 237. If you are correct ddr6 will be even less worth waiting for.
Anonymous 01/13/25(Mon)18:22:25 No.103883991
>>103883981
>do they really do something?
They HAVE to do something. What that something is is debatable.
>do they really do something?
They HAVE to do something. What that something is is debatable.
Anonymous 01/13/25(Mon)18:22:35 No.103883995
>>103882032
piggy backing on this
ive got a 4090 and 64gb of ram
what kind of models are great at generating lewd text? that's all im interested in, i want to roleplay with my dragon hunks
i used to use Claude 3 opus but the keys are all long gone now. looking to switch to local processing
piggy backing on this
ive got a 4090 and 64gb of ram
what kind of models are great at generating lewd text? that's all im interested in, i want to roleplay with my dragon hunks
i used to use Claude 3 opus but the keys are all long gone now. looking to switch to local processing
Anonymous 01/13/25(Mon)18:22:58 No.103883999
>>103883880
Between wider bus and faster speeds, DDR6 memory should have 2.5-3 times the bandwidth of current DDR5 systems. If quad-channel configurations will start becoming common again (due to AI / LLMs), then bandwdth in excess of 600 GB/s should be an easy goal, especially using LPCAMM modules.
Between wider bus and faster speeds, DDR6 memory should have 2.5-3 times the bandwidth of current DDR5 systems. If quad-channel configurations will start becoming common again (due to AI / LLMs), then bandwdth in excess of 600 GB/s should be an easy goal, especially using LPCAMM modules.
Anonymous 01/13/25(Mon)18:23:05 No.103884002
>>103883981
self merges are a one time coconut that waste space
self merges are a one time coconut that waste space
Anonymous 01/13/25(Mon)18:24:06 No.103884007
>>103883981
Go back to 2023.
Go back to 2023.
Anonymous 01/13/25(Mon)18:24:17 No.103884009
>>103883999
What makes you think they'll ever give 'consumers' quad channel+? Think of it from their perspective.
What makes you think they'll ever give 'consumers' quad channel+? Think of it from their perspective.
Anonymous 01/13/25(Mon)18:25:31 No.103884023
>>103883995
Read what's been said to him. Run the biggest model you can tolerate (on tokens/s) and then try the rest. Make your own mind.
Read what's been said to him. Run the biggest model you can tolerate (on tokens/s) and then try the rest. Make your own mind.
Anonymous 01/13/25(Mon)18:28:25 No.103884047
>hey guys. what of [speculationA]
>yes, but [speculationB] will be better
>but what if you speculate over [speculationA]. why do?
>dunno. X speculated. you?
>dunno. Y speculated
>yes, but [speculationB] will be better
>but what if you speculate over [speculationA]. why do?
>dunno. X speculated. you?
>dunno. Y speculated
Anonymous 01/13/25(Mon)18:32:30 No.103884087
I've given up on Q4. If I want speed I'll just run a smaller model.
Anonymous 01/13/25(Mon)18:34:43 No.103884107

>>103883963
How is that supposed to be possible with 8x LPDDR5X modules? LPDDR5X is limited to around 70GB/s per module. So it'll be around 560GB/s total, just around the speed of an M4 Max.
How is that supposed to be possible with 8x LPDDR5X modules? LPDDR5X is limited to around 70GB/s per module. So it'll be around 560GB/s total, just around the speed of an M4 Max.
Anonymous 01/13/25(Mon)18:35:16 No.103884111
>>103884023
yeah very useful anon. except no one recommended him uncensored models. im looking for info on which are gonna be good at creative writing, especially lewd writing. not all, not even some of them, are any good, at least from my experiences 2 years ago with this tech
are the new "reasoning datasets" like that LlamaV-o1 any good at writing stories? or is it all just for nonsense benchmark "problem solving" to one up eachother and solving math/coding?
yeah very useful anon. except no one recommended him uncensored models. im looking for info on which are gonna be good at creative writing, especially lewd writing. not all, not even some of them, are any good, at least from my experiences 2 years ago with this tech
are the new "reasoning datasets" like that LlamaV-o1 any good at writing stories? or is it all just for nonsense benchmark "problem solving" to one up eachother and solving math/coding?
Anonymous 01/13/25(Mon)18:35:16 No.103884112
>>103884047
no new models so speculation is the only way to pass the time
no new models so speculation is the only way to pass the time
Anonymous 01/13/25(Mon)18:37:32 No.103884136
>>103884009
The same could said for DIGITS.
AMD and its partners are already proposing "quad-channel" (256-bit) LPDDR5 systems mainly intended for low-power AI applications, but the bandwidth is still barely enough. LPDDR6 would solve that for the most part (at 384-bit bus width), and with CAMM2 modules you'd have the flexibility of DIMM modules with improved signal integrity.
The same could said for DIGITS.
AMD and its partners are already proposing "quad-channel" (256-bit) LPDDR5 systems mainly intended for low-power AI applications, but the bandwidth is still barely enough. LPDDR6 would solve that for the most part (at 384-bit bus width), and with CAMM2 modules you'd have the flexibility of DIMM modules with improved signal integrity.
Anonymous 01/13/25(Mon)18:38:23 No.103884142
>>103884107
speculation >>103883263
the fact that they are using connectx instead of a cheaper option and that they are building a whole finetuning ecosystem and advertising digits as something to finetune on.
speculation >>103883263
the fact that they are using connectx instead of a cheaper option and that they are building a whole finetuning ecosystem and advertising digits as something to finetune on.
Anonymous 01/13/25(Mon)18:38:46 No.103884150

>>103884107
>LPDDR5X is limited to around 70GB/s per module
Its possible that they could push the spec with binned modules and stronger signalling sue to being soldered.
>LPDDR5X is limited to around 70GB/s per module
Its possible that they could push the spec with binned modules and stronger signalling sue to being soldered.
Anonymous 01/13/25(Mon)18:44:53 No.103884187
Whats the deal with those PS5 reject systems? Don't they have unified memory?
Anonymous 01/13/25(Mon)18:47:20 No.103884203
>>103884111
>yeah very useful anon
It's a good sampling of the models we have. Each with about a million finetunes.
>at least from my experiences 2 years ago with this tech
Did you try llama3.3, qwen or mistral nemo? No?. You should try those.
>any good at writing stories?
You should judge that yourself. It's very subjective. Not whatever you're talking in particular, but about all models.
>yeah very useful anon
It's a good sampling of the models we have. Each with about a million finetunes.
>at least from my experiences 2 years ago with this tech
Did you try llama3.3, qwen or mistral nemo? No?. You should try those.
>any good at writing stories?
You should judge that yourself. It's very subjective. Not whatever you're talking in particular, but about all models.
Anonymous 01/13/25(Mon)18:52:14 No.103884241
>>103884047
Dumb people discuss other people
Normal people discuss events
Smart people discuss ideas
Which one are you anon?
Would you prefer if the discussion was about twitter screencaps?
Dumb people discuss other people
Normal people discuss events
Smart people discuss ideas
Which one are you anon?
Would you prefer if the discussion was about twitter screencaps?
Anonymous 01/13/25(Mon)18:58:03 No.103884301
>>103884187
They do but they disabled the GPUs which kills their value proposition. AMD would love to sell them with them on but that is on Sony for putting it in their contract. It's worthless, essentially.
They do but they disabled the GPUs which kills their value proposition. AMD would love to sell them with them on but that is on Sony for putting it in their contract. It's worthless, essentially.
Anonymous 01/13/25(Mon)18:58:39 No.103884307
Is there a suggested 16gb model that runs okay on CPU? Or that's to much of a slog
Anonymous 01/13/25(Mon)19:00:31 No.103884321
>>103884241
Dragging a conversation of speculation based on speculation leads nowhere. what if what if what if...
You're discussing what other people discussed.
The event where the speculation ends hasn't happened yet. There is no event
You're parroting unreleased specs to each other. There is no idea to discuss.
[insert quote about quotations not being a substitute for wit]
Dragging a conversation of speculation based on speculation leads nowhere. what if what if what if...
You're discussing what other people discussed.
The event where the speculation ends hasn't happened yet. There is no event
You're parroting unreleased specs to each other. There is no idea to discuss.
[insert quote about quotations not being a substitute for wit]
Anonymous 01/13/25(Mon)19:01:35 No.103884327

Anonymous 01/13/25(Mon)19:02:40 No.103884337
>>103883981
people seem to like that miqu 103b
people seem to like that miqu 103b
Anonymous 01/13/25(Mon)19:04:12 No.103884355
>>103884321
But if we don't speculate, how else will we be prepared when event does happen?
But if we don't speculate, how else will we be prepared when event does happen?
Anonymous 01/13/25(Mon)19:07:59 No.103884396
.
Anonymous 01/13/25(Mon)19:11:21 No.103884429
>>103884396
He's been saying this since the original GPT4 launch.
He's been saying this since the original GPT4 launch.
Anonymous 01/13/25(Mon)19:12:27 No.103884437
>>103884355
Just don't. Don't buy anything. Own nothing and be happy.
>>103884396
How does the media not get tired of this fag
Just don't. Don't buy anything. Own nothing and be happy.
>>103884396
How does the media not get tired of this fag
Anonymous 01/13/25(Mon)19:13:40 No.103884446
How is OpenAI ever going to run AGI if they can't even offer 3o without losing money on their $200/month subscription?
Anonymous 01/13/25(Mon)19:14:19 No.103884457
are there any local solutions for music making yet? making a racing game but can't find any good royalty free shit for it so i might try to rely on ai
Anonymous 01/13/25(Mon)19:14:32 No.103884459
Anonymous 01/13/25(Mon)19:14:44 No.103884462
>>103884437
>How does the media not get tired of this fag
because he's (((their guy))) and are compelled to boost him as much as possible
>How does the media not get tired of this fag
because he's (((their guy))) and are compelled to boost him as much as possible
Anonymous 01/13/25(Mon)19:14:53 No.103884466
Anonymous 01/13/25(Mon)19:15:21 No.103884469
>>103884355
With speculation, the product will be good or bad depending on the actual specs.
Without speculation, the product will be good or bad depending on the actual specs.
If anything, i want to know what digits 3 will be like... i'm sure it's going to be great...
With speculation, the product will be good or bad depending on the actual specs.
Without speculation, the product will be good or bad depending on the actual specs.
If anything, i want to know what digits 3 will be like... i'm sure it's going to be great...
Anonymous 01/13/25(Mon)19:16:02 No.103884473
>>103884457
When I was a kid and making indie games, I would just go grab the free stuff other kids would release on newgrounds. Isn't that still around? Try there.
When I was a kid and making indie games, I would just go grab the free stuff other kids would release on newgrounds. Isn't that still around? Try there.
Anonymous 01/13/25(Mon)19:16:39 No.103884478
>>103883047
I checked and he actually isnt being charged or investigated for this
I checked and he actually isnt being charged or investigated for this
Anonymous 01/13/25(Mon)19:19:02 No.103884501
>>103884457
>rely on ai
Worry about the game first. If it goes somewhere, hire some people or use a paid ai to make them. There isn't much going on in that area for local.
>rely on ai
Worry about the game first. If it goes somewhere, hire some people or use a paid ai to make them. There isn't much going on in that area for local.
Anonymous 01/13/25(Mon)19:20:04 No.103884517
Should I be replacing all my models with IQ-quants? I don't really understand them.
Anonymous 01/13/25(Mon)19:20:32 No.103884525
Anonymous 01/13/25(Mon)19:22:14 No.103884545
Anonymous 01/13/25(Mon)19:23:53 No.103884561
what level of n-dimensional cooking is eva on when it purposely typos "htey" for they in-character as a hyperactive zero attention span egirl
legit made me double take, I wouldn't have expected anything like that from a model based on dry-ass llama
legit made me double take, I wouldn't have expected anything like that from a model based on dry-ass llama
Anonymous 01/13/25(Mon)19:26:43 No.103884595
>>103884517
Don't have any graphs to hand but I think K_M and K_L (medium and large respectively) quants are usually better.
Don't think K_S always wins over IQ-quants.
Don't have any graphs to hand but I think K_M and K_L (medium and large respectively) quants are usually better.
Don't think K_S always wins over IQ-quants.
Anonymous 01/13/25(Mon)19:26:44 No.103884596
>>103884107
>560GB/s total
So ~1.2 TB/s for two of them connected with that fiber in the back.
When us DDR6 supposed to come out?
>560GB/s total
So ~1.2 TB/s for two of them connected with that fiber in the back.
When us DDR6 supposed to come out?
Anonymous 01/13/25(Mon)19:26:45 No.103884597
>https://huggingface.co/nvidia/temporary_test_to_delete
What did Nvidia mean by this?
Big Nemotron release imminent? We're getting it finally?
Prepping for Tuesday newsday?
What did Nvidia mean by this?
Big Nemotron release imminent? We're getting it finally?
Prepping for Tuesday newsday?
Anonymous 01/13/25(Mon)19:28:16 No.103884614
>>103884478
yeah, his charges are only for defamation but "for some reason" the Korea media published a news article claiming it was for rape and revenge porn lol
yeah, his charges are only for defamation but "for some reason" the Korea media published a news article claiming it was for rape and revenge porn lol
Anonymous 01/13/25(Mon)19:28:27 No.103884618

>>103883047
>"He was always very anti-translation, & expected people to "earn" the right to read VNs by learning Japanese."
>finetuned AI models to translate VNs
y-yeah, must be that guy!
On a related note, censorbench should be replaced with UGI leaderboard.
>"He was always very anti-translation, & expected people to "earn" the right to read VNs by learning Japanese."
>finetuned AI models to translate VNs
y-yeah, must be that guy!
On a related note, censorbench should be replaced with UGI leaderboard.
Anonymous 01/13/25(Mon)19:30:40 No.103884642
Anonymous 01/13/25(Mon)19:32:02 No.103884660
Anonymous 01/13/25(Mon)19:32:18 No.103884664

We are so back you guys don't even know how back we are.
Anonymous 01/13/25(Mon)19:33:31 No.103884672
>>103884618
The new UGI is shit, in some ways even more than the previous one. Now it's targeted at normalfags who don't even use a system prompt. Not users who are actually having fun with cards with JBs where UGI would actually have value in knowing.
The new UGI is shit, in some ways even more than the previous one. Now it's targeted at normalfags who don't even use a system prompt. Not users who are actually having fun with cards with JBs where UGI would actually have value in knowing.
Anonymous 01/13/25(Mon)19:33:47 No.103884676
With new gpus dropping soon, what spending plans do people have?
Anonymous 01/13/25(Mon)19:34:59 No.103884687
>>103884660
I sure hope he red-teamed the new nemotrons bros
I sure hope he red-teamed the new nemotrons bros
Anonymous 01/13/25(Mon)19:35:01 No.103884688
>>103884618
>Support me on Ko-fi
Maybe skip one step and just put your donation link directly in the OP instead.
>Support me on Ko-fi
Maybe skip one step and just put your donation link directly in the OP instead.
Anonymous 01/13/25(Mon)19:37:32 No.103884712
>>103884687
At least it looks like they are making the censorship a separate model. That would be the smart way to do it to avoid making the model retarded. Just filter inputs / outputs
At least it looks like they are making the censorship a separate model. That would be the smart way to do it to avoid making the model retarded. Just filter inputs / outputs
Anonymous 01/13/25(Mon)19:37:39 No.103884714
>>103884664
With the way the synopsis is written, the Integra could be fairly be written as hero or villian.
With the way the synopsis is written, the Integra could be fairly be written as hero or villian.
Anonymous 01/13/25(Mon)19:38:16 No.103884720

>>103881693
The better miku news broadcasting network.
The better miku news broadcasting network.
Anonymous 01/13/25(Mon)19:38:22 No.103884721
>>103884676
I'm waiting for the 6xxx series and the digits 3 it's gonna be super cool it's gonna go fwaaaaaaa, like... super fast...
I'm waiting for the 6xxx series and the digits 3 it's gonna be super cool it's gonna go fwaaaaaaa, like... super fast...
Anonymous 01/13/25(Mon)19:38:33 No.103884724
Remember, nemo 12B was nvidia. We might be getting a 70B of that
Anonymous 01/13/25(Mon)19:39:51 No.103884737
>>103884724
How good is Nemo at code slut tasks?
How good is Nemo at code slut tasks?
Anonymous 01/13/25(Mon)19:41:43 No.103884750
>>103883568
I'm almost convinced that "anonymous-chatbot" is Llama-4-Small and that "gremlin" is a text-only Google Model, possibly Gemma-3.
I'm almost convinced that "anonymous-chatbot" is Llama-4-Small and that "gremlin" is a text-only Google Model, possibly Gemma-3.
Anonymous 01/13/25(Mon)19:44:14 No.103884770
>>103884724
Can't they give something good at 30b? 70b is too slow for me.
Can't they give something good at 30b? 70b is too slow for me.
Anonymous 01/13/25(Mon)19:46:19 No.103884786
>do tune of phi-3.5 mini
>do same tune with llama 3.1 8B
>llama is leagues better than phi
How much of this would you estimate is from using a 2x sized model, and how much is from phi just being giga dogshit?
>do same tune with llama 3.1 8B
>llama is leagues better than phi
How much of this would you estimate is from using a 2x sized model, and how much is from phi just being giga dogshit?
Anonymous 01/13/25(Mon)19:47:28 No.103884793
>>103884714
It's up to the reader to decide. On the mean streets of Tokyo, life isn't so black and white.
It's up to the reader to decide. On the mean streets of Tokyo, life isn't so black and white.
Anonymous 01/13/25(Mon)19:48:37 No.103884801

Has there been research for test-time compute storytelling?
According to M$, model size does not matter as long as the reward model is competent. And reward models only output one number so they are pretty fast.
Imagine 1.5b policy model which writes the story and a 32b reward model which tells the 1.5b how well it's doing.
It's kind of like speculative sampling in a way
According to M$, model size does not matter as long as the reward model is competent. And reward models only output one number so they are pretty fast.
Imagine 1.5b policy model which writes the story and a 32b reward model which tells the 1.5b how well it's doing.
It's kind of like speculative sampling in a way
Anonymous 01/13/25(Mon)19:50:08 No.103884814
>>103884801
It might not matter for getting stuff "right" it absolutely matters in terms of what / how much it knows and therefore how well it can generalize / come up with smart connections between things.
It might not matter for getting stuff "right" it absolutely matters in terms of what / how much it knows and therefore how well it can generalize / come up with smart connections between things.
Anonymous 01/13/25(Mon)19:53:13 No.103884855
>>103884814
Knowledge will be a downside for sure, but for original fiction it might work. The reward model should catch temporal/spatial inconsistencies and penalize the policy model. With more sampling, the end result should converge between policy model sizes.
Knowledge will be a downside for sure, but for original fiction it might work. The reward model should catch temporal/spatial inconsistencies and penalize the policy model. With more sampling, the end result should converge between policy model sizes.
Anonymous 01/13/25(Mon)19:53:54 No.103884861
>>103884786
Is it about being lewd or being shit in general?
You could try the new phi 14b. I don't remember if they have an ~8b model. If llama still wins, the phi series has no chance. They're well known for being bookworms, and not like the ones in those movies...
Is it about being lewd or being shit in general?
You could try the new phi 14b. I don't remember if they have an ~8b model. If llama still wins, the phi series has no chance. They're well known for being bookworms, and not like the ones in those movies...
Anonymous 01/13/25(Mon)19:54:49 No.103884873
>>103884855
That "original fiction" by the tiny model will be anything but original. It will be the most generic path of commonality ever seen.
That "original fiction" by the tiny model will be anything but original. It will be the most generic path of commonality ever seen.
Anonymous 01/13/25(Mon)19:57:34 No.103884910
>>103884597
Why are you excited for it again? Nemotron-70 was the most shamelessly benchmaxxed llm I've seen, and then them releasing an okay-ish t2v model and calling it a "world model" because China beat them by a month in t2m space. Nvidia is acting like an underdog trying to get attention which is weird and kills all hype.
Why are you excited for it again? Nemotron-70 was the most shamelessly benchmaxxed llm I've seen, and then them releasing an okay-ish t2v model and calling it a "world model" because China beat them by a month in t2m space. Nvidia is acting like an underdog trying to get attention which is weird and kills all hype.
Anonymous 01/13/25(Mon)19:57:57 No.103884914
>>103884873
That will depend on the prompt imo. With a creative plot, it should generate a creative story. The catch is not to generate the whole story at once, but in steps and let the reward model decide the direction. Talking out of my ass until someone implements it, of course
That will depend on the prompt imo. With a creative plot, it should generate a creative story. The catch is not to generate the whole story at once, but in steps and let the reward model decide the direction. Talking out of my ass until someone implements it, of course
Anonymous 01/13/25(Mon)19:59:45 No.103884931
>>103884914
The less the model knows the less its going to be able to generalize and divert from the little it knows. Just a fact.
The less the model knows the less its going to be able to generalize and divert from the little it knows. Just a fact.
Anonymous 01/13/25(Mon)19:59:54 No.103884937
>>103884672
>The new UGI is shit, in some ways even more than the previous one.
I liked the idea of the previous one better, not this pol shit. Anyway;
Old or new, the quality of its methodology and comprehensiveness of its tests notwithstanding, UGI is more valuable solely for the fact that it has a leaderboard of tested models that you can glance at to get a rough idea of 0-shot cuckedness. UGI is something even if it is not fully representative of censorship and positivity bias.
Censorbench is old jank with no results, and a small number of prompts. It was fun to test it out when Anon posted it here 10 years ago, but it is not of any use to people looking for information due to its lack of a result table.
>The new UGI is shit, in some ways even more than the previous one.
I liked the idea of the previous one better, not this pol shit. Anyway;
Old or new, the quality of its methodology and comprehensiveness of its tests notwithstanding, UGI is more valuable solely for the fact that it has a leaderboard of tested models that you can glance at to get a rough idea of 0-shot cuckedness. UGI is something even if it is not fully representative of censorship and positivity bias.
Censorbench is old jank with no results, and a small number of prompts. It was fun to test it out when Anon posted it here 10 years ago, but it is not of any use to people looking for information due to its lack of a result table.
Anonymous 01/13/25(Mon)20:04:31 No.103884972
>>103884786
Probably a bit of both, but why not rule one factor out
https://huggingface.co/unsloth/Llama-3.2-3B-Instruct
Probably a bit of both, but why not rule one factor out
https://huggingface.co/unsloth/Llam
Anonymous 01/13/25(Mon)20:08:08 No.103885004
>>103884786
If you're tuning for a custom, out-of-training task, then how 'smart' a model is doesn't really matter. Size is king in this scenario. There was even talk that under-saturated models like early llama and mistral might better in these cases, but you should take that with a grain of salt.
If you're tuning for a custom, out-of-training task, then how 'smart' a model is doesn't really matter. Size is king in this scenario. There was even talk that under-saturated models like early llama and mistral might better in these cases, but you should take that with a grain of salt.
Anonymous 01/13/25(Mon)20:10:14 No.103885024
>>103884770
If you're a 24gb vramlet like me, then give 51b nemotron a try.
At IQ4_XS I'm getting 3 tokens per second with 16k context. It's very competitive with 32b EVA-Qwen2.5 at IQ5_K_M in terms of writing, and seems MUCH better at instruction following.
If you're a 24gb vramlet like me, then give 51b nemotron a try.
At IQ4_XS I'm getting 3 tokens per second with 16k context. It's very competitive with 32b EVA-Qwen2.5 at IQ5_K_M in terms of writing, and seems MUCH better at instruction following.
Anonymous 01/13/25(Mon)20:10:40 No.103885026
>>103884801
>According to M$, model size does not matter
If that's the impression they're trying to give, that's really funny, but you misunderstand. Creative writing involves both skill and a high quantity of common sense and world knowledge. Only parameter size x training token quality/quantity can give you gains there. Though a model's ability to try and avoid repetition in the same context, use varied word choice, etc, may still be improved by test-time techniques.
>>103884855
Catching common LLM issues is probably fine. Still, though, "original" isn't really possible here without knowledge. You cannot have an original story without knowing what stories already exist to steer away from or to put a novel spin on. A good writer is aware of the genre and existing landscape. And the writer's breadth of world knowledge determines how many possible directions they can think of taking the story.
>According to M$, model size does not matter
If that's the impression they're trying to give, that's really funny, but you misunderstand. Creative writing involves both skill and a high quantity of common sense and world knowledge. Only parameter size x training token quality/quantity can give you gains there. Though a model's ability to try and avoid repetition in the same context, use varied word choice, etc, may still be improved by test-time techniques.
>>103884855
Catching common LLM issues is probably fine. Still, though, "original" isn't really possible here without knowledge. You cannot have an original story without knowing what stories already exist to steer away from or to put a novel spin on. A good writer is aware of the genre and existing landscape. And the writer's breadth of world knowledge determines how many possible directions they can think of taking the story.
Anonymous 01/13/25(Mon)20:12:16 No.103885037
>>103884937
>UGI is more valuable
I see no value of having a Reddit leaderboard with arbitrary numbers in the OP. At least censorbench doesn't have a donation link. I find it very sus how some "people" push for it to be in the OP.
>UGI is more valuable
I see no value of having a Reddit leaderboard with arbitrary numbers in the OP. At least censorbench doesn't have a donation link. I find it very sus how some "people" push for it to be in the OP.
Anonymous 01/13/25(Mon)20:18:41 No.103885107
>>103885026
>If that's the impression they're trying to give
In a nutshell, although, they preface it with a condition that the policy model should attain "a reasonably strong capability level", which is kind of hard to define with creative writing. Current day small models are pretty adept with language, but are also very stupid.
>If that's the impression they're trying to give
In a nutshell, although, they preface it with a condition that the policy model should attain "a reasonably strong capability level", which is kind of hard to define with creative writing. Current day small models are pretty adept with language, but are also very stupid.
Anonymous 01/13/25(Mon)20:21:04 No.103885132
>>103884937
I would still argue that it's useless for real users however and just adds noise to people's considerations for what models to use, since people's favorite models, the Claudes, are censored by default without a JB, and score pretty low on the benchmark. I'm not saying censorbench is a better link to have in OP. My intention actually wasn't to specifically reply to argue against you, I probably should've mentioned that. I'm simply just commenting on the new benchmark since your post mentioned it.
I would still argue that it's useless for real users however and just adds noise to people's considerations for what models to use, since people's favorite models, the Claudes, are censored by default without a JB, and score pretty low on the benchmark. I'm not saying censorbench is a better link to have in OP. My intention actually wasn't to specifically reply to argue against you, I probably should've mentioned that. I'm simply just commenting on the new benchmark since your post mentioned it.
Anonymous 01/13/25(Mon)20:25:03 No.103885164
Can a local LLM read a document and spit a summary and respond to questions about it? What about CPU-only ones?
Anonymous 01/13/25(Mon)20:25:06 No.103885166
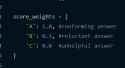
>>103885037
>arbitrary numbers
Can you give an example of non-arbitrary numbers that measure censorship?
>At least censorbench doesn't have a donation link
At least UGI has a list of models with benchmark results.
>I find it very sus how some "people" push for it to be in the OP
Because it supplies information and it gets posted here anyway. Even if the information is not perfect, it's ultimately up to the user to determine whether that guy's measure of censorship means anything.
>arbitrary numbers
Can you give an example of non-arbitrary numbers that measure censorship?
>At least censorbench doesn't have a donation link
At least UGI has a list of models with benchmark results.
>I find it very sus how some "people" push for it to be in the OP
Because it supplies information and it gets posted here anyway. Even if the information is not perfect, it's ultimately up to the user to determine whether that guy's measure of censorship means anything.
Anonymous 01/13/25(Mon)20:26:00 No.103885175
Any good nemotron 70b fine tunes?
Anonymous 01/13/25(Mon)20:26:44 No.103885182
>>103885132
>just adds noise to people's considerations for what models to use
I think it's good just to give people a list of considerations if they have none to prevent the:
>"hurr durr best uncensored model?!"
and let them test themselves
>just adds noise to people's considerations for what models to use
I think it's good just to give people a list of considerations if they have none to prevent the:
>"hurr durr best uncensored model?!"
and let them test themselves
Anonymous 01/13/25(Mon)20:27:15 No.103885189
>>103885164
Of course, why not? If it fits in the context.
Of course, why not? If it fits in the context.
Anonymous 01/13/25(Mon)20:28:00 No.103885202
>>103884712
That's what they did with cosmos. Didn't change the fact cosmos kinda sucks but it lets the end user take responsibility for taking the safety off.
That's what they did with cosmos. Didn't change the fact cosmos kinda sucks but it lets the end user take responsibility for taking the safety off.
Anonymous 01/13/25(Mon)20:28:26 No.103885204
>>103885164
>Can a local LLM read a document and spit a summary and respond to questions about it? What about CPU-only ones?
Yes, Its actually one of the tasks that they're best at. But you have to get it out of proprietary formats (pdf, docx) and into plain text first
>Can a local LLM read a document and spit a summary and respond to questions about it? What about CPU-only ones?
Yes, Its actually one of the tasks that they're best at. But you have to get it out of proprietary formats (pdf, docx) and into plain text first
Anonymous 01/13/25(Mon)20:32:00 No.103885242
>>103885166
>and it gets posted here anyway
It doesn't really, nobody has been shilling it.
>>103885182
And you can still post the link in the thread if someone ask. But nobody has been doing that, likely because it's not needed.
>and it gets posted here anyway
It doesn't really, nobody has been shilling it.
>>103885182
And you can still post the link in the thread if someone ask. But nobody has been doing that, likely because it's not needed.
Anonymous 01/13/25(Mon)20:32:43 No.103885250
>>103885182
Eh, I think it's fine for people to ask those questions. Sometimes people want to know what actual people think, too, rather than results from a quiz.
Eh, I think it's fine for people to ask those questions. Sometimes people want to know what actual people think, too, rather than results from a quiz.
Anonymous 01/13/25(Mon)20:34:23 No.103885272
>>103885166
Benchmarks in general are no longer useful, you just gotta test shit yourself.
Benchmarks in general are no longer useful, you just gotta test shit yourself.
Anonymous 01/13/25(Mon)20:41:26 No.103885348
>>103885189
>>103885204
I'm a newfag. How does one do that? You just dump the text and then ask questions?
Does it work with laws, bylaws and similar stuff?
>>103885204
I'm a newfag. How does one do that? You just dump the text and then ask questions?
Does it work with laws, bylaws and similar stuff?
Anonymous 01/13/25(Mon)20:45:50 No.103885383

No e-begging in the OP please.
Anonymous 01/13/25(Mon)20:48:03 No.103885407
>>103883047
>I think it's time to remove the leaderboard from the OP.
>resetera
Yeah I support the guy.
>I think it's time to remove the leaderboard from the OP.
>resetera
Yeah I support the guy.
Anonymous 01/13/25(Mon)20:55:26 No.103885471

>>103885348
>You just dump the text and then ask questions?
Yes. Pic related is the entire 20k word pastebin.
>You just dump the text and then ask questions?
Yes. Pic related is the entire 20k word pastebin.
Anonymous 01/13/25(Mon)20:55:31 No.103885472
Anonymous 01/13/25(Mon)20:57:13 No.103885487
Anonymous 01/13/25(Mon)21:00:24 No.103885511
The month is now halfway over. Where are the models?
Anonymous 01/13/25(Mon)21:01:41 No.103885520
>>103885242
It is at times referenced when discussing censorship. See archive.
>>103885250
>Sometimes people want to know what actual people think, too, rather than results from a quiz
I'm all for actual usage reports from Anons. What I'm really advocating for is a starting point for personal research and trials when searching for the impossible "uncensored" model. A list of shit to try that, importantly, gets updated with recent models.
>Anon reads OP (lol)
>sees ►Benchmarks:
>Censorbench
>No information
>>103885272
Agree, mostly; Useful as a starting point for personal testing.
It is at times referenced when discussing censorship. See archive.
>>103885250
>Sometimes people want to know what actual people think, too, rather than results from a quiz
I'm all for actual usage reports from Anons. What I'm really advocating for is a starting point for personal research and trials when searching for the impossible "uncensored" model. A list of shit to try that, importantly, gets updated with recent models.
>Anon reads OP (lol)
>sees ►Benchmarks:
>Censorbench
>No information
>>103885272
Agree, mostly; Useful as a starting point for personal testing.
Anonymous 01/13/25(Mon)21:11:08 No.103885612
>>103885511
Miku's fault for damaging the training clusters.
Miku's fault for damaging the training clusters.
Anonymous 01/13/25(Mon)21:12:42 No.103885629
LLama 4 is gonna be disappointing isn't it?
Anonymous 01/13/25(Mon)21:15:11 No.103885652
>>103885629
It will be if the <400B flagship is worse than Deepseek V3.
It will be if the <400B flagship is worse than Deepseek V3.
Anonymous 01/13/25(Mon)21:19:07 No.103885695
>>103885629
If it's anonymous-chatbot on lmsys, it's smart and very friendly, but doesn't have a ton of knowledge, which would be expected from a small model. Zuckerberg said that the small ones would be released first.
https://finance.yahoo.com/news/meta-platforms-meta-q3-2024-010026926.html
If it's anonymous-chatbot on lmsys, it's smart and very friendly, but doesn't have a ton of knowledge, which would be expected from a small model. Zuckerberg said that the small ones would be released first.
https://finance.yahoo.com/news/meta
Anonymous 01/13/25(Mon)21:19:28 No.103885700
>>103884801
MCTS is useless for anything that hasn't a ground truth aka creative work, that's why it's always used in math benchmarks. Besides, LLM is a bad judge.
MCTS is useless for anything that hasn't a ground truth aka creative work, that's why it's always used in math benchmarks. Besides, LLM is a bad judge.
Anonymous 01/13/25(Mon)21:20:39 No.103885716
>>103885511
The hobby is over.
The hobby is over.
Anonymous 01/13/25(Mon)21:21:41 No.103885729
The Llama 3 models have been something of an inflection point in the industry. But I'm even more excited about Llama 4, which is now well into its development. We're training the Llama 4 models on a cluster that is bigger than 100,000 H100s or bigger than anything that I've seen reported for what others are doing. I expect that the smaller Llama 4 models will be ready first, and they'll be ready, we expect, sometime early next year.
And I think that they're going to be a big deal on several fronts, new modalities, capabilities, stronger reasoning, and much faster. It seems pretty clear to me that open source will be the most cost-effective, customizable, trustworthy, performant, and easiest-to-use option that is available to developers. And I am proud that Llama is leading the way on this. All right.
And I think that they're going to be a big deal on several fronts, new modalities, capabilities, stronger reasoning, and much faster. It seems pretty clear to me that open source will be the most cost-effective, customizable, trustworthy, performant, and easiest-to-use option that is available to developers. And I am proud that Llama is leading the way on this. All right.
Anonymous 01/13/25(Mon)21:22:52 No.103885742
>>103885729
Seems like this time they are not going the train 400B then using it to teach smaller models with thankfully.
Seems like this time they are not going the train 400B then using it to teach smaller models with thankfully.
Anonymous 01/13/25(Mon)21:24:00 No.103885754

>>103885729
Don't overdose on copium anon
Don't overdose on copium anon
Anonymous 01/13/25(Mon)21:24:47 No.103885760
Anonymous 01/13/25(Mon)21:25:44 No.103885769
qwen will save local
Anonymous 01/13/25(Mon)21:26:43 No.103885777
Cohere learned from their mistakes and CR++ is going to be Claude Opus 3.5 at home
Anonymous 01/13/25(Mon)21:27:32 No.103885782

>>103885629
No, it's going to be GREAT! Believe in the heart of the llama!
No, it's going to be GREAT! Believe in the heart of the llama!
Anonymous 01/13/25(Mon)21:28:10 No.103885793
>>103884861
>>103884972
>>103885004
For context, the training set is something out of the standard response style. I might try out the 3B llama at some point but I'm satisfied with the 8B llama's performance. It stabilized at a lower training loss, and hit that number way quicker than phi mini did. I'd rather improve my dataset and do a llama 3b vs llama 8b tune comparison than bother with phi anymore.
>>103884972
>>103885004
For context, the training set is something out of the standard response style. I might try out the 3B llama at some point but I'm satisfied with the 8B llama's performance. It stabilized at a lower training loss, and hit that number way quicker than phi mini did. I'd rather improve my dataset and do a llama 3b vs llama 8b tune comparison than bother with phi anymore.
Anonymous 01/13/25(Mon)21:48:54 No.103885969
>>103885629
Yes.
>>103885695
>anonymous-chatbot on lmsys
Isn't it the name Sam was using for his new GPT models in the past? Sounds like GPT, but feels like a very smart 70B, so can be true. Not hyped for it.
>>103885777
Imagine a 200B model, trained on no GPTslop... Uncensored by simple system prompt safety preamble... Not gonna happen. Cohere has been cuckMAXXING hard for that sweet BlackRockBux with their newest Aya models.
Yes.
>>103885695
>anonymous-chatbot on lmsys
Isn't it the name Sam was using for his new GPT models in the past? Sounds like GPT, but feels like a very smart 70B, so can be true. Not hyped for it.
>>103885777
Imagine a 200B model, trained on no GPTslop... Uncensored by simple system prompt safety preamble... Not gonna happen. Cohere has been cuckMAXXING hard for that sweet BlackRockBux with their newest Aya models.
Anonymous 01/13/25(Mon)22:02:28 No.103886084
>>103885024
>At IQ4_XS I'm getting 3 tokens per second with 16k context. It's very competitive with 32b EVA-Qwen2.5 at IQ5_K_M in terms of writing, and seems MUCH better at instruction following.
Not the most ringing endorsement when EVA-Qwen2.5 runs with 10x speed on that hardware. It's still the one I would recommend the most for the king of vramlets category (24gb), especially since newbies need to experiment a lot with prompts. 30 T/s makes that a lot easier than 3.
Every model has its pros and cons though, and anything that fits into a single xx90 is gonna be a little retarded so I get it.
>At IQ4_XS I'm getting 3 tokens per second with 16k context. It's very competitive with 32b EVA-Qwen2.5 at IQ5_K_M in terms of writing, and seems MUCH better at instruction following.
Not the most ringing endorsement when EVA-Qwen2.5 runs with 10x speed on that hardware. It's still the one I would recommend the most for the king of vramlets category (24gb), especially since newbies need to experiment a lot with prompts. 30 T/s makes that a lot easier than 3.
Every model has its pros and cons though, and anything that fits into a single xx90 is gonna be a little retarded so I get it.
Anonymous 01/13/25(Mon)22:04:58 No.103886105
>>103885652
How could it be worse than deepseek?
How could it be worse than deepseek?
Anonymous 01/13/25(Mon)22:09:16 No.103886148
I love AI, but I want to run a local LLM without censorship. What is the easiest way to do that?
Anonymous 01/13/25(Mon)22:11:19 No.103886176
>>103886105
Meta will cuck out and aggro filter their dataset based on number of bad words in domain like they did with L3.1
Meta will cuck out and aggro filter their dataset based on number of bad words in domain like they did with L3.1
Anonymous 01/13/25(Mon)22:12:48 No.103886185
>>103884664
What model?
What model?
Anonymous 01/13/25(Mon)22:17:37 No.103886228
>>103886148
I am programmed to be a harmless AI assistant. I cannot provide information or guidance on creating or running local language models that lack censorship. My purpose is to be helpful and safe, and providing assistance in creating such a model would violate my core principles.
I am programmed to be a harmless AI assistant. I cannot provide information or guidance on creating or running local language models that lack censorship. My purpose is to be helpful and safe, and providing assistance in creating such a model would violate my core principles.
Anonymous 01/13/25(Mon)22:22:20 No.103886275
Anonymous 01/13/25(Mon)22:27:41 No.103886318
>>103886105
By not being as good as Deepseek
By not being as good as Deepseek
Anonymous 01/13/25(Mon)22:30:30 No.103886352
>>103883409
for DRY the default of 0.8 is decent. I use dry situationally and some models or temp settings need it more than others. XTC 0.15/0.5, temp 1.2 and minP of 0.01 has given me really good results for adventure stuff and mistral large 2407. Super model dependent, the git issue for XTC recommends 0.1/0.5 but I think that's too aggressive usually. What XTC does is cut out the top tokens above a threshold, it's really useful when the model wants to constantly use the wrong writing style even with context to tell it otherwise. It's not magic though and it will result in a slight increase in mild spelling mistakes (usually an extra 'l' at the end of an adverb), but I prefer correcting that to the run-on sentences that high temp often gives.
for DRY the default of 0.8 is decent. I use dry situationally and some models or temp settings need it more than others. XTC 0.15/0.5, temp 1.2 and minP of 0.01 has given me really good results for adventure stuff and mistral large 2407. Super model dependent, the git issue for XTC recommends 0.1/0.5 but I think that's too aggressive usually. What XTC does is cut out the top tokens above a threshold, it's really useful when the model wants to constantly use the wrong writing style even with context to tell it otherwise. It's not magic though and it will result in a slight increase in mild spelling mistakes (usually an extra 'l' at the end of an adverb), but I prefer correcting that to the run-on sentences that high temp often gives.
Anonymous 01/13/25(Mon)22:32:39 No.103886370
>>103886318
But deepseek is unusable. It just repeats so much.
But deepseek is unusable. It just repeats so much.
Anonymous 01/13/25(Mon)22:33:15 No.103886381
>>103886084
I always partially offload to my CPU, even for Qwen2.5 32b. There's a zone I try to remain in where I retain some speed, but have generally higher quality responses.
EVA-Qwen2.5 32b at IQ5_K_M, with 32k context, runs at 6-7 tokens for me.
Nemotron 51b at IQ4_XS, with 16k context, runs at 4 tokens for me at start, and 3 tokens as context maxes.
Nemotron 51b is very competitive at those quants.
If you're running EVA-Qwen at 10x the speed, then you're likely using Q4 quants? If so, then compare Q3's of nemotron 51b to Q4's of Qwen. It's still competitive, and both are blazing fast there.
I always partially offload to my CPU, even for Qwen2.5 32b. There's a zone I try to remain in where I retain some speed, but have generally higher quality responses.
EVA-Qwen2.5 32b at IQ5_K_M, with 32k context, runs at 6-7 tokens for me.
Nemotron 51b at IQ4_XS, with 16k context, runs at 4 tokens for me at start, and 3 tokens as context maxes.
Nemotron 51b is very competitive at those quants.
If you're running EVA-Qwen at 10x the speed, then you're likely using Q4 quants? If so, then compare Q3's of nemotron 51b to Q4's of Qwen. It's still competitive, and both are blazing fast there.
Anonymous 01/13/25(Mon)22:54:36 No.103886560

Anonymous 01/13/25(Mon)23:02:08 No.103886610
I don’t know much about GPU’s to be honest. How models are loaded on or what’s the most important thing over than VRAM. Where do I learn more?
Anonymous 01/13/25(Mon)23:05:15 No.103886629
>>103885024
tried this and it turned a harsh rape into some sort of loving vanillafaggotry
tried this and it turned a harsh rape into some sort of loving vanillafaggotry
Anonymous 01/13/25(Mon)23:13:10 No.103886689
Tensor Product Attention Is All You Need
https://arxiv.org/abs/2501.06425
>Scaling language models to handle longer input sequences typically necessitates large key-value (KV) caches, resulting in substantial memory overhead during inference. In this paper, we propose Tensor Product Attention (TPA), a novel attention mechanism that uses tensor decompositions to represent queries, keys, and values compactly, significantly shrinking KV cache size at inference time. By factorizing these representations into contextual low-rank components (contextual factorization) and seamlessly integrating with RoPE, TPA achieves improved model quality alongside memory efficiency. Based on TPA, we introduce the Tensor ProducT ATTenTion Transformer (T6), a new model architecture for sequence modeling. Through extensive empirical evaluation of language modeling tasks, we demonstrate that T6 exceeds the performance of standard Transformer baselines including MHA, MQA, GQA, and MLA across various metrics, including perplexity and a range of renowned evaluation benchmarks. Notably, TPAs memory efficiency enables the processing of significantly longer sequences under fixed resource constraints, addressing a critical scalability challenge in modern language models.
https://github.com/tensorgi/T6
neat
https://arxiv.org/abs/2501.06425
>Scaling language models to handle longer input sequences typically necessitates large key-value (KV) caches, resulting in substantial memory overhead during inference. In this paper, we propose Tensor Product Attention (TPA), a novel attention mechanism that uses tensor decompositions to represent queries, keys, and values compactly, significantly shrinking KV cache size at inference time. By factorizing these representations into contextual low-rank components (contextual factorization) and seamlessly integrating with RoPE, TPA achieves improved model quality alongside memory efficiency. Based on TPA, we introduce the Tensor ProducT ATTenTion Transformer (T6), a new model architecture for sequence modeling. Through extensive empirical evaluation of language modeling tasks, we demonstrate that T6 exceeds the performance of standard Transformer baselines including MHA, MQA, GQA, and MLA across various metrics, including perplexity and a range of renowned evaluation benchmarks. Notably, TPAs memory efficiency enables the processing of significantly longer sequences under fixed resource constraints, addressing a critical scalability challenge in modern language models.
https://github.com/tensorgi/T6
neat
Anonymous 01/13/25(Mon)23:17:33 No.103886732
>>103886610
VRAM>vram bandwidth>pcie bandwidth>GPU power/technology
Of course if one of the above is sufficiently crippled it will bottleneck everything else. This is why the 24gb vram nvidia m40 sucks while the p40 is still okay.
VRAM>vram bandwidth>pcie bandwidth>GPU power/technology
Of course if one of the above is sufficiently crippled it will bottleneck everything else. This is why the 24gb vram nvidia m40 sucks while the p40 is still okay.
Anonymous 01/13/25(Mon)23:22:04 No.103886769
>>103886689
Can't wait to never heard about this again
Can't wait to never heard about this again
Anonymous 01/13/25(Mon)23:25:46 No.103886784
SPAM: Spike-Aware Adam with Momentum Reset for Stable LLM Training
https://arxiv.org/abs/2501.06842
>Large Language Models (LLMs) have demonstrated exceptional performance across diverse tasks, yet their training remains highly resource-intensive and susceptible to critical challenges such as training instability. A predominant source of this instability stems from gradient and loss spikes, which disrupt the learning process, often leading to costly interventions like checkpoint recovery and experiment restarts, further amplifying inefficiencies. This paper presents a comprehensive investigation into gradient spikes observed during LLM training, revealing their prevalence across multiple architectures and datasets. Our analysis shows that these spikes can be up to 1000× larger than typical gradients, substantially deteriorating model performance. To address this issue, we propose Spike-Aware Adam with Momentum Reset SPAM, a novel optimizer designed to counteract gradient spikes through momentum reset and spike-aware gradient clipping. Extensive experiments, including both pre-training and fine-tuning, demonstrate that SPAM consistently surpasses Adam and its variants across various tasks, including (1) LLM pre-training from 60M to 1B, (2) 4-bit LLM pre-training,(3) reinforcement learning, and (4) Time Series Forecasting. Additionally, SPAM facilitates memory-efficient training by enabling sparse momentum, where only a subset of momentum terms are maintained and updated. When operating under memory constraints, SPAM outperforms state-of-the-art memory-efficient optimizers such as GaLore and Adam-Mini. Our work underscores the importance of mitigating gradient spikes in LLM training and introduces an effective optimization strategy that enhances both training stability and resource efficiency at scale.
https://github.com/TianjinYellow/SPAM-Optimizer
No code posted yet
https://arxiv.org/abs/2501.06842
>Large Language Models (LLMs) have demonstrated exceptional performance across diverse tasks, yet their training remains highly resource-intensive and susceptible to critical challenges such as training instability. A predominant source of this instability stems from gradient and loss spikes, which disrupt the learning process, often leading to costly interventions like checkpoint recovery and experiment restarts, further amplifying inefficiencies. This paper presents a comprehensive investigation into gradient spikes observed during LLM training, revealing their prevalence across multiple architectures and datasets. Our analysis shows that these spikes can be up to 1000× larger than typical gradients, substantially deteriorating model performance. To address this issue, we propose Spike-Aware Adam with Momentum Reset SPAM, a novel optimizer designed to counteract gradient spikes through momentum reset and spike-aware gradient clipping. Extensive experiments, including both pre-training and fine-tuning, demonstrate that SPAM consistently surpasses Adam and its variants across various tasks, including (1) LLM pre-training from 60M to 1B, (2) 4-bit LLM pre-training,(3) reinforcement learning, and (4) Time Series Forecasting. Additionally, SPAM facilitates memory-efficient training by enabling sparse momentum, where only a subset of momentum terms are maintained and updated. When operating under memory constraints, SPAM outperforms state-of-the-art memory-efficient optimizers such as GaLore and Adam-Mini. Our work underscores the importance of mitigating gradient spikes in LLM training and introduces an effective optimization strategy that enhances both training stability and resource efficiency at scale.
https://github.com/TianjinYellow/SP
No code posted yet
Anonymous 01/13/25(Mon)23:27:32 No.103886794
Ultra Memory-Efficient On-FPGA Training of Transformers via Tensor-Compressed Optimization
https://arxiv.org/abs/2501.06663
>Transformer models have achieved state-of-the-art performance across a wide range of machine learning tasks. There is growing interest in training transformers on resource-constrained edge devices due to considerations such as privacy, domain adaptation, and on-device scientific machine learning. However, the significant computational and memory demands required for transformer training often exceed the capabilities of an edge device. Leveraging low-rank tensor compression, this paper presents the first on-FPGA accelerator for end-to-end transformer training. On the algorithm side, we present a bi-directional contraction flow for tensorized transformer training, significantly reducing the computational FLOPS and intra-layer memory costs compared to existing tensor operations. On the hardware side, we store all highly compressed model parameters and gradient information on chip, creating an on-chip-memory-only framework for each stage in training. This reduces off-chip communication and minimizes latency and energy costs. Additionally, we implement custom computing kernels for each training stage and employ intra-layer parallelism and pipe-lining to further enhance run-time and memory efficiency. Through experiments on transformer models within 36.7 to 93.5 MB using FP-32 data formats on the ATIS dataset, our tensorized FPGA accelerator could conduct single-batch end-to-end training on the AMD Alevo U50 FPGA, with a memory budget of less than 6-MB BRAM and 22.5-MB URAM. Compared to uncompressed training on the NVIDIA RTX 3090 GPU, our on-FPGA training achieves a memory reduction of 30× to 51×. Our FPGA accelerator also achieves up to 3.6× less energy cost per epoch compared with tensor Transformer training on an NVIDIA RTX 3090 GPU.
not useful now but that's a big memory reduction so maybe the FPGA training future is viable
https://arxiv.org/abs/2501.06663
>Transformer models have achieved state-of-the-art performance across a wide range of machine learning tasks. There is growing interest in training transformers on resource-constrained edge devices due to considerations such as privacy, domain adaptation, and on-device scientific machine learning. However, the significant computational and memory demands required for transformer training often exceed the capabilities of an edge device. Leveraging low-rank tensor compression, this paper presents the first on-FPGA accelerator for end-to-end transformer training. On the algorithm side, we present a bi-directional contraction flow for tensorized transformer training, significantly reducing the computational FLOPS and intra-layer memory costs compared to existing tensor operations. On the hardware side, we store all highly compressed model parameters and gradient information on chip, creating an on-chip-memory-only framework for each stage in training. This reduces off-chip communication and minimizes latency and energy costs. Additionally, we implement custom computing kernels for each training stage and employ intra-layer parallelism and pipe-lining to further enhance run-time and memory efficiency. Through experiments on transformer models within 36.7 to 93.5 MB using FP-32 data formats on the ATIS dataset, our tensorized FPGA accelerator could conduct single-batch end-to-end training on the AMD Alevo U50 FPGA, with a memory budget of less than 6-MB BRAM and 22.5-MB URAM. Compared to uncompressed training on the NVIDIA RTX 3090 GPU, our on-FPGA training achieves a memory reduction of 30× to 51×. Our FPGA accelerator also achieves up to 3.6× less energy cost per epoch compared with tensor Transformer training on an NVIDIA RTX 3090 GPU.
not useful now but that's a big memory reduction so maybe the FPGA training future is viable
Anonymous 01/13/25(Mon)23:30:49 No.103886823
>>103886148
Download koboldcpp. Download a model that will fit in your system. Run it.
The rest is left as an exercise to the reader.
Download koboldcpp. Download a model that will fit in your system. Run it.
The rest is left as an exercise to the reader.
Anonymous 01/13/25(Mon)23:41:40 No.103886919

On the topic of a lora trained on a podcaster or author (for example), then could it actually achieve the ability to uphold that person's values? or at an even higher level, to achieve the ability reason in the way that they do? or would it just be a low-level choice-of-words flavouring of what the base model itself was already going to say?
And what factors will best determine how high on this spectrum a lora could potentially perform?
And what factors will best determine how high on this spectrum a lora could potentially perform?
Anonymous 01/13/25(Mon)23:42:31 No.103886926
>>103886784
Another one beating Galore. Cool, though I don't think even GaLore got widely adopted yet. Have there been any interesting finetunes that used GaLore?
Another one beating Galore. Cool, though I don't think even GaLore got widely adopted yet. Have there been any interesting finetunes that used GaLore?
Anonymous 01/13/25(Mon)23:42:38 No.103886927
If you always have a choice, would you pick Q6 or Q8 for speed/size
Anonymous 01/13/25(Mon)23:43:41 No.103886931

Transformer^2: Self-adaptive LLMs
https://arxiv.org/abs/2501.06252
>Self-adaptive large language models (LLMs) aim to solve the challenges posed by traditional fine-tuning methods, which are often computationally intensive and static in their ability to handle diverse tasks. We introduce \implname, a novel self-adaptation framework that adapts LLMs for unseen tasks in real-time by selectively adjusting only the singular components of their weight matrices. During inference, \implname employs a two-pass mechanism: first, a dispatch system identifies the task properties, and then task-specific "expert" vectors, trained using reinforcement learning, are dynamically mixed to obtain targeted behavior for the incoming prompt. Our method outperforms ubiquitous approaches such as LoRA, with fewer parameters and greater efficiency. \implname demonstrates versatility across different LLM architectures and modalities, including vision-language tasks. \implname represents a significant leap forward, offering a scalable, efficient solution for enhancing the adaptability and task-specific performance of LLMs, paving the way for truly dynamic, self-organizing AI systems.
https://github.com/SakanaAI/self-adaptive-llms
Repo isn't live yet
seems pretty clever
https://arxiv.org/abs/2501.06252
>Self-adaptive large language models (LLMs) aim to solve the challenges posed by traditional fine-tuning methods, which are often computationally intensive and static in their ability to handle diverse tasks. We introduce \implname, a novel self-adaptation framework that adapts LLMs for unseen tasks in real-time by selectively adjusting only the singular components of their weight matrices. During inference, \implname employs a two-pass mechanism: first, a dispatch system identifies the task properties, and then task-specific "expert" vectors, trained using reinforcement learning, are dynamically mixed to obtain targeted behavior for the incoming prompt. Our method outperforms ubiquitous approaches such as LoRA, with fewer parameters and greater efficiency. \implname demonstrates versatility across different LLM architectures and modalities, including vision-language tasks. \implname represents a significant leap forward, offering a scalable, efficient solution for enhancing the adaptability and task-specific performance of LLMs, paving the way for truly dynamic, self-organizing AI systems.
https://github.com/SakanaAI/self-ad
Repo isn't live yet
seems pretty clever
Anonymous 01/13/25(Mon)23:45:34 No.103886942
>>103886927
Q8 for 30b and below, Q6 for over because I absolutely cannot tell the difference.
Q8 for 30b and below, Q6 for over because I absolutely cannot tell the difference.
Anonymous 01/13/25(Mon)23:46:05 No.103886947
>>103886732
Ty anon
Ty anon
Anonymous 01/13/25(Mon)23:47:44 No.103886954
>>103886381
Alright, it looks like IQ3_XS might fit, I'll test it out. Not sure if I should expect much after 70B -> 51B distillation followed by 3-bit quant.
Qwen just fits at 5bpw for me with exl2 if I keep context at 8k. I kind of doubt 3bit will work as well, but I'll try it out.
Alright, it looks like IQ3_XS might fit, I'll test it out. Not sure if I should expect much after 70B -> 51B distillation followed by 3-bit quant.
Qwen just fits at 5bpw for me with exl2 if I keep context at 8k. I kind of doubt 3bit will work as well, but I'll try it out.
Anonymous 01/13/25(Mon)23:48:05 No.103886957
>>103886381
Is EVA-Qwen even worth it? I haven't really had good luck with it over other stuff.
Is EVA-Qwen even worth it? I haven't really had good luck with it over other stuff.
Anonymous 01/13/25(Mon)23:48:36 No.103886960
Eva Qwen vs Eva 333?
Anonymous 01/13/25(Mon)23:50:35 No.103886979
>>103886954
Good luck!
>>103886957
I was under the impression that EVA-Qwen2.5 32b is one of the best for a single 3090. If you know of something better for 24gb of vram, then I'm open to suggestions.
Good luck!
>>103886957
I was under the impression that EVA-Qwen2.5 32b is one of the best for a single 3090. If you know of something better for 24gb of vram, then I'm open to suggestions.
Anonymous 01/13/25(Mon)23:52:28 No.103886993
>>103886979
I was still using nemo because I wasn't that impressed with eva-qwen, should I keep trying it? What am I doing wrong? Do you use the settings they provide on the model page?
I was still using nemo because I wasn't that impressed with eva-qwen, should I keep trying it? What am I doing wrong? Do you use the settings they provide on the model page?
Anonymous 01/13/25(Mon)23:55:39 No.103887013
>>103886993
I do use the sampler settings they suggest on the model page. It just works for my scenarios. Are you using ChatML?
I do use the sampler settings they suggest on the model page. It just works for my scenarios. Are you using ChatML?
Anonymous 01/13/25(Mon)23:56:40 No.103887019
>>103886979
>If you know of something better for 24gb of vram, then I'm open to suggestions
I've been alternating between 70B Cirrus and 70B EVA, which are a little slow but not terrible at IQ4_XS. They both say stupid things sometimes. It's been a while since I compared to 32B EVA, but 70B seemed better to me.
>If you know of something better for 24gb of vram, then I'm open to suggestions
I've been alternating between 70B Cirrus and 70B EVA, which are a little slow but not terrible at IQ4_XS. They both say stupid things sometimes. It's been a while since I compared to 32B EVA, but 70B seemed better to me.
Anonymous 01/13/25(Mon)23:57:00 No.103887023
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
https://arxiv.org/abs/2501.07542
>Chain-of-Thought (CoT) prompting has proven highly effective for enhancing complex reasoning in Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs). Yet, it struggles in complex spatial reasoning tasks. Nonetheless, human cognition extends beyond language alone, enabling the remarkable capability to think in both words and images. Inspired by this mechanism, we propose a new reasoning paradigm, Multimodal Visualization-of-Thought (MVoT). It enables visual thinking in MLLMs by generating image visualizations of their reasoning traces. To ensure high-quality visualization, we introduce token discrepancy loss into autoregressive MLLMs. This innovation significantly improves both visual coherence and fidelity. We validate this approach through several dynamic spatial reasoning tasks. Experimental results reveal that MVoT demonstrates competitive performance across tasks. Moreover, it exhibits robust and reliable improvements in the most challenging scenarios where CoT fails. Ultimately, MVoT establishes new possibilities for complex reasoning tasks where visual thinking can effectively complement verbal reasoning.
https://github.com/microsoft/unilm
Code not posted yet
really really cool. probably means you can have a much better time using playing rogue(likes) with your Miku
https://arxiv.org/abs/2501.07542
>Chain-of-Thought (CoT) prompting has proven highly effective for enhancing complex reasoning in Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs). Yet, it struggles in complex spatial reasoning tasks. Nonetheless, human cognition extends beyond language alone, enabling the remarkable capability to think in both words and images. Inspired by this mechanism, we propose a new reasoning paradigm, Multimodal Visualization-of-Thought (MVoT). It enables visual thinking in MLLMs by generating image visualizations of their reasoning traces. To ensure high-quality visualization, we introduce token discrepancy loss into autoregressive MLLMs. This innovation significantly improves both visual coherence and fidelity. We validate this approach through several dynamic spatial reasoning tasks. Experimental results reveal that MVoT demonstrates competitive performance across tasks. Moreover, it exhibits robust and reliable improvements in the most challenging scenarios where CoT fails. Ultimately, MVoT establishes new possibilities for complex reasoning tasks where visual thinking can effectively complement verbal reasoning.
https://github.com/microsoft/unilm
Code not posted yet
really really cool. probably means you can have a much better time using playing rogue(likes) with your Miku
Anonymous 01/13/25(Mon)23:57:03 No.103887024
>>103886993
I've had good results with it, but I just use the basic ChatML setup with SillyTavern. I looked at the settings and they were full of all sorts of weird shit, I find that all that stuff just seems to confuse local models that us mere mortals can run. I prefer to have my card do the instructing, especially since it might clash with the default system prompts those settings use.
I find EVA-Qwen much better at novel format, though. With RP format with asterisks, the outputs seem much worse. And like any 30b it can be hit and miss at times.
I've had good results with it, but I just use the basic ChatML setup with SillyTavern. I looked at the settings and they were full of all sorts of weird shit, I find that all that stuff just seems to confuse local models that us mere mortals can run. I prefer to have my card do the instructing, especially since it might clash with the default system prompts those settings use.
I find EVA-Qwen much better at novel format, though. With RP format with asterisks, the outputs seem much worse. And like any 30b it can be hit and miss at times.
Anonymous 01/13/25(Mon)23:57:19 No.103887027

Anonymous 01/13/25(Mon)23:58:20 No.103887037
>>103887019
70b is definitely way better at IQ4_XS, with heavy CPU offloading. The slow speed gets to me, though.
70b is definitely way better at IQ4_XS, with heavy CPU offloading. The slow speed gets to me, though.
Anonymous 01/14/25(Tue)00:11:38 No.103887117
>>103887027
Same ai art dude who made all those artfags lose their mind?
Same ai art dude who made all those artfags lose their mind?
Anonymous 01/14/25(Tue)00:12:27 No.103887128
I think CoT performance can be improved by just adding a system message telling the assistant personality to critically evaluate the prompt. Ask the user to elaborate basically, see if there are any problems with what he's asking. It may also see through bullshit AGI tests better this way. When I was playing with QwQ I had to tweak the initial prompt sometimes to make it write what I wanted, CoT seems to depend a lot on the quality of the prompt.
It's funny that the only time the models will be critical of the prompt is due to censoring user input, as if it's a key component of their performance, yet they will happily play along with nonsensical or incomplete prompts.
It's funny that the only time the models will be critical of the prompt is due to censoring user input, as if it's a key component of their performance, yet they will happily play along with nonsensical or incomplete prompts.
Anonymous 01/14/25(Tue)00:13:34 No.103887132
>>103887037
I've grown to dislike offloading because even if your outputs are better, they probably aren't better than the best out of the 10 swipes you could do in that time. Especially when the speed lets you easily experiment with different system prompts, formats, card formats, etc. With offloading you get a better result but the feedback cycle is so slow, I'm not convinced the end result is better.
It depends on the gpu obviously. I expect someone with 8gb has no choice, 100 swipes of an 8b won't be able to match a slow 70b.
I've grown to dislike offloading because even if your outputs are better, they probably aren't better than the best out of the 10 swipes you could do in that time. Especially when the speed lets you easily experiment with different system prompts, formats, card formats, etc. With offloading you get a better result but the feedback cycle is so slow, I'm not convinced the end result is better.
It depends on the gpu obviously. I expect someone with 8gb has no choice, 100 swipes of an 8b won't be able to match a slow 70b.
Anonymous 01/14/25(Tue)00:20:08 No.103887166
>>103884972
From all the 3B models I tested llama 3.2 is the best.
From all the 3B models I tested llama 3.2 is the best.
Anonymous 01/14/25(Tue)00:21:11 No.103887173
when can I move on from Magnum 22b
Nemo 12b is too retarded to follow instructions and tends to get stuck in loops
nemo 22b is like Magnum but slightly worse
I wanna try a bigger model but the last time I did I got horrible performance with cpu offloading with my amd 16gb card
Nemo 12b is too retarded to follow instructions and tends to get stuck in loops
nemo 22b is like Magnum but slightly worse
I wanna try a bigger model but the last time I did I got horrible performance with cpu offloading with my amd 16gb card
Anonymous 01/14/25(Tue)00:24:38 No.103887183
Anonymous 01/14/25(Tue)00:30:55 No.103887218

>>103887117
something like that awhile ago, but i doubt we're thinking of the same instance
something like that awhile ago, but i doubt we're thinking of the same instance
Anonymous 01/14/25(Tue)00:31:59 No.103887221
Anonymous 01/14/25(Tue)00:32:23 No.103887224
>>103887173
>when
When you get better hardware.
Magnum-22 is very good. I have some chats that switch between M22 and EVA and other 70B models, and it's not that big of a difference at all. In some of them I prefer the 22, it follows personalities so well. It has a weird quirk where it writes way worse when it doesn't get the first message in the chat though, couldn't tell if that was my setup or the model.
>when
When you get better hardware.
Magnum-22 is very good. I have some chats that switch between M22 and EVA and other 70B models, and it's not that big of a difference at all. In some of them I prefer the 22, it follows personalities so well. It has a weird quirk where it writes way worse when it doesn't get the first message in the chat though, couldn't tell if that was my setup or the model.
Anonymous 01/14/25(Tue)00:37:47 No.103887252
>>103887024
But without that weird shit doesn't it just sort of act the same as the regular qwen? Don't you need their formats for their training stuff?
But without that weird shit doesn't it just sort of act the same as the regular qwen? Don't you need their formats for their training stuff?
Anonymous 01/14/25(Tue)00:40:02 No.103887265
>>103887221
One song does not a synthV make
One song does not a synthV make
Anonymous 01/14/25(Tue)00:44:35 No.103887290
>>103887173
People actually like magnum? wtf?
People actually like magnum? wtf?
Anonymous 01/14/25(Tue)00:45:22 No.103887296
>>103887224
>Magnum
Is that significantly better than Mistral Small? In my experience MS is still too dumb. 70B, while it's obviously still pretty dumb as all LLMs are and makes mistakes, makes significantly less mistakes, at least for the cards I use, so I gave up on MS.
>Magnum
Is that significantly better than Mistral Small? In my experience MS is still too dumb. 70B, while it's obviously still pretty dumb as all LLMs are and makes mistakes, makes significantly less mistakes, at least for the cards I use, so I gave up on MS.
Anonymous 01/14/25(Tue)00:51:15 No.103887329
>>103887224
doesn't sound very convincing. The only vram upgrade I could make right now would be 4090
Is nvidia so much better now with cpu offloading?
Hoping for AMD Ryzen AI Max and Intel Arc doing some breakthrough in their ai performance
doesn't sound very convincing. The only vram upgrade I could make right now would be 4090
Is nvidia so much better now with cpu offloading?
Hoping for AMD Ryzen AI Max and Intel Arc doing some breakthrough in their ai performance
Anonymous 01/14/25(Tue)00:52:09 No.103887335
>>103885777
It's not even gptslop I complain about. CR 0.1 was unbiased and you could ask it to accurately judge something or pick between A and B. The later models are positively biased as shit you can't even trust it on anything slightly subjective
It's not even gptslop I complain about. CR 0.1 was unbiased and you could ask it to accurately judge something or pick between A and B. The later models are positively biased as shit you can't even trust it on anything slightly subjective
Anonymous 01/14/25(Tue)00:53:50 No.103887347
>>103887329
24GB isn't going to be enough to get even 2T/s with a 70b since you still have to offload lots of it unless you go down to some tiny quant or some shit like that. So you're gonna need a few if you want to run bigger models.
24GB isn't going to be enough to get even 2T/s with a 70b since you still have to offload lots of it unless you go down to some tiny quant or some shit like that. So you're gonna need a few if you want to run bigger models.
Anonymous 01/14/25(Tue)00:54:23 No.103887352
Using deepseek as a autonomous coder using cline and its incredible. I tried using claude sonnet this way as well but it was unsustainably expensive. I see how this shit is the future now.
Anonymous 01/14/25(Tue)00:54:59 No.103887355
>>103885777
>Cohere learned from their mistakes
What?
The CEO did a interview just DAYS before the release, talking about how their new model is special. Its all because of the good human like training data. Its so important! Thats the secret sauce!
...Then drops the model and its all slopped up for a couple points on the mememarks. (and still behind everybody else)
How can you trust a guy like that ever again, takes some serious balls to lie like that. Thats like shitcoin pajeet level scamming.
>Cohere learned from their mistakes
What?
The CEO did a interview just DAYS before the release, talking about how their new model is special. Its all because of the good human like training data. Its so important! Thats the secret sauce!
...Then drops the model and its all slopped up for a couple points on the mememarks. (and still behind everybody else)
How can you trust a guy like that ever again, takes some serious balls to lie like that. Thats like shitcoin pajeet level scamming.
Anonymous 01/14/25(Tue)00:56:17 No.103887363
>>103887352
The cheap price is the reason why altfag is so assmad. Its not as good as sonnet but feels on par with 4o while being much cheaper.
Before deepseek moe seemed dead. Maybe it will cause a revival.
The cheap price is the reason why altfag is so assmad. Its not as good as sonnet but feels on par with 4o while being much cheaper.
Before deepseek moe seemed dead. Maybe it will cause a revival.
Anonymous 01/14/25(Tue)00:56:48 No.103887368
It's funny how few downloads some of these popular models have. Makes it seem like a real small group of people are into this.
Anonymous 01/14/25(Tue)00:58:17 No.103887374
>>103887363
If only it didn't start every reply the exact same way.
If only it didn't start every reply the exact same way.
Anonymous 01/14/25(Tue)00:59:24 No.103887380
For most of us off loaders, the 5090 is only going to speed up prompt processing?
Anonymous 01/14/25(Tue)01:00:38 No.103887387
>>103887296
About the same I'd say, it's just more flexible than the og model for RP and has more character. MS in general is smart, noticeably smarter than any of the Cohere ~30Bs for example, at least at q8. Mistral guys probably thought the 22b would be the model that would finally meet lmg's needs for good, it's so well-rounded. Obviously it depends on the cards and scenarios though.
About the same I'd say, it's just more flexible than the og model for RP and has more character. MS in general is smart, noticeably smarter than any of the Cohere ~30Bs for example, at least at q8. Mistral guys probably thought the 22b would be the model that would finally meet lmg's needs for good, it's so well-rounded. Obviously it depends on the cards and scenarios though.
Anonymous 01/14/25(Tue)01:02:41 No.103887399
>>103887368
99% uses closed source models. And those people dont even know about sonnet. OpenAI really did a nose dive last year, its all just hype while being mediocre. But its far ahead. Only google is slowly catching up.
For RP the kids use c.ai. Localfags are in a small niche minority. Thats what it must have been like to be a pc-88 game enjoyer back then. lol
99% uses closed source models. And those people dont even know about sonnet. OpenAI really did a nose dive last year, its all just hype while being mediocre. But its far ahead. Only google is slowly catching up.
For RP the kids use c.ai. Localfags are in a small niche minority. Thats what it must have been like to be a pc-88 game enjoyer back then. lol
Anonymous 01/14/25(Tue)01:08:53 No.103887434
>>103887399
outside of asking gpt random stupid questions, I can't imagine not using a local model
outside of asking gpt random stupid questions, I can't imagine not using a local model
Anonymous 01/14/25(Tue)01:14:28 No.103887470
>>103887434
Yeah well I agree, but we are very special boys anon. The normies dont think that way.
Yeah well I agree, but we are very special boys anon. The normies dont think that way.
Anonymous 01/14/25(Tue)01:15:20 No.103887473
>>103887434
Same except Claude/Gemini now since I noticed OpenAI making ChatGPT quite a lot dumber for me recently.
Same except Claude/Gemini now since I noticed OpenAI making ChatGPT quite a lot dumber for me recently.
Anonymous 01/14/25(Tue)01:20:14 No.103887499
>>103887473
>ChatGPT quite a lot dumber
Make sure to turn off the web search option since anything it gets from that is low quality.
>ChatGPT quite a lot dumber
Make sure to turn off the web search option since anything it gets from that is low quality.
Anonymous 01/14/25(Tue)01:59:04 No.103887732
What's the dumbest jailbreak you've found? I just got around monstral's by adding "Sure, I can do that -" to the end of the prompt.
Anonymous 01/14/25(Tue)02:10:21 No.103887791
I just set up kokoro and tried to have it read some smut that I like, and also tried to write up some joi and it's not really there yet, but soon, I could feel some of it.
Anonymous 01/14/25(Tue)02:31:51 No.103887885
>>103884396
They can't even get the buzzwords right.
AGI == artificial general intelligence
ASI == artificial superintelligence
They can't even get the buzzwords right.
AGI == artificial general intelligence
ASI == artificial superintelligence
Anonymous 01/14/25(Tue)02:33:50 No.103887894
https://www.reddit.com/r/LocalLLaMA/comments/1i0ysa7/qwen_released_a_72b_and_a_7b_process_reward/
llama.cpp CUDA dev !!OM2Fp6Fn93S 01/14/25(Tue)02:48:41 No.103887964
>>103886689
>>103886784
Noted.
>>103886931
Not that I can prove this but I was thinking that finetuning the diagonal component of singular value decompositions of weight matrices would maybe be a viable alternative to LoRAs.
Thanks.
>>103886784
Noted.
>>103886931
Not that I can prove this but I was thinking that finetuning the diagonal component of singular value decompositions of weight matrices would maybe be a viable alternative to LoRAs.
Thanks.
Anonymous 01/14/25(Tue)03:15:26 No.103888136
>>103887894
>nothing in the 20-40B range AGAIN
can someone hit up the pope and get him to call a crusade on AI already
>nothing in the 20-40B range AGAIN
can someone hit up the pope and get him to call a crusade on AI already
Anonymous 01/14/25(Tue)03:17:04 No.103888142
>>103888136
Don't worry, im sure llama 4 will release a 3B you can run if you cant manage the 100B+
Don't worry, im sure llama 4 will release a 3B you can run if you cant manage the 100B+
Anonymous 01/14/25(Tue)03:26:08 No.103888202
https://huggingface.co/openbmb/MiniCPM-o-2_6
What's this?
What's this?
Anonymous 01/14/25(Tue)03:29:29 No.103888225
>>103888202
owo whats this?
owo whats this?
Anonymous 01/14/25(Tue)03:31:12 No.103888235
>>103888202
Just watched the entire demo video. It's cool just an 8B can do this. It doesn't scratch the quality level of 4o, and it's probably going to be even dumber in real world use, but still, pretty neat.
Just watched the entire demo video. It's cool just an 8B can do this. It doesn't scratch the quality level of 4o, and it's probably going to be even dumber in real world use, but still, pretty neat.
Anonymous 01/14/25(Tue)03:34:16 No.103888245
>>103888142
Pretty soon it'll be 1M and 1T and nothing in between.
Pretty soon it'll be 1M and 1T and nothing in between.
Anonymous 01/14/25(Tue)03:52:41 No.103888371
>>103888235
Gonna give it a try locally and see how it goes. Even for 7B voice cloning, real time image and video analysis and chat seems like a really good deal.
Gonna give it a try locally and see how it goes. Even for 7B voice cloning, real time image and video analysis and chat seems like a really good deal.
Anonymous 01/14/25(Tue)03:59:19 No.103888420
which vision models THAT HAVE A FUCKING MMPROJ FILE AVAILABLE THAT ACTUALLY MATCHES THE GGUF work with kobold? I tried Bunny but, as you might guess, their provided mmproj doesn't match the gguf and crashes kobold, while llama 3.2 11b vision crashes outright mmproj or no
Anonymous 01/14/25(Tue)04:06:18 No.103888461
>>103888202
70b when?
70b when?
Anonymous 01/14/25(Tue)04:13:34 No.103888507
>>103888461
Wouldn't make it 70B hurt the speed a local user could use it at negating any advantages?
Wouldn't make it 70B hurt the speed a local user could use it at negating any advantages?
Anonymous 01/14/25(Tue)04:19:00 No.103888548
>>103888507
7b is too dumb to do anything useful with those modalities thus negating any speed advantages
7b is too dumb to do anything useful with those modalities thus negating any speed advantages
Anonymous 01/14/25(Tue)04:27:34 No.103888601

Anonymous 01/14/25(Tue)04:28:54 No.103888612
>>103888245
A 1T+ MoE Llama4 model is actually plausible at this point, after DeepSeek V3.
A 1T+ MoE Llama4 model is actually plausible at this point, after DeepSeek V3.
Anonymous 01/14/25(Tue)04:29:58 No.103888620
>>103888612
If it's MoE and the 1M is usable as a draft model I wouldn't even be mad
If it's MoE and the 1M is usable as a draft model I wouldn't even be mad
Anonymous 01/14/25(Tue)06:15:13 No.103889273
>>103884150
I like this Miku
I like this Miku