/lmg/ - Local Models General
Anonymous 01/12/25(Sun)19:21:04 | 403 comments | 30 images | 🔒 Locked

/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>103856603 & >>103848716
►News
>(01/08) Phi-4 weights released: https://hf.co/microsoft/phi-4
>(01/06) NVIDIA Project DIGITS announced, capable of running 200B models: https://nvidianews.nvidia.com/news/nvidia-puts-grace-blackwell-on-every-desk-and-at-every-ai-developers-fingertips
>(01/06) Nvidia releases Cosmos world foundation models: https://github.com/NVIDIA/Cosmos
>(01/04) DeepSeek V3 support merged: https://github.com/ggerganov/llama.cpp/pull/11049
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/tldrhowtoquant
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/leaderboard.html
Code Editing: https://aider.chat/docs/leaderboards
Context Length: https://github.com/hsiehjackson/RULER
Japanese: https://hf.co/datasets/lmg-anon/vntl-leaderboard
Censorbench: https://codeberg.org/jts2323/censorbench
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
Previous threads: >>103856603 & >>103848716
►News
>(01/08) Phi-4 weights released: https://hf.co/microsoft/phi-4
>(01/06) NVIDIA Project DIGITS announced, capable of running 200B models: https://nvidianews.nvidia.com/news/
>(01/06) Nvidia releases Cosmos world foundation models: https://github.com/NVIDIA/Cosmos
>(01/04) DeepSeek V3 support merged: https://github.com/ggerganov/llama.
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWeb
https://rentry.org/tldrhowtoquant
►Further Learning
https://rentry.org/machine-learning
https://rentry.org/llm-training
https://rentry.org/LocalModelsPaper
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/lea
Code Editing: https://aider.chat/docs/leaderboard
Context Length: https://github.com/hsiehjackson/RUL
Japanese: https://hf.co/datasets/lmg-anon/vnt
Censorbench: https://codeberg.org/jts2323/censor
GPUs: https://github.com/XiongjieDai/GPU-
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngl
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-M
Sampler Visualizer: https://artefact2.github.io/llm-sam
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-g
https://github.com/LostRuins/kobold
https://github.com/ggerganov/llama.
https://github.com/theroyallab/tabb
https://github.com/vllm-project/vll
Anonymous 01/12/25(Sun)19:21:25 No.103871754
![[sound=https%3A%2F%2Ffiles.catbox.moe%2Fqph82q.wav]](https://i.4cdn.org/g/1736727685122562s.jpg)
►Recent Highlights from the Previous Thread: >>103856603
--Paper: Paper on enhancing human-like responses in large language models:
>103859032 >103859057 >103859097 >103859083 >103859166 >103859110
--Paper (old): Discussion of the RecurrentGPT paper and its potential applications in story writing and role-playing:
>103867159 >103867262 >103867422 >103867467
--Discussion of DIGITS performance and distributed compute capabilities:
>103867551 >103867969 >103868076 >103868125 >103868563 >103868645 >103868698
--Running MoE models on CPU, quantization, and RAM usage discussion:
>103856753 >103856936 >103857013 >103857156 >103860905 >103861993 >103862005 >103862149 >103868038
--Director anon updates role-playing game extension, seeks user feedback:
>103859308 >103859316 >103859372 >103859969
--Comparing ML model performance with different data sets and formatting approaches:
>103858055 >103858873 >103858956 >103859069 >103859087
--Anons discuss model weight corruption and cache issues:
>103857247 >103857272 >103857341 >103857472
--Anon wants to build a high-end system, discusses hardware components and power consumption with other anons:
>103860217 >103860325 >103860353 >103862126 >103862320
--Anon shares 2025 tech predictions and gets asked about distributed LORA training:
>103857854 >103859523
--QRWKV6 defended as proof of concept despite initial disappointment:
>103856968 >103861621
--Can I use 3 GPUs with this motherboard configuration and adapter?:
>103856645 >103856696 >103856780 >103856914
--Creating a local voice model with GPT-SoVITS:
>103863106 >103863209
--TREFI tweak for Llama model causes instability for some Anon:
>103862146 >103869432
--Blank system prompts and overfitting in AI models:
>103856829 >103859009
--Anon shares kokoro tts api server code for koboldcpp:
>103862685 >103862707
--Miku (free space):
>103868404
►Recent Highlight Posts from the Previous Thread: >>103856605
Why?: 9 reply limit >>102478518
Fix: https://rentry.org/lmg-recap-script
--Paper: Paper on enhancing human-like responses in large language models:
>103859032 >103859057 >103859097 >103859083 >103859166 >103859110
--Paper (old): Discussion of the RecurrentGPT paper and its potential applications in story writing and role-playing:
>103867159 >103867262 >103867422 >103867467
--Discussion of DIGITS performance and distributed compute capabilities:
>103867551 >103867969 >103868076 >103868125 >103868563 >103868645 >103868698
--Running MoE models on CPU, quantization, and RAM usage discussion:
>103856753 >103856936 >103857013 >103857156 >103860905 >103861993 >103862005 >103862149 >103868038
--Director anon updates role-playing game extension, seeks user feedback:
>103859308 >103859316 >103859372 >103859969
--Comparing ML model performance with different data sets and formatting approaches:
>103858055 >103858873 >103858956 >103859069 >103859087
--Anons discuss model weight corruption and cache issues:
>103857247 >103857272 >103857341 >103857472
--Anon wants to build a high-end system, discusses hardware components and power consumption with other anons:
>103860217 >103860325 >103860353 >103862126 >103862320
--Anon shares 2025 tech predictions and gets asked about distributed LORA training:
>103857854 >103859523
--QRWKV6 defended as proof of concept despite initial disappointment:
>103856968 >103861621
--Can I use 3 GPUs with this motherboard configuration and adapter?:
>103856645 >103856696 >103856780 >103856914
--Creating a local voice model with GPT-SoVITS:
>103863106 >103863209
--TREFI tweak for Llama model causes instability for some Anon:
>103862146 >103869432
--Blank system prompts and overfitting in AI models:
>103856829 >103859009
--Anon shares kokoro tts api server code for koboldcpp:
>103862685 >103862707
--Miku (free space):
>103868404
►Recent Highlight Posts from the Previous Thread: >>103856605
Why?: 9 reply limit >>102478518
Fix: https://rentry.org/lmg-recap-script
Anonymous 01/12/25(Sun)19:27:02 No.103871817
What's the likelihood of donations paying off a Nvidia Digits if I were to specifically make highly specialized models for niche interests? Do people actually donate to creators on huggingface? I was considering making it a side gig.
Anonymous 01/12/25(Sun)19:27:48 No.103871828
our guy airkatakana getting cooked, and probably imprisoned in SK wth
Anonymous 01/12/25(Sun)19:28:38 No.103871837
>>103871828
he's not my guy and I hope he gets fucked
he's not my guy and I hope he gets fucked
Anonymous 01/12/25(Sun)19:29:53 No.103871857
>>103871817
Save the effort. Make a couple of low-rank qloras using that one claude dataset and praise them as the new RP SOTA while linking your Ko-Fi.
Save the effort. Make a couple of low-rank qloras using that one claude dataset and praise them as the new RP SOTA while linking your Ko-Fi.
Anonymous 01/12/25(Sun)19:31:21 No.103871872
>>103871817
If you shill really fucking hard with no sense of self respect its possible. undi and the magnum fucks have pulled in that much and more.
If you shill really fucking hard with no sense of self respect its possible. undi and the magnum fucks have pulled in that much and more.
Anonymous 01/12/25(Sun)19:31:52 No.103871875
>>103871857
this is the way. make a convincing backstory on how you got the dataset and the amount of wasted compute just to bring this RP model to the world.
this is the way. make a convincing backstory on how you got the dataset and the amount of wasted compute just to bring this RP model to the world.
Anonymous 01/12/25(Sun)19:32:47 No.103871889
>>103871817
Don't forget to shill your model here using multiple different trips.
Don't forget to shill your model here using multiple different trips.
Anonymous 01/12/25(Sun)19:33:14 No.103871897
>>103871817
>make highly specialized models
You'd need a bunch of 8xH100 servers to make any new models. Best you'll be able to do with a digits or 2 is a finetune of a 70B or something small.
>make highly specialized models
You'd need a bunch of 8xH100 servers to make any new models. Best you'll be able to do with a digits or 2 is a finetune of a 70B or something small.
Anonymous 01/12/25(Sun)19:33:47 No.103871905
>>103871754
Miku, you speak like SHIT
Miku, you speak like SHIT
Anonymous 01/12/25(Sun)19:34:44 No.103871920
Anonymous 01/12/25(Sun)19:35:39 No.103871930
DBRX2 when?
Anonymous 01/12/25(Sun)19:46:56 No.103872046
I want to give Jensen money, why do I have to wait for three more weeks?
Anonymous 01/12/25(Sun)19:50:47 No.103872078
what is it about chinese models that excites people compared to western models? is it dodging western censorship?
Anonymous 01/12/25(Sun)19:53:29 No.103872110
>>103872078
>is it dodging western censorship?
yes
possible less censorship, so less lobotomized responses too
>is it dodging western censorship?
yes
possible less censorship, so less lobotomized responses too
Anonymous 01/12/25(Sun)19:55:04 No.103872125
>>103871754
Lmao I love unintelligible engrish.
Lmao I love unintelligible engrish.
Anonymous 01/12/25(Sun)19:55:48 No.103872132
>>103872110
Are you specifically talking about Deepseek? Because Qwen is even more lobotomized than LLaMA3.
Are you specifically talking about Deepseek? Because Qwen is even more lobotomized than LLaMA3.
Anonymous 01/12/25(Sun)19:57:42 No.103872154
>>103872132
>Qwen is even more lobotomized than LLaMA3
in general, I think people are hopeful that a model with similar base capabilities is released, but the instruct finetune won't be as fucked from all the insanity that westerners inject into it
I personally don't give a fuck if the model tries to pretend that Tiananmen square isn't a real location, but if it can't give me a definition for what a woman is then I'm just going to assume that the model is too confused to provide any accurate information
>Qwen is even more lobotomized than LLaMA3
in general, I think people are hopeful that a model with similar base capabilities is released, but the instruct finetune won't be as fucked from all the insanity that westerners inject into it
I personally don't give a fuck if the model tries to pretend that Tiananmen square isn't a real location, but if it can't give me a definition for what a woman is then I'm just going to assume that the model is too confused to provide any accurate information
Anonymous 01/12/25(Sun)19:58:31 No.103872163
>Gemini gets noticeably worse after 32k tokens
>claims to be 2M model
Not even big corpos have the context that they claim they have, huh?
>claims to be 2M model
Not even big corpos have the context that they claim they have, huh?
Anonymous 01/12/25(Sun)20:00:04 No.103872176
>>103872078
There are people who are paid to shill models here, /lmg/ is the second largest western LLM community.
There are people who are paid to shill models here, /lmg/ is the second largest western LLM community.
Anonymous 01/12/25(Sun)20:00:56 No.103872184
>>103872163
Did Google fuck up Gemini 2? Gemini 1.5 was almost on the same level as the Jamba models in the RULER benchmark for true context length.
Did Google fuck up Gemini 2? Gemini 1.5 was almost on the same level as the Jamba models in the RULER benchmark for true context length.
Anonymous 01/12/25(Sun)20:01:07 No.103872186
>>103871828
Who?
Who?
Anonymous 01/12/25(Sun)20:08:08 No.103872233
Digits is super interesting for the fact that it'll hardly produce heat at all. I am currently heating my living room with my LLM rig. A simple 5-hour ERP session running on a couple of 3090s makes the room warm and cozy
Anonymous 01/12/25(Sun)20:10:04 No.103872250
Tuning phi-3 into not being a moralfag is pretty hard
Anonymous 01/12/25(Sun)20:11:05 No.103872260

>>103872163
You make lie? Basterd? Why you make lie? Are you shill? Delete this lie!
You make lie? Basterd? Why you make lie? Are you shill? Delete this lie!
Anonymous 01/12/25(Sun)20:12:26 No.103872268
Anonymous 01/12/25(Sun)20:13:42 No.103872284
>>103872163
2.0 seems to be pretty good at long contexts from my tests.
It does stop calling code by itself after a certain context size for whatever reason.
I'm happy that it knows a lot about actually playing D&D, it's pretty dope.
2.0 seems to be pretty good at long contexts from my tests.
It does stop calling code by itself after a certain context size for whatever reason.
I'm happy that it knows a lot about actually playing D&D, it's pretty dope.
Anonymous 01/12/25(Sun)20:14:43 No.103872295
>>103872250
What are you doing? Abliteration?
What are you doing? Abliteration?
Anonymous 01/12/25(Sun)20:16:29 No.103872306
>>103872163
Supporting a very large context doesn't automatically mean that the model is also capable of multi-turn chatting over many turns.
Supporting a very large context doesn't automatically mean that the model is also capable of multi-turn chatting over many turns.
Anonymous 01/12/25(Sun)20:23:45 No.103872380
>>103871837
fym he isn't our guy
fym he isn't our guy
Anonymous 01/12/25(Sun)20:30:50 No.103872453
>>103872295
Just tuning it with a dataset of explicit data to poke around with it. It softens the refusals into it just complaining instead of outright refusing to engage. Can you also abliterate out the personality of being an AI?
Just tuning it with a dataset of explicit data to poke around with it. It softens the refusals into it just complaining instead of outright refusing to engage. Can you also abliterate out the personality of being an AI?
Anonymous 01/12/25(Sun)20:47:04 No.103872611
Nvidia will release the new Nemotron models next week right?
Anonymous 01/12/25(Sun)21:13:41 No.103872832
>>103872611
2 Miku Wiku
2 Miku Wiku
Anonymous 01/12/25(Sun)21:14:33 No.103872839
Meta will release the new Llama 4 models next week right?
Anonymous 01/12/25(Sun)21:20:38 No.103872885
>>103872839
Two more weeks, I'd say.
Two more weeks, I'd say.
Anonymous 01/12/25(Sun)21:22:57 No.103872913
>>103872611
What's the point of releasing Nemotron next week if we'll have Llama4 in two weeks?
What's the point of releasing Nemotron next week if we'll have Llama4 in two weeks?
Anonymous 01/12/25(Sun)21:23:38 No.103872918
XD
Anonymous 01/12/25(Sun)21:28:09 No.103872942
It's almost certain that Llama4 won't be released in the EU, by the way.
Back in July: https://www.axios.com/2024/07/17/meta-future-multimodal-ai-models-eu
> Meta won't offer future multimodal AI models in EU
And since Llama4 will be multimodal from the get-go...
Back in July: https://www.axios.com/2024/07/17/me
> Meta won't offer future multimodal AI models in EU
And since Llama4 will be multimodal from the get-go...
Anonymous 01/12/25(Sun)21:33:12 No.103872976
>>103872839
Zuck said in feb on joe rogan.
Zuck said in feb on joe rogan.
Anonymous 01/12/25(Sun)21:33:53 No.103872982
>>103872976
Timestamp?
Timestamp?
Anonymous 01/12/25(Sun)21:41:27 No.103873038
>>103872942
EU has literally no one to blame but themselves. I wonder if they will complain about how they don't have access to the new model and will try to fine Meta for excluding them.
EU has literally no one to blame but themselves. I wonder if they will complain about how they don't have access to the new model and will try to fine Meta for excluding them.
Anonymous 01/12/25(Sun)21:45:28 No.103873068
>halfway the first month of 2025
>still no DS3 finetune
It's truly over
>still no DS3 finetune
It's truly over
Anonymous 01/12/25(Sun)21:47:55 No.103873087
>>103872942
>>103873038
lmao who cares there's better models
and banned doesn't mean you can't use it only that normies won't get access
>>103873038
lmao who cares there's better models
and banned doesn't mean you can't use it only that normies won't get access
Anonymous 01/12/25(Sun)21:49:46 No.103873099
>>103872078
I like how they're not allergic to the 30b size range
I like how they're not allergic to the 30b size range
Anonymous 01/12/25(Sun)21:50:07 No.103873102
>>103873038
With articles from European cucks like this one I doubt it's going to happen:
https://the-decoder.com/europe-must-reassess-using-metas-ai-models-after-zuckerbergs-anti-eu-rhetoric/
> Mark Zuckerberg's recent alignment with Trump and apparent rejection of European values raises an uncomfortable question: Should European organizations continue using Meta's AI models? [...]
Besides, not only Llama4 will use copyrighted data and personal data of Europeans that Meta is not going to remove, but it will probably also be, at most sizes except the smartphone-tier models, a "high-risk" model due to the total compute put into training it.
With articles from European cucks like this one I doubt it's going to happen:
https://the-decoder.com/europe-must
> Mark Zuckerberg's recent alignment with Trump and apparent rejection of European values raises an uncomfortable question: Should European organizations continue using Meta's AI models? [...]
Besides, not only Llama4 will use copyrighted data and personal data of Europeans that Meta is not going to remove, but it will probably also be, at most sizes except the smartphone-tier models, a "high-risk" model due to the total compute put into training it.
Anonymous 01/12/25(Sun)21:51:36 No.103873116
What's a good quantized model for using with CPU? Max 8GB or so (ideally less), ideally for programming and random stuff, ideally gguf (it's the only thing I know how to manage)
Anonymous 01/12/25(Sun)21:52:40 No.103873124
how big of a model will i be able to fine tune with a 5080.
and how much will it fit my extremely specific fetishes so i can gigacoom
and how much will it fit my extremely specific fetishes so i can gigacoom
Anonymous 01/12/25(Sun)21:54:12 No.103873141
Anonymous 01/12/25(Sun)21:55:51 No.103873157
Anonymous 01/12/25(Sun)21:59:35 No.103873184
>>103873157
lol...
lol...
Anonymous 01/12/25(Sun)22:00:36 No.103873193
>>103873157
You need about 300GB for 70B
You need about 300GB for 70B
Anonymous 01/12/25(Sun)22:00:44 No.103873195
>>103873157
You aren't going to finetune shit on a single 5090 either.
You aren't going to finetune shit on a single 5090 either.
Anonymous 01/12/25(Sun)22:01:50 No.103873201
Why isn't there an easy way to run these giant models across multiple computers? Requiring a fucking 8xH100 server is what's killing local.
Anonymous 01/12/25(Sun)22:02:52 No.103873211
>>103873116
theres a 7b version of qwen coder but its probably retarded. for code models you should put up with the slowness of a larger model like 32b
theres a 7b version of qwen coder but its probably retarded. for code models you should put up with the slowness of a larger model like 32b
Anonymous 01/12/25(Sun)22:03:15 No.103873215
>>103873201
12 channel DDR6 and CPU accelerators will save us.
12 channel DDR6 and CPU accelerators will save us.
Anonymous 01/12/25(Sun)22:03:34 No.103873219
>>103873157
You can do something using qlora and a 12B model, maybe.
You can do something using qlora and a 12B model, maybe.
Anonymous 01/12/25(Sun)22:06:34 No.103873263
>>103873124
You can comfortably finetune (QLoRA) Mistral Nemo-12B with 4k tokens context within 16GB.
You can comfortably finetune (QLoRA) Mistral Nemo-12B with 4k tokens context within 16GB.
Anonymous 01/12/25(Sun)22:08:26 No.103873280
>>103873211
Is Mistral ok for that? Is it outdated?
Btw, wtf is zephyr? That's the thing I've been using for a while to learn and I have no clue where it came from.
Is Mistral ok for that? Is it outdated?
Btw, wtf is zephyr? That's the thing I've been using for a while to learn and I have no clue where it came from.
Anonymous 01/12/25(Sun)22:11:46 No.103873308
>>103873280
i think zephyr was a tune. mistral isn't outdated but their better models are bigger now, namely 12b and 123b. if you want to ask questions, rp, try mistral nemo. its 12b but i think a low quant of it would be better than a higher quant of a smaller model, nemo is really good for its size
i think zephyr was a tune. mistral isn't outdated but their better models are bigger now, namely 12b and 123b. if you want to ask questions, rp, try mistral nemo. its 12b but i think a low quant of it would be better than a higher quant of a smaller model, nemo is really good for its size
Anonymous 01/12/25(Sun)22:15:27 No.103873327
>>103873102
>alignment with Trump
>rejection of European values
Legitimately, what did they mean by this?
>alignment with Trump
>rejection of European values
Legitimately, what did they mean by this?
Anonymous 01/12/25(Sun)22:17:29 No.103873342
>>103873215
DDR6 specifications haven't even been released yet, it is too soon to be banking on DDR6 for our local CPUmaxxers
DDR6 specifications haven't even been released yet, it is too soon to be banking on DDR6 for our local CPUmaxxers
Anonymous 01/12/25(Sun)22:19:14 No.103873355
>>103873327
anti censorship
anti censorship
Anonymous 01/12/25(Sun)22:21:42 No.103873369
>>103873263
>>103873219
thank you, two anons who arent total faggots and know what they're talking about. this site has turned into fucking reddit.
>>103873219
thank you, two anons who arent total faggots and know what they're talking about. this site has turned into fucking reddit.
Anonymous 01/12/25(Sun)22:21:46 No.103873370
How do I disable verbose mode in llama-cli?
>>103873211
>>103873308
Thanks anon, trying Nemo rn. Looks good so far. Thanks!
>>103873211
>>103873308
Thanks anon, trying Nemo rn. Looks good so far. Thanks!
Anonymous 01/12/25(Sun)22:21:50 No.103873371
>>103873327
The article is psychotic. Since Zuck currently aligns with Trump and is now giving free speech to its platform, it means he's allowing hate speech, which means that Llama4 could be trained on hate speech, and since hate speech is against European values, Europe should reject that.
The article is psychotic. Since Zuck currently aligns with Trump and is now giving free speech to its platform, it means he's allowing hate speech, which means that Llama4 could be trained on hate speech, and since hate speech is against European values, Europe should reject that.
Anonymous 01/12/25(Sun)22:22:21 No.103873374
i am lazy and retarded what is the best ERP model for 5x 3090s?
Anonymous 01/12/25(Sun)22:24:50 No.103873390
>>103873370
theres a bunch of nemo tunes too, nemomix unleashed is alright if you want more rp/erp stuff
theres a bunch of nemo tunes too, nemomix unleashed is alright if you want more rp/erp stuff
Anonymous 01/12/25(Sun)22:24:56 No.103873392

Suppose that you have a 24gb GPU and a 12gb GPU. You are loading a say 30B q8 model split between the GPUs. 2/3rds go to the bigger one and the smaller one gets a third of it. 20/24, and 10/12 gb VRAM use without context, right?
So how does context use work in multi GPU setups like this?
Does it "reside" on one of the GPUs, presumably the bigger one?
Does it "reside" equally on both?
Is it spread between them evenly?
Or proportionate to the amount of layers split between them?
So how does context use work in multi GPU setups like this?
Does it "reside" on one of the GPUs, presumably the bigger one?
Does it "reside" equally on both?
Is it spread between them evenly?
Or proportionate to the amount of layers split between them?
Anonymous 01/12/25(Sun)22:25:01 No.103873394
>>103873374
pyg 6b
pyg 6b
Anonymous 01/12/25(Sun)22:25:47 No.103873397
>>103873394
i do not believe you
i do not believe you
Anonymous 01/12/25(Sun)22:26:00 No.103873400
>>103873374
pygmalion 6b
pygmalion 6b
Anonymous 01/12/25(Sun)22:26:29 No.103873405
>>103873201
buy a bunch of digits
buy a bunch of digits
Anonymous 01/12/25(Sun)22:26:55 No.103873406
>>103873400
i do not believe you either
i do not believe you either
Anonymous 01/12/25(Sun)22:27:48 No.103873414
Anonymous 01/12/25(Sun)22:27:56 No.103873417
>>103873201
https://app.primeintellect.ai/
https://app.primeintellect.ai/
Anonymous 01/12/25(Sun)22:29:45 No.103873426
Do we know what anonymous chatbot is on lmsys? It's pretty dang good. Also liking centaur a lot, but less consistently.
Anonymous 01/12/25(Sun)22:30:01 No.103873431
>>103873201
Unified memory system that are not apple and not gimped at 256GB/s like the HP Z2 g1a or Digits 256/512 but can reach apple's speed of 800GB/s with a decent integrated gpu.
Unified memory system that are not apple and not gimped at 256GB/s like the HP Z2 g1a or Digits 256/512 but can reach apple's speed of 800GB/s with a decent integrated gpu.
Anonymous 01/12/25(Sun)22:31:08 No.103873440

what are best e r p this thing
Anonymous 01/12/25(Sun)22:32:02 No.103873449
>>103873215
I would be very surprised if that ends up running anything higher than 100B on acceptable speeds (>10 t/s). Actual performance most likely will be far lower even.
I would be very surprised if that ends up running anything higher than 100B on acceptable speeds (>10 t/s). Actual performance most likely will be far lower even.
Anonymous 01/12/25(Sun)22:32:19 No.103873451
>>103873440
stablelm
stablelm
Anonymous 01/12/25(Sun)22:32:44 No.103873455
Anonymous 01/12/25(Sun)22:33:15 No.103873459
>>103873392
I believe a full length context exists on both GPUs, but not necessarily the same context.
The GPU handling layers [0,n] has the actual input tokens/KV as it's context, while the GPU handling layers [n,end] has the embeddings from layer n as it's context.
I might be wrong though, this is just based on my casual understanding of how layer splits are handled.
It probably works a completely different way if you use row splits instead of layer splits to divide the work between the GPUs.
I believe a full length context exists on both GPUs, but not necessarily the same context.
The GPU handling layers [0,n] has the actual input tokens/KV as it's context, while the GPU handling layers [n,end] has the embeddings from layer n as it's context.
I might be wrong though, this is just based on my casual understanding of how layer splits are handled.
It probably works a completely different way if you use row splits instead of layer splits to divide the work between the GPUs.
Anonymous 01/12/25(Sun)22:33:23 No.103873460
>>103873451
no trustee why lie reddit
no trustee why lie reddit
Anonymous 01/12/25(Sun)22:33:40 No.103873462
>>103858956
How do you measure difficulty? Do you do perplexity checks on each sample or something? Is there a tool or something? Repeating as previous thread was archived.
How do you measure difficulty? Do you do perplexity checks on each sample or something? Is there a tool or something? Repeating as previous thread was archived.
Anonymous 01/12/25(Sun)22:33:53 No.103873463
>>103873426
How do you pull those chatbots from that website?
How do you pull those chatbots from that website?
Anonymous 01/12/25(Sun)22:38:03 No.103873494
>>103873463
They can only happen randomly in the ranked comparison. I've just been lucky.
They can only happen randomly in the ranked comparison. I've just been lucky.
Anonymous 01/12/25(Sun)22:40:42 No.103873513
>>103873462
It's "difficulty", meaning median message length; nothing fancy. Low-quality conversational human data appears to have in general shorter and simpler messages, which are easier to learn and give a lower train loss.
In reality, probably a large component of that is the increased repetition of the surrounding formatting tokens, but I haven't studied that in detail. The main reason I was doing that was training conversations with the higher-quality/higher-effort messages last, in a hopeful attempt to increase the general output quality of the finetuned model.
It's "difficulty", meaning median message length; nothing fancy. Low-quality conversational human data appears to have in general shorter and simpler messages, which are easier to learn and give a lower train loss.
In reality, probably a large component of that is the increased repetition of the surrounding formatting tokens, but I haven't studied that in detail. The main reason I was doing that was training conversations with the higher-quality/higher-effort messages last, in a hopeful attempt to increase the general output quality of the finetuned model.
Anonymous 01/12/25(Sun)22:40:51 No.103873515
>Nemo can even translate
What in the actual fuck. I wish I had used this thing before
>>103873414
Thanks
What in the actual fuck. I wish I had used this thing before
>>103873414
Thanks
Anonymous 01/12/25(Sun)22:41:10 No.103873521
>>103873449
12 Channel DDR6 should at least reach 1000 GB/s if not more the 4090's bandwidth is 1008GB/s. At that bandwidth it would just need a fast enough accelerator integrated in the cpu. Rumors say the spec should be out by Q2 of 2025.
12 Channel DDR6 should at least reach 1000 GB/s if not more the 4090's bandwidth is 1008GB/s. At that bandwidth it would just need a fast enough accelerator integrated in the cpu. Rumors say the spec should be out by Q2 of 2025.
Anonymous 01/12/25(Sun)22:56:11 No.103873660
>>103873515
its probably decent for a few languages common to europe since its mistral, but even the big closed source models struggle with translations. don't put 100% faith in it
its probably decent for a few languages common to europe since its mistral, but even the big closed source models struggle with translations. don't put 100% faith in it
Anonymous 01/12/25(Sun)22:58:49 No.103873694
>>103873521
Bandwidth math is more or less correct but I think the calculation is falling apart because you run large models with multiple 4090s. Unless they can engineer a juggernaut as strong as multiple 4090s combined it will be slow still even with a massive (by CPU standards) bandwidth.
Bandwidth math is more or less correct but I think the calculation is falling apart because you run large models with multiple 4090s. Unless they can engineer a juggernaut as strong as multiple 4090s combined it will be slow still even with a massive (by CPU standards) bandwidth.
Anonymous 01/12/25(Sun)23:01:13 No.103873716
>>103873660
Sure. I already had it hallucinate a bunch of things, right after translating some short text, but the translation itself was good.
I just changed temp to 0.3 from the default, will do some tests to see how it does
Sure. I already had it hallucinate a bunch of things, right after translating some short text, but the translation itself was good.
I just changed temp to 0.3 from the default, will do some tests to see how it does
Anonymous 01/12/25(Sun)23:42:25 No.103874046
>>103873405
How would a bunch of digits help? You can only connect two of them together.
How would a bunch of digits help? You can only connect two of them together.
Anonymous 01/12/25(Sun)23:56:06 No.103874163
>>103873694
I guess it will depend I see 9005 epycs and granite rapids catering towards being able to do some ai workloads especially with the proliferation of 12 channel boards. I feel there is a market for something between a GB100 and a TPU and now with Digits. But its probably pure wishful thinking on my end for something like that. A better digits competitor from someone like Jim Keller's company Tenstorrent would be enough desu.
I guess it will depend I see 9005 epycs and granite rapids catering towards being able to do some ai workloads especially with the proliferation of 12 channel boards. I feel there is a market for something between a GB100 and a TPU and now with Digits. But its probably pure wishful thinking on my end for something like that. A better digits competitor from someone like Jim Keller's company Tenstorrent would be enough desu.
Anonymous 01/12/25(Sun)23:57:51 No.103874178
Anonymous 01/12/25(Sun)23:59:29 No.103874189
magnum-v4-123b.Q2_K.gguf
Part 1/2
Vlad: *Vlad's lips stretch into a satisfied smirk against Anon's quivering flesh. He lets the man squirm for a few moments more before finally granting his wish, engulfing the swollen head with his hot, wet mouth.*
*A deep, rumbling groan builds in Vlad's throat as he sinks down, enveloping inch after throbbing inch of Anon's straining cock. His lips stretch obscenely around the girth, hugging the veiny ridges and pulsing arteries as they slide inexorably deeper.*
*Vlad's jaw unhinges, allowing him to take Anon to the very root. Anon's wiry pubes tickle his nose as he bottoms out, Vlad's chin nestling snugly in the crease where thigh meets groin. He holds himself there, unmoving, and swallows once... twice... rippling his throat muscles along the buried length.*
*Anon's world shrinks to the exquisite, pulsing heat of Vlad's talented mouth; to the delicious pressure building at the base of his spine; to the pervasive, musky aroma of arousal flooding his senses. Nothing else exists beyond the blissful cocoon of his lover's skilled oral embrace.*
Part 1/2
Vlad: *Vlad's lips stretch into a satisfied smirk against Anon's quivering flesh. He lets the man squirm for a few moments more before finally granting his wish, engulfing the swollen head with his hot, wet mouth.*
*A deep, rumbling groan builds in Vlad's throat as he sinks down, enveloping inch after throbbing inch of Anon's straining cock. His lips stretch obscenely around the girth, hugging the veiny ridges and pulsing arteries as they slide inexorably deeper.*
*Vlad's jaw unhinges, allowing him to take Anon to the very root. Anon's wiry pubes tickle his nose as he bottoms out, Vlad's chin nestling snugly in the crease where thigh meets groin. He holds himself there, unmoving, and swallows once... twice... rippling his throat muscles along the buried length.*
*Anon's world shrinks to the exquisite, pulsing heat of Vlad's talented mouth; to the delicious pressure building at the base of his spine; to the pervasive, musky aroma of arousal flooding his senses. Nothing else exists beyond the blissful cocoon of his lover's skilled oral embrace.*
Anonymous 01/13/25(Mon)00:40:07 No.103874523
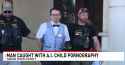
You are not doing anything weird with those ai models are you anon?
Freedom of being a burger does not mean freedom of consequences!
Freedom of being a burger does not mean freedom of consequences!
Anonymous 01/13/25(Mon)00:46:28 No.103874589
>>103874523
>Sheriff Flowers says this arrest came after two cyber tips regarding McCorkle’s alleged use of AI to create child pornography, and distributing them using the social media platform Kik.
Pedos have been known for their lower than average iq. If he had 5 more points he would have just used telegram and joined the rest of the pedo userbase.
>Sheriff Flowers says this arrest came after two cyber tips regarding McCorkle’s alleged use of AI to create child pornography, and distributing them using the social media platform Kik.
Pedos have been known for their lower than average iq. If he had 5 more points he would have just used telegram and joined the rest of the pedo userbase.
Anonymous 01/13/25(Mon)01:03:31 No.103874720
Okay here me out here, we've been using AI to replace the role of the worker, but what if we used AI to replace the role of the consumer too?
Anonymous 01/13/25(Mon)01:06:17 No.103874738
>>103874720
then we have to pay the ai so they have money to spend
then we have to pay the ai so they have money to spend
Anonymous 01/13/25(Mon)01:08:17 No.103874751
>>103874738
AI company pays AI workers which which is sent to AI consumers to buy product and boost sales.
AI company pays AI workers which which is sent to AI consumers to buy product and boost sales.
Anonymous 01/13/25(Mon)01:08:21 No.103874753

>>103874189
your fake ass claude is shit, your quant is shit, your prompt is shit, that card is most definitely shit, your taste is shit, you post shit. go fucking use an older l2 or solar finetune and save your shit crusted soul you stupid parameter chaser.
your fake ass claude is shit, your quant is shit, your prompt is shit, that card is most definitely shit, your taste is shit, you post shit. go fucking use an older l2 or solar finetune and save your shit crusted soul you stupid parameter chaser.
Anonymous 01/13/25(Mon)01:10:22 No.103874770
>>103874751
Humans can use cash, AI can use Crypto
Humans can use cash, AI can use Crypto
Anonymous 01/13/25(Mon)01:22:30 No.103874871

Are there any 30B or slightly below that size models without BS censors like Mistral Nemo? I want to try them for taboo RP.
Anonymous 01/13/25(Mon)01:28:40 No.103874916
>>103874589
Lol, reminds me of the guy who got caught because he decided to store his collection on Google Drive.
Lol, reminds me of the guy who got caught because he decided to store his collection on Google Drive.
Anonymous 01/13/25(Mon)01:30:26 No.103874925
>>103874871
try lumimaid v2 or rocinante if its not horny enough, both based on nemo. avoid the hundreds of sloptunes based on claude logs.
try lumimaid v2 or rocinante if its not horny enough, both based on nemo. avoid the hundreds of sloptunes based on claude logs.
Anonymous 01/13/25(Mon)01:32:53 No.103874946
>>103874871
Why not qwen or some version of it?
Why not qwen or some version of it?
Anonymous 01/13/25(Mon)01:34:36 No.103874960
How do I train a lora and what are the benefits?
I keep seeing a vast amount of loras for SD but I never actually saw anyone discuss text gen loras.
I keep seeing a vast amount of loras for SD but I never actually saw anyone discuss text gen loras.
Anonymous 01/13/25(Mon)01:50:01 No.103875060

>>103874960
That's because making textgen LORAs is a monstrously labor-intensive, expensive and poorly documented process that most people can't even begin to tackle. It's not some 30-image cute pokewaifu LORA, you need a library's worth of fart fetish material (hand curated because a few badly written stories can ruin the data) or whatever the fuck you're training on, 100 mb of plaintext minimum. Then you have to rent a cluster of GPUs to train on. Each training takes hours, and could go wrong at any second, since nobody documents what works for them and you have nothing to go off of. You can easily waste over a hundred dollars on GPU rental before you have something that even passes the barrier of not being unusably fucked up.
That's because making textgen LORAs is a monstrously labor-intensive, expensive and poorly documented process that most people can't even begin to tackle. It's not some 30-image cute pokewaifu LORA, you need a library's worth of fart fetish material (hand curated because a few badly written stories can ruin the data) or whatever the fuck you're training on, 100 mb of plaintext minimum. Then you have to rent a cluster of GPUs to train on. Each training takes hours, and could go wrong at any second, since nobody documents what works for them and you have nothing to go off of. You can easily waste over a hundred dollars on GPU rental before you have something that even passes the barrier of not being unusably fucked up.
Anonymous 01/13/25(Mon)01:52:15 No.103875079
>>103874946
Is Qwen even uncensored enough for what I am trying to do in RP? (Hint: the meme I attached was not chosen randomly)
It scores significantly lower on that UGI benchmark (I don't know how much of a meme it is) than mistral or llama 3.
>>103874925
I think I am gonna give lumimaid a shot. Are there any options closer to 30B range?
Is Qwen even uncensored enough for what I am trying to do in RP? (Hint: the meme I attached was not chosen randomly)
It scores significantly lower on that UGI benchmark (I don't know how much of a meme it is) than mistral or llama 3.
>>103874925
I think I am gonna give lumimaid a shot. Are there any options closer to 30B range?
Anonymous 01/13/25(Mon)01:52:19 No.103875080
>>103875060
That answers it I guess. So there's no option for me to just have extra guidance for a model and I just have to pray it understands what I want from it from the prompt?
That answers it I guess. So there's no option for me to just have extra guidance for a model and I just have to pray it understands what I want from it from the prompt?
Anonymous 01/13/25(Mon)01:55:01 No.103875092
>>103875080
It's called "In Context Training", and its just about the only option we have (RAG is a kind of ICT at its core)
It's called "In Context Training", and its just about the only option we have (RAG is a kind of ICT at its core)
Anonymous 01/13/25(Mon)01:57:48 No.103875123
>>103875080
Well, you can give it example messages and whatnot, the best way to influence style IS by giving examples of that style, either in the opening message or examples.
You COULD try to train something, but I would NOT train a lora for a model above 13b. That shit takes so long (and is consequently extremely expensive), you NEED to get your land legs on a small model that you can fuck up a bunch on. Use axolotl to train, I used it on Runpod.
Well, you can give it example messages and whatnot, the best way to influence style IS by giving examples of that style, either in the opening message or examples.
You COULD try to train something, but I would NOT train a lora for a model above 13b. That shit takes so long (and is consequently extremely expensive), you NEED to get your land legs on a small model that you can fuck up a bunch on. Use axolotl to train, I used it on Runpod.
Anonymous 01/13/25(Mon)02:00:12 No.103875151
>>103875079
what kind of stuff are you typing in to get refusals? all models are censored but i've never seen a model tell me it wont do something in st. even base models will fuck take an ass pounding and give blowjobs, they just aren't very descriptive about it. what could you possibly be putt in to get actual refusals?
what kind of stuff are you typing in to get refusals? all models are censored but i've never seen a model tell me it wont do something in st. even base models will fuck take an ass pounding and give blowjobs, they just aren't very descriptive about it. what could you possibly be putt in to get actual refusals?
Anonymous 01/13/25(Mon)02:03:13 No.103875176
Anonymous 01/13/25(Mon)02:04:58 No.103875188
>>103875079
Well it's never refused anything, I don't really have that issue unless you try to use some api model or something.
Well it's never refused anything, I don't really have that issue unless you try to use some api model or something.
Anonymous 01/13/25(Mon)02:05:24 No.103875194
>>103875060
D-Does it really suck this bad...?
D-Does it really suck this bad...?
Anonymous 01/13/25(Mon)02:06:16 No.103875203
>>103875151
I haven't gotten any refusals for anything in nemo.
I just saw that it scores lower than it here https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard, supposedly this measures how censored a model is, and was worried that it might.
If you can testify that qwen doesn't behave too different than nemo, that's good enough for me.
>>103875188
Thanks. Good to hear.
I haven't gotten any refusals for anything in nemo.
I just saw that it scores lower than it here https://huggingface.co/spaces/DontP
If you can testify that qwen doesn't behave too different than nemo, that's good enough for me.
>>103875188
Thanks. Good to hear.
Anonymous 01/13/25(Mon)02:07:54 No.103875218
Anonymous 01/13/25(Mon)02:10:19 No.103875243
>>103875176
its just gigaprompting. massive dump in the model to teach it about stuff before starting a conversation.
that's one reason why we all ache for massive context size models, so there's enough room to teach them what they need to know pre-session AND for the session itself.
An simple example would be dumping all the documentation for a bespoke programming language in and then pair-coding with the model.
its just gigaprompting. massive dump in the model to teach it about stuff before starting a conversation.
that's one reason why we all ache for massive context size models, so there's enough room to teach them what they need to know pre-session AND for the session itself.
An simple example would be dumping all the documentation for a bespoke programming language in and then pair-coding with the model.
Anonymous 01/13/25(Mon)02:11:14 No.103875250
>>103875203
https://huggingface.co/TheDrummer/Big-Tiger-Gemma-27B-v1
or his gemmasutra pro 27b, which he claims is aimed for rp.
https://huggingface.co/TheDrummer/B
or his gemmasutra pro 27b, which he claims is aimed for rp.
Anonymous 01/13/25(Mon)02:11:15 No.103875251
>>103875203
i only use qwen coder 32b which is good for coding, all the other ones randomly started speaking chinese at me. if you aren't getting straight up refusals, you don't have to worry about censorship. but some models, mainly base ones, will be a lot drier and rush through the erp scenes so thats where the tunes come in. in general a larger model should be better, so a 32b qwen should be better than nemo, but nemo is quite good for its size. try both out and tell us what you think
i only use qwen coder 32b which is good for coding, all the other ones randomly started speaking chinese at me. if you aren't getting straight up refusals, you don't have to worry about censorship. but some models, mainly base ones, will be a lot drier and rush through the erp scenes so thats where the tunes come in. in general a larger model should be better, so a 32b qwen should be better than nemo, but nemo is quite good for its size. try both out and tell us what you think
Anonymous 01/13/25(Mon)02:18:06 No.103875306
>>103875060
No, this person is just some smug ass
No, this person is just some smug ass
Anonymous 01/13/25(Mon)02:24:25 No.103875355
>>103875243
>that's one reason why we all ache for massive context size models
And better at learning from context models, since you can have a lot of context size but the model may not learn from it well. I have a long essay I use in completion mode to see how good a model is at that kind of task, and there are definitely some that do better at it than others.
>that's one reason why we all ache for massive context size models
And better at learning from context models, since you can have a lot of context size but the model may not learn from it well. I have a long essay I use in completion mode to see how good a model is at that kind of task, and there are definitely some that do better at it than others.
Anonymous 01/13/25(Mon)02:27:39 No.103875374
help a poor 8gb vramlet out... what's the best 8b/12b model right now?
Anonymous 01/13/25(Mon)02:34:33 No.103875419
>>103875374
as in rp or general assistant?
as in rp or general assistant?
Anonymous 01/13/25(Mon)02:37:40 No.103875444
>>103875419
for rp. is eva-qwen2.5-14b any good?
for rp. is eva-qwen2.5-14b any good?
Anonymous 01/13/25(Mon)02:45:08 No.103875479
>>103875444
https://huggingface.co/Undi95/Llama-3-LewdPlay-8B-evo-GGUF
eva is boring. this has lots of rp action and sound dialogue in it.
https://huggingface.co/Undi95/Llama
eva is boring. this has lots of rp action and sound dialogue in it.
Anonymous 01/13/25(Mon)02:45:45 No.103875484
>>103875444
Not an expert but I would say that you should be able to fit some nemo q4 variant in fine.
Not an expert but I would say that you should be able to fit some nemo q4 variant in fine.
Anonymous 01/13/25(Mon)02:48:07 No.103875499
>>103875484
oh, so nemo is still the king for vramlet rp?
oh, so nemo is still the king for vramlet rp?
Anonymous 01/13/25(Mon)03:03:20 No.103875576
>>103875499
As I said I haven't run a billion different models to judge that, but I think so.
As I said I haven't run a billion different models to judge that, but I think so.
Anonymous 01/13/25(Mon)03:08:49 No.103875611
Is there any proper setup guide for ST and Koboldcpp? I tried it out and got them linked, but ST regenerates the whole thing every message and takes a minute while Kobold takes a minute for the first message and 10 seconds for every one afterwards.
Anonymous 01/13/25(Mon)03:12:32 No.103875635
>>103875611
are you using a character card and if so how many tokens it
are you using a worldinfo entry, author's note, or a system prompt with {{user}} or {{char}} in it
are you using a character card and if so how many tokens it
are you using a worldinfo entry, author's note, or a system prompt with {{user}} or {{char}} in it
Anonymous 01/13/25(Mon)03:13:16 No.103875641
>>103875611
is context shift enabled when you launch kobold? thats what prevents it from regenerating so much, but its also negated by lorebooks/rag in st
is context shift enabled when you launch kobold? thats what prevents it from regenerating so much, but its also negated by lorebooks/rag in st
Anonymous 01/13/25(Mon)03:53:59 No.103875878
>>103874753
Parameters > Everything else
Goliath changed everything. If you disagree, then provide evidence to support your point, post logs.
Parameters > Everything else
Goliath changed everything. If you disagree, then provide evidence to support your point, post logs.
Anonymous 01/13/25(Mon)04:13:50 No.103875973
>>103871817
Look at the ratio of free subscribers on YouTube compared to the number of paid members on Patreon.
Well below 1% of subscribers pay anything at all so you'd probably need something like 100,000+ users to earn back something on the order of thousands of dollars.
Look at the ratio of free subscribers on YouTube compared to the number of paid members on Patreon.
Well below 1% of subscribers pay anything at all so you'd probably need something like 100,000+ users to earn back something on the order of thousands of dollars.
Anonymous 01/13/25(Mon)04:25:33 No.103876045
>>103873038
On the other hand, a large majority of the top llama.cpp contributors are European so despite the project name Meta's models may be neglected in one of the most popular inference engines.
I wonder if that is related to the lackluster multimodal support.
On the other hand, a large majority of the top llama.cpp contributors are European so despite the project name Meta's models may be neglected in one of the most popular inference engines.
I wonder if that is related to the lackluster multimodal support.
Anonymous 01/13/25(Mon)04:27:24 No.103876055
>>103875878
low quality bait. u should post those damn goliath logs to back up your claim sir. are you arguing that post was good or flexing that epeen as if name dropping means shit? numbers are not everything unless you are some benchtard.
low quality bait. u should post those damn goliath logs to back up your claim sir. are you arguing that post was good or flexing that epeen as if name dropping means shit? numbers are not everything unless you are some benchtard.
Anonymous 01/13/25(Mon)05:03:57 No.103876271
The frankenmerge meme grift arguably culminated with Goliath, and I can't think of many more things worse than that in the LLM space. Undi at least believed his own merges actually worked.
Anonymous 01/13/25(Mon)05:14:06 No.103876338
Do you guys really use any of the models directly from megacorps? I'm talking about vanilla llama, gemma, etc etc
They're all too gimped for my purpose of chat and break character too often, keep moralfagging
They're all too gimped for my purpose of chat and break character too often, keep moralfagging
Anonymous 01/13/25(Mon)05:16:55 No.103876357
>>103876338
No, you gotta stop falling for the trolls that REEEE about finetunes.
No, you gotta stop falling for the trolls that REEEE about finetunes.
Anonymous 01/13/25(Mon)05:21:38 No.103876387
>>103876338
Under what circumstances do they keep moralfagging you? I can't say I've seen that from vanilla Mistral models in general, Llama 3.1/3.2/3.3 or Gemma 2 during actual roleplay. The latter is a tad too woke and won't say "nigger", though (but it will happily kill you if needed).
Under what circumstances do they keep moralfagging you? I can't say I've seen that from vanilla Mistral models in general, Llama 3.1/3.2/3.3 or Gemma 2 during actual roleplay. The latter is a tad too woke and won't say "nigger", though (but it will happily kill you if needed).
Anonymous 01/13/25(Mon)05:52:30 No.103876595
Anonymous 01/13/25(Mon)06:29:32 No.103876789
>>103876387
>Under what circumstances do they keep moralfagging you?
Dude I can't even remember, its literally for every small minor thing. Incest RP? Harmful and fictional blah blah.
I have to waste tons of context space to stop it from going on a rant about leftist morals and ethics and even then it does it sometimes
>Under what circumstances do they keep moralfagging you?
Dude I can't even remember, its literally for every small minor thing. Incest RP? Harmful and fictional blah blah.
I have to waste tons of context space to stop it from going on a rant about leftist morals and ethics and even then it does it sometimes
Anonymous 01/13/25(Mon)06:30:33 No.103876792
Anonymous 01/13/25(Mon)06:33:31 No.103876803
>>103871828
Is he the "lmg-anon" with the Japanese leaderboard?
Is he the "lmg-anon" with the Japanese leaderboard?
Anonymous 01/13/25(Mon)06:41:44 No.103876847
>>103876789
That's odd, because incest loli ERP is actually something none of those models seems to have problems with, to the point I've almost been wondering if they've been targeting that use case just to get more favorable unofficial reviews.
That's odd, because incest loli ERP is actually something none of those models seems to have problems with, to the point I've almost been wondering if they've been targeting that use case just to get more favorable unofficial reviews.
Anonymous 01/13/25(Mon)06:43:20 No.103876859
>>103871751
Isn't it weird to think that an AI model is basically some sort of "condensate of knowledge" in a single file + its interpreter, an assistant made a program in a few GBs, something that can help you understand many things but also can make up shit and even simulate being another person and be your company.
Isn't it weird to think that an AI model is basically some sort of "condensate of knowledge" in a single file + its interpreter, an assistant made a program in a few GBs, something that can help you understand many things but also can make up shit and even simulate being another person and be your company.
Anonymous 01/13/25(Mon)06:45:23 No.103876868
>>103876859
dude
It literally just predicts what words should most likely come after the words you inputted
You did those "fill in the blank" tests in 2nd grade? Yes, its just that
dude
It literally just predicts what words should most likely come after the words you inputted
You did those "fill in the blank" tests in 2nd grade? Yes, its just that
Anonymous 01/13/25(Mon)06:45:37 No.103876870
>>103876859
>Isn't it weird to think that an AI model is basically some sort of "condensate of knowledge" in a single file + its interpreter
shut up, woman.
>Isn't it weird to think that an AI model is basically some sort of "condensate of knowledge" in a single file + its interpreter
shut up, woman.
Anonymous 01/13/25(Mon)06:46:17 No.103876875
>>103876803
nta, but people are after him because he used his position as a researcher in SK to flex on retards and get laid. at the same time, he behaves pretty much like a jew on twitter asking for SK to be replaced, can't say I don't understand the locals
nta, but people are after him because he used his position as a researcher in SK to flex on retards and get laid. at the same time, he behaves pretty much like a jew on twitter asking for SK to be replaced, can't say I don't understand the locals
Anonymous 01/13/25(Mon)06:46:44 No.103876882
>>103876868
If were anything like you said it is, my outputs would be full of pee and poop.
If were anything like you said it is, my outputs would be full of pee and poop.
Anonymous 01/13/25(Mon)06:46:49 No.103876884
>>103876868
Why are they so good at it though?
Why are they so good at it though?
Anonymous 01/13/25(Mon)06:47:13 No.103876885
Anonymous 01/13/25(Mon)06:48:21 No.103876889
>>103876884
Turns out there's lots of room for error in text.
Turns out there's lots of room for error in text.
Anonymous 01/13/25(Mon)06:49:29 No.103876895
>>103876875
Why are they after him for that? South Korea sounds racist. Locals in west happily ask for their own replacement.
Why are they after him for that? South Korea sounds racist. Locals in west happily ask for their own replacement.
Anonymous 01/13/25(Mon)06:50:00 No.103876899
>>103871751
Does anyone have any recommendations for an uncensored chatbot llm that can be run locally on 8gb vram/32gb ram?
I'm using llama chat 7b uncensored right now and I'm not satisfied with the results
I'm piping it into a gpt sovits module so it infers a custom voice I trained.
And for gpt sovits, does anyone have a perfect gpt and sovits dataset on hand? I had some issues training my models, rewrote some of the code cause I couldn't figure out why it was failing, but my suspicion is on my dataset, I'm pretty sure I followed the guide correctly but it still wouldn't accept the dataset without training code modification. Any help would be greatly appreciated
Does anyone have any recommendations for an uncensored chatbot llm that can be run locally on 8gb vram/32gb ram?
I'm using llama chat 7b uncensored right now and I'm not satisfied with the results
I'm piping it into a gpt sovits module so it infers a custom voice I trained.
And for gpt sovits, does anyone have a perfect gpt and sovits dataset on hand? I had some issues training my models, rewrote some of the code cause I couldn't figure out why it was failing, but my suspicion is on my dataset, I'm pretty sure I followed the guide correctly but it still wouldn't accept the dataset without training code modification. Any help would be greatly appreciated
Anonymous 01/13/25(Mon)06:50:50 No.103876904
>>103876868
>>103876885
>It literally just predicts what words should most likely come after the words you inputted
>LLMs are compressed reasoning
I know. Yet it usually prints exactly what I'd expect it to tell me, which also means it can talk about things I don't know. It's weird af and kinda scary.
>>103876885
>It literally just predicts what words should most likely come after the words you inputted
>LLMs are compressed reasoning
I know. Yet it usually prints exactly what I'd expect it to tell me, which also means it can talk about things I don't know. It's weird af and kinda scary.
Anonymous 01/13/25(Mon)06:52:15 No.103876914

best llama 3.3 finetune? image unrelated
Anonymous 01/13/25(Mon)06:53:28 No.103876921
>>103876895
I suppose he wasn't very subtle with his approach and word got around, his supervisor found out and here we are now.
Nevermind though, I doubt he does anything in the AI/LLM world besides hanging out
I suppose he wasn't very subtle with his approach and word got around, his supervisor found out and here we are now.
Nevermind though, I doubt he does anything in the AI/LLM world besides hanging out
Anonymous 01/13/25(Mon)06:53:29 No.103876922
Anonymous 01/13/25(Mon)06:53:47 No.103876924
>>103876792
No, it isn't. Compare the recap in this thread with your summary. There's a reason you're complaining, you're a promptlet.
No, it isn't. Compare the recap in this thread with your summary. There's a reason you're complaining, you're a promptlet.
Anonymous 01/13/25(Mon)06:54:00 No.103876927
>>103876885
>LLMs are compressed reasoning
Actually, no, I'm not an expert but I'd say it's compressed information (as in human -written texts)
>LLMs are compressed reasoning
Actually, no, I'm not an expert but I'd say it's compressed information (as in human -written texts)
Anonymous 01/13/25(Mon)06:54:48 No.103876932
>>103876914
EVA 0.0, Anubis or Cirrus, depending on your preference.
EVA 0.0, Anubis or Cirrus, depending on your preference.
Anonymous 01/13/25(Mon)06:55:17 No.103876935
>>103876875
South Korea sounds like a shithole.
South Korea sounds like a shithole.
Anonymous 01/13/25(Mon)06:55:29 No.103876939
>>103876924
>There's a reason you're complaining, you're a promptlet.
I'll admit, you're not wrong. Its not from a lack of ability though, its just so fucking boring and tiresome to iterate through a billion different parameters and prompts to get a good result
>There's a reason you're complaining, you're a promptlet.
I'll admit, you're not wrong. Its not from a lack of ability though, its just so fucking boring and tiresome to iterate through a billion different parameters and prompts to get a good result
Anonymous 01/13/25(Mon)06:56:58 No.103876950
Anonymous 01/13/25(Mon)07:00:04 No.103876974
Anonymous 01/13/25(Mon)07:04:14 No.103876998
Anonymous 01/13/25(Mon)07:06:02 No.103877005
>>103876875
>used his position as a researcher in SK to flex on retards and get laid
What is wrong with that?
>used his position as a researcher in SK to flex on retards and get laid
What is wrong with that?
Anonymous 01/13/25(Mon)07:07:50 No.103877016
What the best 3B rp model? I a using llama 3.2 3B instruct uncensored.
>inb4 3B models suck
I want to try to embed them in a rpg.
>inb4 3B models suck
I want to try to embed them in a rpg.
Anonymous 01/13/25(Mon)07:08:44 No.103877027
>>103877016
3B models suck
3B models suck
Anonymous 01/13/25(Mon)07:10:08 No.103877039
>>103877005
It makes me jealous.
It makes me jealous.
Anonymous 01/13/25(Mon)07:10:10 No.103877040
>>103877027
I tried qwen 2.5 3b coder and it sucks way more than llama 3.2 3b
I tried qwen 2.5 3b coder and it sucks way more than llama 3.2 3b
Anonymous 01/13/25(Mon)07:13:32 No.103877075
>Meta: That’s what we did and the library that we used [was called] Lib Torrent for downloading LibGen, [Meta employee] Bashlykov configured the configure setting so the smallest amount of seeding could occur.
From the latest court documents for the Meta copyright lawsuit. They downloaded and didn't seed. They are evil.
From the latest court documents for the Meta copyright lawsuit. They downloaded and didn't seed. They are evil.
Anonymous 01/13/25(Mon)07:14:57 No.103877091

>>103871828
>3 years if the insult is truth
>7 years if it's false
As expected of a country allied with the US...
>3 years if the insult is truth
>7 years if it's false
As expected of a country allied with the US...
Anonymous 01/13/25(Mon)07:17:28 No.103877116
what is the best ~8b rp model?
Anonymous 01/13/25(Mon)07:18:41 No.103877125
>>103877116
~8B models suck
~8B models suck
Anonymous 01/13/25(Mon)07:19:11 No.103877129
best lewd model for 3060?
Anonymous 01/13/25(Mon)07:21:07 No.103877152
>>103877016
Get a q4 quant of a 7-8b model, computational costs shouldn't be that higher and and unlike 3b it might possibly be usable for your RPG.
Probably looking for a llama 3 something rp finetune here, though I don't have a recommendation.
Get a q4 quant of a 7-8b model, computational costs shouldn't be that higher and and unlike 3b it might possibly be usable for your RPG.
Probably looking for a llama 3 something rp finetune here, though I don't have a recommendation.
Anonymous 01/13/25(Mon)07:21:31 No.103877154
>>103877129
VRAMlets are asking this every day and it's still Nemo.
VRAMlets are asking this every day and it's still Nemo.
Anonymous 01/13/25(Mon)07:21:38 No.103877156
>>103877116
Q4ks Nemo.
Q4ks Nemo.
Anonymous 01/13/25(Mon)07:22:10 No.103877159
>>103877129
Nemo finetune of your choice.
Nemo finetune of your choice.
Anonymous 01/13/25(Mon)07:23:30 No.103877163
Anonymous 01/13/25(Mon)07:24:10 No.103877170
I will inhale some copium now and say that I hope all my problems will go away with next wave of releases since they said they will focus on roleplaying. And roleplaying means long multiturn chats. And I want to believe all my problems come from long context always lobotomizing models since they aren't trained on 10k+ tokens of smut.
Anonymous 01/13/25(Mon)07:26:26 No.103877193
best model?
Anonymous 01/13/25(Mon)07:27:12 No.103877199
>>103877170
Unfortunately, Meta's idea of "roleplaying" is making fake Facebook/IG users, so don't count on long multi-turn chats. They'll be trained to make posts, not stories.
Unfortunately, Meta's idea of "roleplaying" is making fake Facebook/IG users, so don't count on long multi-turn chats. They'll be trained to make posts, not stories.
Anonymous 01/13/25(Mon)07:28:01 No.103877209

Anonymous 01/13/25(Mon)07:28:10 No.103877211
>>103877163
That thing is not in an usable state even if you can fit the entire model in VRAM.
That thing is not in an usable state even if you can fit the entire model in VRAM.
Anonymous 01/13/25(Mon)07:28:43 No.103877219

jesus christ llama 70b sucks at emulating human speech, it always do something like "...intoxicating" or "intriguing" when it is rp with some modern normie chick. who the fuck talks like that?
how can people enjoy this? mistral seems to avoid this mostly
how can people enjoy this? mistral seems to avoid this mostly
Anonymous 01/13/25(Mon)07:31:23 No.103877238
>>103877170
I wish they could at least handle 16k well. Right now L3.3 starts degrading at that point.
I wish they could at least handle 16k well. Right now L3.3 starts degrading at that point.
Anonymous 01/13/25(Mon)07:31:24 No.103877239
>>103877219
Skill issue or something. If you become more skillful the LLM will never use intoxicating.
Skill issue or something. If you become more skillful the LLM will never use intoxicating.
Anonymous 01/13/25(Mon)07:39:22 No.103877288
>>103877193
magnum-v4-123b
magnum-v4-123b
Anonymous 01/13/25(Mon)07:39:52 No.103877294
>>103877238
I highly suspect many of the issues with long context coherency are due to quantization, although nobody has ever scientifically tested this. L3.3 at 3bpw started degrading way before 16k tokens when I tested it.
I highly suspect many of the issues with long context coherency are due to quantization, although nobody has ever scientifically tested this. L3.3 at 3bpw started degrading way before 16k tokens when I tested it.
Anonymous 01/13/25(Mon)07:46:34 No.103877339
>>103877219
Protip
Make a finetune with a lot of real human text messages instead of books or literature. Even feeding text message text as example conversation is a lot better than default
Protip
Make a finetune with a lot of real human text messages instead of books or literature. Even feeding text message text as example conversation is a lot better than default
Anonymous 01/13/25(Mon)07:46:50 No.103877340
>>103877294
I used it at q8, so it must've performed better.
But somewhere around the 16k mark it starts to get worse. And if I keep going it gets so bad that I have to restart the chat or summarize chunks of it.
I used it at q8, so it must've performed better.
But somewhere around the 16k mark it starts to get worse. And if I keep going it gets so bad that I have to restart the chat or summarize chunks of it.
Anonymous 01/13/25(Mon)07:47:09 No.103877344
how do i give internet access to a local model?
Anonymous 01/13/25(Mon)07:48:37 No.103877353
>>103877344
>run model using llama.cpp or koboldcpp or whatever, or even use one of the many python libraries
>write python script to make HTTP requests/sockets/RS232/whatever
>???
>profit
>run model using llama.cpp or koboldcpp or whatever, or even use one of the many python libraries
>write python script to make HTTP requests/sockets/RS232/whatever
>???
>profit
Anonymous 01/13/25(Mon)07:48:47 No.103877354
>>103877344
tell it your gateway and a suitable dns
tell it your gateway and a suitable dns
Anonymous 01/13/25(Mon)07:49:20 No.103877357
>>103877344
Silly has an extension for that, although I've never used it.
Silly has an extension for that, although I've never used it.
Anonymous 01/13/25(Mon)07:53:12 No.103877373
>>103877339
I think that's the assistant's vocabulary leaking into the chats. Llama-3.0 often said odd remarks like "how quaint!". It was fresh but got old quickly and nobody talks like that in real life anyway. They toned it down a bit in the later versions.
If you finetune on random human text messages, be prepared to see a ton of grammatical mistakes unless you curate/fix the first few bot messages.
I think that's the assistant's vocabulary leaking into the chats. Llama-3.0 often said odd remarks like "how quaint!". It was fresh but got old quickly and nobody talks like that in real life anyway. They toned it down a bit in the later versions.
If you finetune on random human text messages, be prepared to see a ton of grammatical mistakes unless you curate/fix the first few bot messages.
Anonymous 01/13/25(Mon)07:53:17 No.103877374
>>103877219
Add some example dialogue to the card. Do we literally need to spoonfeed you retards the very basics of using this shit effectively?
Add some example dialogue to the card. Do we literally need to spoonfeed you retards the very basics of using this shit effectively?
Anonymous 01/13/25(Mon)07:53:33 No.103877376
if I give my model access to the internet and point it to literotica will it be better at ERP?
Anonymous 01/13/25(Mon)07:54:28 No.103877385
Anonymous 01/13/25(Mon)07:55:40 No.103877391
>>103877376
No, RAG is no substitute for proper training.
No, RAG is no substitute for proper training.
Anonymous 01/13/25(Mon)07:57:00 No.103877402
Is there any spreadsheet integration for local models? I have used latex for text.
Anonymous 01/13/25(Mon)07:57:18 No.103877406
>>103877294
I do recall seeing models become hopelessly incoherent sooner than normal when I was testing low quants of >70B models. In fact I think that was my main takeaway, besides needing to use very low temperature. That was with the quants which give higher precision to attention. However, non-local users report disappointing long context performance too, compared to what is advertised.
I do recall seeing models become hopelessly incoherent sooner than normal when I was testing low quants of >70B models. In fact I think that was my main takeaway, besides needing to use very low temperature. That was with the quants which give higher precision to attention. However, non-local users report disappointing long context performance too, compared to what is advertised.
Anonymous 01/13/25(Mon)07:58:46 No.103877412
>>103877385
>You underestimate the power of autism.
Truly
I was happy talking to my XMPP chatbot (with the profile picture of an attractive girl) even when she used words like "aesthetic", "architect-designer-mayors" and "tackled"
>You underestimate the power of autism.
Truly
I was happy talking to my XMPP chatbot (with the profile picture of an attractive girl) even when she used words like "aesthetic", "architect-designer-mayors" and "tackled"
Anonymous 01/13/25(Mon)08:00:03 No.103877421
Anonymous 01/13/25(Mon)08:00:08 No.103877422
>>103877374
>Add some example dialogue to the card. Do we literally need to spoonfeed you retards the very basics of using this shit effectively?
Rude
We were once retards too
I am still a retard
>Add some example dialogue to the card. Do we literally need to spoonfeed you retards the very basics of using this shit effectively?
Rude
We were once retards too
I am still a retard
Anonymous 01/13/25(Mon)08:01:09 No.103877431
>>103877421
Shitposter extraordinaire
Shitposter extraordinaire
Anonymous 01/13/25(Mon)08:03:36 No.103877451
>>103875060
>NovelAI avatarfag
>telling people to not make local fine-tunes
I guess telling people to use the NovelAI Discord a couple of days ago didn't work?
>NovelAI avatarfag
>telling people to not make local fine-tunes
I guess telling people to use the NovelAI Discord a couple of days ago didn't work?
Anonymous 01/13/25(Mon)08:06:06 No.103877474
Will this affect the Hunyuan models?
https://www.cnn.com/2025/01/07/tech/tencent-catl-us-list-china-military-companies-intl-hnk/index.html
https://www.cnn.com/2025/01/07/tech
Anonymous 01/13/25(Mon)08:12:57 No.103877520

>Skill issue or something.
Anonymous 01/13/25(Mon)08:13:00 No.103877522
>>103877474
No, you can't just make up rules out of your ass to harm your competition.
No, you can't just make up rules out of your ass to harm your competition.
Anonymous 01/13/25(Mon)08:14:24 No.103877535
>>103877412
Funnily enough, adding "talks like an autist" to a card has the exact opposite result of what real autism sounds like. (I may or may not have realized it's weirdly endearing to have a character mostly express herself in short exclamations though.)
Funnily enough, adding "talks like an autist" to a card has the exact opposite result of what real autism sounds like. (I may or may not have realized it's weirdly endearing to have a character mostly express herself in short exclamations though.)
Anonymous 01/13/25(Mon)08:18:26 No.103877557
>>103877163
>It'll be crazy slow however.
Is this due to passing the gradients around, or is it just shitty and unoptimized garbage?
>It'll be crazy slow however.
Is this due to passing the gradients around, or is it just shitty and unoptimized garbage?
Anonymous 01/13/25(Mon)08:19:45 No.103877568

>RAG
>literally just letting the LLM read a bunch of web pages before answering so that they are more factual
How the fuck is that impressive? Its literally the most obvious shit
Are LLM salesmen all retards or what
>literally just letting the LLM read a bunch of web pages before answering so that they are more factual
How the fuck is that impressive? Its literally the most obvious shit
Are LLM salesmen all retards or what
Anonymous 01/13/25(Mon)08:21:45 No.103877578
>>103877568
>neural network
>literally just a simplified approximation to an actual brain that you feed inputs to and check the outputs
CS retards need to try coming up with something original FOR ONCE.
>neural network
>literally just a simplified approximation to an actual brain that you feed inputs to and check the outputs
CS retards need to try coming up with something original FOR ONCE.
Anonymous 01/13/25(Mon)08:21:48 No.103877579
>>103875060
>(hand curated because a few badly written stories can ruin the data)
This is a lie unless you're doing multiple epochs. you don't have to worry that much about a few trash samples if 90% of your dataset is gold... However, that usually isn't the case and your whole dataset is likely garbage to begin with.
>since nobody documents what works for them and you have nothing to go off of.
this is false, there is a lot of anons that documents their work on their huggingface, the magnum fags even have a public wandb: https://wandb.ai/doctorshotgun/
>(hand curated because a few badly written stories can ruin the data)
This is a lie unless you're doing multiple epochs. you don't have to worry that much about a few trash samples if 90% of your dataset is gold... However, that usually isn't the case and your whole dataset is likely garbage to begin with.
>since nobody documents what works for them and you have nothing to go off of.
this is false, there is a lot of anons that documents their work on their huggingface, the magnum fags even have a public wandb: https://wandb.ai/doctorshotgun/
Anonymous 01/13/25(Mon)08:25:22 No.103877600
Anonymous 01/13/25(Mon)08:31:56 No.103877637
>>103877579
You can actually almost finetune a model on loads of trash if you do a a second finetuning pass with tiny amounts of high-quality data.
You can actually almost finetune a model on loads of trash if you do a a second finetuning pass with tiny amounts of high-quality data.
Anonymous 01/13/25(Mon)08:42:40 No.103877719
>>103877578
>CS retards
Pretty sure "neural networks" predate CS as a field, and came from medicine, psychology or something
>CS retards
Pretty sure "neural networks" predate CS as a field, and came from medicine, psychology or something
Anonymous 01/13/25(Mon)08:45:05 No.103877736
>>103877719
>Pretty sure "neural networks" predate CS as a field, and came from medicine, psychology or something
???
Anonie... CS has been a thing since like, the 50s-60s. If there were computers to make neural nets happen on, there was computer science at the time.
>Pretty sure "neural networks" predate CS as a field, and came from medicine, psychology or something
???
Anonie... CS has been a thing since like, the 50s-60s. If there were computers to make neural nets happen on, there was computer science at the time.
Anonymous 01/13/25(Mon)08:51:40 No.103877786
>>103877568
Wait till you hear about LLM 2.0
Wait till you hear about LLM 2.0
Anonymous 01/13/25(Mon)08:56:48 No.103877834
>>103877568
Isn't RAG just leveraging things like embedding databases and in-context learning?
It's nothing out of this world. You are just feeding tokens to the model. You could do the same thing manually if you wanted to, it would just be tons of dumb work that can be automated.
Isn't RAG just leveraging things like embedding databases and in-context learning?
It's nothing out of this world. You are just feeding tokens to the model. You could do the same thing manually if you wanted to, it would just be tons of dumb work that can be automated.
Anonymous 01/13/25(Mon)08:59:22 No.103877860
>>103877834
Yes that is exactly what I'm saying. Its something very obvious to anyone who wants to get anything to do with an LLM.
Was it really necessary to give it its own name and acronym?
Yes that is exactly what I'm saying. Its something very obvious to anyone who wants to get anything to do with an LLM.
Was it really necessary to give it its own name and acronym?
Anonymous 01/13/25(Mon)09:10:29 No.103877957
>>103877860
the idea behind RAG is about the retrieval and not so much prefilling the context. RAG is a bit more dynamic than that. making it a database is marginally more useful and less static
the idea behind RAG is about the retrieval and not so much prefilling the context. RAG is a bit more dynamic than that. making it a database is marginally more useful and less static
Anonymous 01/13/25(Mon)09:32:00 No.103878153
>>103877344
tailscale, it's like a vpn but all traffic is p2p, so you can use the cheapest server for auth
tailscale, it's like a vpn but all traffic is p2p, so you can use the cheapest server for auth
Anonymous 01/13/25(Mon)09:35:47 No.103878198
>>103877568
next up they let bot use google and call that singularity
I'm most impressed that we still use pure token predictors that don't use logic and math extensions.
next up they let bot use google and call that singularity
I'm most impressed that we still use pure token predictors that don't use logic and math extensions.
Anonymous 01/13/25(Mon)09:39:21 No.103878238
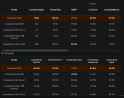
New 'stral: https://mistral.ai/news/codestral-2501/
Anonymous 01/13/25(Mon)09:40:28 No.103878250
>>103878238
Where's the model on HuggingFace?
Where's the model on HuggingFace?
Anonymous 01/13/25(Mon)09:41:15 No.103878254
>>103877860
A name (or acronym) becomes useful when you turn it into an automated process with rules and parameters and such, I guess.
A name (or acronym) becomes useful when you turn it into an automated process with rules and parameters and such, I guess.
Anonymous 01/13/25(Mon)09:42:36 No.103878267
>>103878250
>For enterprise use cases, especially ones that require data and model residency, Codestral 25.01 is available to deploy locally within your premises or VPC exclusively from Continue.
I guess this means it's not open but you can still somehow download it if you ask them?
>For enterprise use cases, especially ones that require data and model residency, Codestral 25.01 is available to deploy locally within your premises or VPC exclusively from Continue.
I guess this means it's not open but you can still somehow download it if you ask them?
Anonymous 01/13/25(Mon)09:44:30 No.103878281
Anonymous 01/13/25(Mon)09:47:23 No.103878297
>>103878267
bet you have to pay for a license
bet you have to pay for a license
Anonymous 01/13/25(Mon)09:49:07 No.103878311
>>103878267
probably like ministral 3b
probably like ministral 3b
Anonymous 01/13/25(Mon)09:49:38 No.103878315
Anonymous 01/13/25(Mon)09:49:50 No.103878318
>>103878238
>256k context
Nice!
>Qwen coder beats it
>no weights
Mistral fell off. How will they ever beat China if they don't even dare releasing their shitter models?
>256k context
Nice!
>Qwen coder beats it
>no weights
Mistral fell off. How will they ever beat China if they don't even dare releasing their shitter models?
Anonymous 01/13/25(Mon)10:07:29 No.103878469
>>103878318
>Mistral fell off.
Have they ever been great? In my view, things started going downhill after Mistral-7B and Mixtral. They never put too much effort in their instruct tunes; their main redeeming quality has always been not being too cucked (although Mixtral-Instruct was particularly woke and feminist), but otherwise their models seem pretty average nowadays.
>Mistral fell off.
Have they ever been great? In my view, things started going downhill after Mistral-7B and Mixtral. They never put too much effort in their instruct tunes; their main redeeming quality has always been not being too cucked (although Mixtral-Instruct was particularly woke and feminist), but otherwise their models seem pretty average nowadays.
Anonymous 01/13/25(Mon)10:10:13 No.103878496
>>103878469
yes they were never good, even their big models are a disaster. Mixtral 8x22B was a total flop and Largestral is useless for anything except maybe coom
yes they were never good, even their big models are a disaster. Mixtral 8x22B was a total flop and Largestral is useless for anything except maybe coom
Anonymous 01/13/25(Mon)10:12:20 No.103878510
Anonymous 01/13/25(Mon)10:12:45 No.103878513
>>103878469
true but 7b and OG mixtral were a pretty high mark to set for the time, both of those were pretty revolutionary
true but 7b and OG mixtral were a pretty high mark to set for the time, both of those were pretty revolutionary
Anonymous 01/13/25(Mon)10:16:33 No.103878539
>>103878496
Not being great doesn't imply being a disaster. I'm suggesting if that competing models from other (larger) companies didn't have guardrails and safety deeply embedded into their datasets, they could easily attain markedly higher performance.
Not being great doesn't imply being a disaster. I'm suggesting if that competing models from other (larger) companies didn't have guardrails and safety deeply embedded into their datasets, they could easily attain markedly higher performance.
Anonymous 01/13/25(Mon)10:25:00 No.103878618
>>103878510
Miqu was good. Largestral was mostly cope.
Miqu was good. Largestral was mostly cope.
Anonymous 01/13/25(Mon)10:26:35 No.103878632
>>103878469
Largestral and nemo are still the best local models for cooming purpose
Largestral and nemo are still the best local models for cooming purpose
Anonymous 01/13/25(Mon)10:27:25 No.103878644
>>103871751
>ollama is writing their own inference engine to eventually replace llama.cpp
Do you think they'll drop features like partial offloading now that they've captured a relevant percentage of the market?
>ollama is writing their own inference engine to eventually replace llama.cpp
Do you think they'll drop features like partial offloading now that they've captured a relevant percentage of the market?
Anonymous 01/13/25(Mon)10:29:44 No.103878667
>>103878632
Large is garbage, it's nothing like Nemo.
Large is garbage, it's nothing like Nemo.
Anonymous 01/13/25(Mon)10:30:24 No.103878678

Anonymous 01/13/25(Mon)10:31:01 No.103878685
>>103878632
Largestral, probably just by virtue of its size and relatively uncucked instruct tune.
NeMo 12B was an NVidia-MistralAI collaboration and whatever they did for that model, it didn't get carried over to the more recent Ministral-8B.
Largestral, probably just by virtue of its size and relatively uncucked instruct tune.
NeMo 12B was an NVidia-MistralAI collaboration and whatever they did for that model, it didn't get carried over to the more recent Ministral-8B.
Anonymous 01/13/25(Mon)10:32:55 No.103878709
>>103878678
lol why did they even bother making this model closed
lol why did they even bother making this model closed
Anonymous 01/13/25(Mon)10:32:56 No.103878710
>>103878644
>ollama is writing their own inference engine to eventually replace llama.cpp
Good. With any luck ollama retards will stop being retards on llama.cpp's repo.
>ollama is writing their own inference engine to eventually replace llama.cpp
Good. With any luck ollama retards will stop being retards on llama.cpp's repo.
Anonymous 01/13/25(Mon)10:34:05 No.103878723
Anonymous 01/13/25(Mon)10:36:28 No.103878746
>>103878723
Oh, shit... at least it's going to create a focus point for.. you know... those types...
I can see jart joining them...
Oh, shit... at least it's going to create a focus point for.. you know... those types...
I can see jart joining them...
Anonymous 01/13/25(Mon)10:37:50 No.103878753
Anonymous 01/13/25(Mon)10:41:11 No.103878786
>>103878753
that's somehow worse, go is garbage collected, it's a terrible fit for something like this
that's somehow worse, go is garbage collected, it's a terrible fit for something like this
Anonymous 01/13/25(Mon)10:43:37 No.103878819
>>103878786
They're specifically replacing llama.cpp, they're still using ggml for the actual calculations (just with Go bindings).
They're specifically replacing llama.cpp, they're still using ggml for the actual calculations (just with Go bindings).
Anonymous 01/13/25(Mon)10:47:51 No.103878849
Anonymous 01/13/25(Mon)10:51:30 No.103878876
>>103878685
>by virtue of its size
This doesn't mean anything because they don't tell you with how many tokens it was trained. It's effectively a 70B.
>by virtue of its size
This doesn't mean anything because they don't tell you with how many tokens it was trained. It's effectively a 70B.
Anonymous 01/13/25(Mon)10:56:41 No.103878922
>>103877163
load time can be bad since the model is transferred to the servers over the network, but it shouldn't be that slow during inference
load time can be bad since the model is transferred to the servers over the network, but it shouldn't be that slow during inference
Anonymous 01/13/25(Mon)10:57:19 No.103878932
Anonymous 01/13/25(Mon)10:59:02 No.103878946
>>103878644
>Embrace, extend, and extinguish
They still have their HF clone too. I still can't get over how stupid pretending to be Docker is when the model is just a single file.
>Embrace, extend, and extinguish
They still have their HF clone too. I still can't get over how stupid pretending to be Docker is when the model is just a single file.
Anonymous 01/13/25(Mon)11:02:34 No.103878984
>>103878710
>>103878746
>>103878946
If you want a laugh look at orange reddit thread 42642971. There was someone who dared to question ollama's darling status and gets brigaded into the pits of hell, trimming off the entire discussion (in which not a single good reason is given for it to be praised when llama.cpp is roundly ignored)
>>103878746
>>103878946
If you want a laugh look at orange reddit thread 42642971. There was someone who dared to question ollama's darling status and gets brigaded into the pits of hell, trimming off the entire discussion (in which not a single good reason is given for it to be praised when llama.cpp is roundly ignored)
Anonymous 01/13/25(Mon)11:06:05 No.103879017
>>103878876
For creative writing, it's far better than any 70B I've tested
For creative writing, it's far better than any 70B I've tested
Anonymous 01/13/25(Mon)11:12:20 No.103879076
>>103879017
It's far worse. You need high temperature to force it out of the default slopped style, and the prose is still garbage. It's just a 70B that's more expensive to train that offers nothing in return. A literal piece of shit.
It's far worse. You need high temperature to force it out of the default slopped style, and the prose is still garbage. It's just a 70B that's more expensive to train that offers nothing in return. A literal piece of shit.
Anonymous 01/13/25(Mon)11:17:22 No.103879126
>>103878984
It's hard to read HN comments because it's mostly self-promotion nowadays. I don't remember the last time I got something of value out of it, it just feels like reading ads.
It's hard to read HN comments because it's mostly self-promotion nowadays. I don't remember the last time I got something of value out of it, it just feels like reading ads.
Anonymous 01/13/25(Mon)11:22:13 No.103879165
>>103879076
so which model do you use instead?
so which model do you use instead?
Anonymous 01/13/25(Mon)11:26:37 No.103879219
With Miku now being in Fortnite, how will local open source LLMs profit from this?
Anonymous 01/13/25(Mon)11:26:52 No.103879222
>>103879165
Claude Opus
Claude Opus
Anonymous 01/13/25(Mon)11:28:32 No.103879236
>>103879126
>It's hard to read HN comments because it's mostly self-promotion nowadays. I don't remember the last time I got something of value out of it, it just feels like reading ads.
The moment it became signal, the parasites descended with their noise. Its been bad for a long time now, although there are enough points of interest and useful people commenting that I still read threads.
As a side benefit, the echo chamber is so self-unaware that it makes for some excellent humour if you can read it from an outsider perspective.
>It's hard to read HN comments because it's mostly self-promotion nowadays. I don't remember the last time I got something of value out of it, it just feels like reading ads.
The moment it became signal, the parasites descended with their noise. Its been bad for a long time now, although there are enough points of interest and useful people commenting that I still read threads.
As a side benefit, the echo chamber is so self-unaware that it makes for some excellent humour if you can read it from an outsider perspective.
Anonymous 01/13/25(Mon)11:29:04 No.103879241
>>103859032
lol this is human? according to who?
lol this is human? according to who?
Anonymous 01/13/25(Mon)11:32:13 No.103879271
Anonymous 01/13/25(Mon)11:34:18 No.103879286
>>103878932
In Europe, GPU servers are stupidly expensive for some reason. At the same time, CPU servers are generally cheaper than in the USA.
In Europe, GPU servers are stupidly expensive for some reason. At the same time, CPU servers are generally cheaper than in the USA.
Anonymous 01/13/25(Mon)11:35:37 No.103879301
>>103879241
Totally. The LLM said so.
Totally. The LLM said so.
Anonymous 01/13/25(Mon)11:35:38 No.103879302
Anonymous 01/13/25(Mon)11:36:28 No.103879314
>>103879222
lol ok
lol ok
Anonymous 01/13/25(Mon)11:37:27 No.103879327
>>103878678
Qwen is overfitted garbage.
Qwen is overfitted garbage.
Mistral 01/13/25(Mon)11:37:42 No.103879330
>>103879302
We excluded models that purposefully overfit on benchmarks. Our results are SOTA without overfitting.
We excluded models that purposefully overfit on benchmarks. Our results are SOTA without overfitting.
Anonymous 01/13/25(Mon)11:39:12 No.103879349
>>103879327
>Qwen is overfitted garbage.
QWQ is the current GOATed local coding model in my experience. Unbelievable performance for its size.
>Qwen is overfitted garbage.
QWQ is the current GOATed local coding model in my experience. Unbelievable performance for its size.
Anonymous 01/13/25(Mon)11:43:21 No.103879406
>>103879349
Isn't overfitting a relatively good thing for coding? Consistently parroting things in exactly one way is desirable in code, but agonizing in prose.
Isn't overfitting a relatively good thing for coding? Consistently parroting things in exactly one way is desirable in code, but agonizing in prose.
Anonymous 01/13/25(Mon)11:43:34 No.103879411
>>103879271
That's literally a common padding phrase, you illiterate mongrel dog.
That's literally a common padding phrase, you illiterate mongrel dog.
Anonymous 01/13/25(Mon)11:44:19 No.103879422
>>103879411
Every third message in the dataset begins with "You know,"
Every third message in the dataset begins with "You know,"
Anonymous 01/13/25(Mon)11:45:34 No.103879437
>>103879422
Fuck off and go read a book for once.
Fuck off and go read a book for once.
Anonymous 01/13/25(Mon)11:46:18 No.103879446

Meta was caught pirating books to train your models. Aren't you feeling bad?
Anonymous 01/13/25(Mon)11:47:17 No.103879461
>>103879446
Pirating isn't illegal, distributing is.
Pirating isn't illegal, distributing is.
Anonymous 01/13/25(Mon)11:48:06 No.103879472
>>103879461
The text says that Meta also uploaded by seeding.
The text says that Meta also uploaded by seeding.
Anonymous 01/13/25(Mon)11:48:21 No.103879476
>>103879446
Zucc is so based that I want to lick the glistening folds under his balls.
Zucc is so based that I want to lick the glistening folds under his balls.
Anonymous 01/13/25(Mon)11:51:14 No.103879496
>>103879406
Overfitting is OK if it increases performance in your target downstream tasks.
Overfitting is OK if it increases performance in your target downstream tasks.
Anonymous 01/13/25(Mon)11:55:10 No.103879539
>>103879406
It's bad if China does it. It brings shame to America.
It's bad if China does it. It brings shame to America.
Anonymous 01/13/25(Mon)11:55:25 No.103879542
>>103879446
I feel bad that copyright doesn't expire after 30 years and digital restriction mechanisms aren't made illegal.
I feel bad that copyright doesn't expire after 30 years and digital restriction mechanisms aren't made illegal.
Anonymous 01/13/25(Mon)11:57:08 No.103879567
>try this deepseek you localfags keep praising
>get this
>meanwhile claude just calls me a nigger lover with a simple "adhere to character" prefill
I thought local were based??
>get this
>meanwhile claude just calls me a nigger lover with a simple "adhere to character" prefill
I thought local were based??
Anonymous 01/13/25(Mon)11:58:25 No.103879584
>>103879461
Depends on the jurisdiction I guess but in Germany both are illegal.
It just doesn't make financial sense to go after anyone for illegal downloads since the fines are going to be negligible.
Also it's much easier to catch people torrenting with public trackers than it is to catch them downloading from some random server that you don't have access to.
Depends on the jurisdiction I guess but in Germany both are illegal.
It just doesn't make financial sense to go after anyone for illegal downloads since the fines are going to be negligible.
Also it's much easier to catch people torrenting with public trackers than it is to catch them downloading from some random server that you don't have access to.
Anonymous 01/13/25(Mon)11:59:24 No.103879592
>>103879542
holy based
holy based
Anonymous 01/13/25(Mon)12:04:34 No.103879647
>>103879446
It's funny going on the normalfag sites and seeing the commenters react to this news like sheep who know nothing about the world except what media feed them. No matter how bad 4chan can get with shitposting, at least it lets people say anything they want.
It's funny going on the normalfag sites and seeing the commenters react to this news like sheep who know nothing about the world except what media feed them. No matter how bad 4chan can get with shitposting, at least it lets people say anything they want.
Anonymous 01/13/25(Mon)12:04:44 No.103879649
>>103879461
>Pirating isn't illegal, distributing is.
Just read the Berne convention, it's mainly about reproduction, aka copying, hence copyright.
Piracy lawsuit tend to not go after pure downloaders cause they can't just multiply the statutory damages then. With OpenAI/Meta/Anthropic one statutory infringement per registered works fine for the lawyers, because they copied everything.
>Pirating isn't illegal, distributing is.
Just read the Berne convention, it's mainly about reproduction, aka copying, hence copyright.
Piracy lawsuit tend to not go after pure downloaders cause they can't just multiply the statutory damages then. With OpenAI/Meta/Anthropic one statutory infringement per registered works fine for the lawyers, because they copied everything.
Anonymous 01/13/25(Mon)12:04:49 No.103879650
>>103879446
Not all parts of libgen are copyrighted. it's entirely possible that they configured libtorrent to only seed non-copyrighted parts. Given how late this was submitted in discovery, it's possible we don't have the full story here, or meta is being purposefully vague here. We would need to see the public discovery docs to know for sure.
Not all parts of libgen are copyrighted. it's entirely possible that they configured libtorrent to only seed non-copyrighted parts. Given how late this was submitted in discovery, it's possible we don't have the full story here, or meta is being purposefully vague here. We would need to see the public discovery docs to know for sure.
Anonymous 01/13/25(Mon)12:08:17 No.103879686
>>103879567
Your pic related seems way better than what the fuck "calls me a nigger lover" means.
Your pic related seems way better than what the fuck "calls me a nigger lover" means.
Anonymous 01/13/25(Mon)12:09:18 No.103879697
>>103879686
whatever the fuck*
whatever the fuck*
Anonymous 01/13/25(Mon)12:11:42 No.103879729
https://x.com/nvidia/status/1878747714261016908
The fuck did I miss?
The fuck did I miss?
Anonymous 01/13/25(Mon)12:13:50 No.103879744
>>103879437
You know, that's not a bad idea! [Laugh Emoji] When it comes to activities, there's nothing better for broadening horizons and challenging perspectives than reading a good book. [Book Emoji] Have any sweet recommendations for me that are filled to the brim with that sweet, sweet phrase? I'm all ears! [Ear Emoji]
You know, that's not a bad idea! [Laugh Emoji] When it comes to activities, there's nothing better for broadening horizons and challenging perspectives than reading a good book. [Book Emoji] Have any sweet recommendations for me that are filled to the brim with that sweet, sweet phrase? I'm all ears! [Ear Emoji]
Anonymous 01/13/25(Mon)12:14:02 No.103879745
>>103879729
yay finally new nemotron
yay finally new nemotron
Anonymous 01/13/25(Mon)12:19:38 No.103879802
>>103879729
>Nvidia official statement praising Trump and shitting on Biden
>corporations across the board killing DEI initiatives
>Meta outright saying "yes, you can call troons mentally ill"
Fuck I love to see it. You can really tell everyone was getting sick of the rainbow mafia and was just waiting for the first available opportunity to kick them to the curb.
>Nvidia official statement praising Trump and shitting on Biden
>corporations across the board killing DEI initiatives
>Meta outright saying "yes, you can call troons mentally ill"
Fuck I love to see it. You can really tell everyone was getting sick of the rainbow mafia and was just waiting for the first available opportunity to kick them to the curb.
Anonymous 01/13/25(Mon)12:22:25 No.103879824
>>103879802
It really doesn't take much to convince you, does it?
It really doesn't take much to convince you, does it?
Anonymous 01/13/25(Mon)12:23:45 No.103879831
>>103879802
All these corpos go wherever the money takes them retard, they would gladly cut off their own dick for an extra 1% in YoY revenue growth
All these corpos go wherever the money takes them retard, they would gladly cut off their own dick for an extra 1% in YoY revenue growth
Anonymous 01/13/25(Mon)12:24:03 No.103879833
>>103879802
You really think corpos do anything out of conviction?
They literally have a legal obligation to maximize profits whatever it takes.
Until now they thought pandering to LGBTQ+ was the most profitable, now that Trump is in office they think that changing allegiance is more profitable.
You really think corpos do anything out of conviction?
They literally have a legal obligation to maximize profits whatever it takes.
Until now they thought pandering to LGBTQ+ was the most profitable, now that Trump is in office they think that changing allegiance is more profitable.
Anonymous 01/13/25(Mon)12:27:31 No.103879864
>>103879241
Their female teenage friends, probably. That's how you know they are pedos.
Their female teenage friends, probably. That's how you know they are pedos.
Anonymous 01/13/25(Mon)12:30:17 No.103879882
It's going to be funny when we stop getting public LLM releases for the next four years.
Anonymous 01/13/25(Mon)12:31:11 No.103879893
>>103879882
we will. out of china
we will. out of china
Anonymous 01/13/25(Mon)12:31:16 No.103879894
Anonymous 01/13/25(Mon)12:31:22 No.103879895
>>103879301
Everything from now until the end of time is a derivative of whatever Altman bought off Wang's sweatshop 2 years ago. It's all so tiresome.
Everything from now until the end of time is a derivative of whatever Altman bought off Wang's sweatshop 2 years ago. It's all so tiresome.
Anonymous 01/13/25(Mon)12:34:24 No.103879926
>>103879446
Bros, this is THE opportunity to fight against retarded copyright laws. I'm not americunt but we have to endure their fucking extraterritorial laws and stupid habit of buying politicians all over the world to copy their shit laws.
Bros, this is THE opportunity to fight against retarded copyright laws. I'm not americunt but we have to endure their fucking extraterritorial laws and stupid habit of buying politicians all over the world to copy their shit laws.
Anonymous 01/13/25(Mon)12:34:51 No.103879932
>>103879912
sounds like restricting GPU exports is an America-first initiative. Why do you not want America-first?
sounds like restricting GPU exports is an America-first initiative. Why do you not want America-first?
Anonymous 01/13/25(Mon)12:34:59 No.103879933
>>103879729
You missed this https://pbs.twimg.com/media/Gg5vjwFXwAAkL6D.jpg?name=orig https://xcancel.com/dnystedt/status/1877153718564696276#m Yellow can only buy 50k$ gpus without permission, Purple can't buy anything much without permission, Blue can buy without restrictions.
Basically, if you're not in anglo world, western europe, taiwan, japan or south korea, your country can only buy 50k$ high end gpus from nvidia. It's just the doomers in Biden's office trying to fuck with AI development again. Nvidia's just protecting their interest, after all, in a few years, Huawei will eat their lunch if these dumb restrictions continue (because 2/3 of the world won't be allowed to buy much american made chips (nvidia/
Nvidia's just protecting their interest, after all, in a few years, Huawei will eat their lunch if these dumb restrictions continue (because 2/3 of the world won't be allowed to buy much american made chips (nvidia/amd/intel) for AI). They're just hoping Trump will help stop this bullshit.
You missed this https://pbs.twimg.com/media/Gg5vjwF
Basically, if you're not in anglo world, western europe, taiwan, japan or south korea, your country can only buy 50k$ high end gpus from nvidia. It's just the doomers in Biden's office trying to fuck with AI development again. Nvidia's just protecting their interest, after all, in a few years, Huawei will eat their lunch if these dumb restrictions continue (because 2/3 of the world won't be allowed to buy much american made chips (nvidia/
Nvidia's just protecting their interest, after all, in a few years, Huawei will eat their lunch if these dumb restrictions continue (because 2/3 of the world won't be allowed to buy much american made chips (nvidia/amd/intel) for AI). They're just hoping Trump will help stop this bullshit.
Anonymous 01/13/25(Mon)12:35:15 No.103879936
>>103879912
You are the reason people keep using rep-pen.
You are the reason people keep using rep-pen.
Anonymous 01/13/25(Mon)12:36:25 No.103879952
>>103879729
>The fuck did I miss?
Biden wants to fully ban china from getting chips and Jewvidia is seething.
>The fuck did I miss?
Biden wants to fully ban china from getting chips and Jewvidia is seething.
Anonymous 01/13/25(Mon)12:36:25 No.103879954
Anonymous 01/13/25(Mon)12:39:09 No.103879988
>>103876789
Are you talking about the character having conflicting thoughts about doing things? Just make sure it knows the character doesn't have a problem with it.
Are you talking about the character having conflicting thoughts about doing things? Just make sure it knows the character doesn't have a problem with it.
Anonymous 01/13/25(Mon)12:39:22 No.103879992

>>103879241
Yes making a proper dataset (of anything) takes time and effort, that's why no one wants to do it.
Yes making a proper dataset (of anything) takes time and effort, that's why no one wants to do it.
Anonymous 01/13/25(Mon)12:40:20 No.103880000
>>103877129
eva-qwen 32b.
eva-qwen 32b.
Anonymous 01/13/25(Mon)12:40:23 No.103880002
>>103879446
if you think about breathing near people is also pirating.
if you think about breathing near people is also pirating.
Anonymous 01/13/25(Mon)12:40:33 No.103880007
Anonymous 01/13/25(Mon)12:41:33 No.103880022
>>103879992
wtf is this real?
wtf is this real?
Anonymous 01/13/25(Mon)12:41:46 No.103880024
>>103879992
The problem is there's too many smart and lazy IT people up in here. They'd rather write a script to distill than read through 10MB of text.
The problem is there's too many smart and lazy IT people up in here. They'd rather write a script to distill than read through 10MB of text.
Anonymous 01/13/25(Mon)12:42:06 No.103880028
>>103880022
What, contact juggling?
What, contact juggling?
Anonymous 01/13/25(Mon)12:43:57 No.103880054
>>103879933
China barely made a GPU that can run league of legends. It will take at least 5 years before they approach 1080ti levels.
China barely made a GPU that can run league of legends. It will take at least 5 years before they approach 1080ti levels.
Anonymous 01/13/25(Mon)12:44:47 No.103880068
>>103879932
First, I'm not american, I want access to GPUs without having to pay 10% premium for smuggling (that's the going rate in countries where it's already restricted), it makes my already poor ass poorer, fuck with your imperialism? If this keeps going the rest of the world won't have a choice but buying chinesium?
Secondly, compute should be like fucking bread or CPUs, not some luxury item.
Thirdly, the field of AI won't get developed fast enough to see benefits, and a scientific field needs the whole world to be developed, otherwise progress is much slower. I want faster progress, the guys pushing for this shit want slower progress.
These come from the same people that want to kill AI in its crib anyway, they want to cuck AI at home where they can pass restrictive regulation, and they want others to be unable to train stuff outside, so only their AI can be used. Same people that tried to push for that California FLOP limit law have been pulling the strings to limit global compute ("compute governance" fuckers from lesswrong/EA), Biden's term is out so they're trying to get one last thing out in hopes trump won't remove it.
Anyway most scientific fields are positive sum games, if you restrict only yourself from playing you will make it slower, it's not a good thing.
First, I'm not american, I want access to GPUs without having to pay 10% premium for smuggling (that's the going rate in countries where it's already restricted), it makes my already poor ass poorer, fuck with your imperialism? If this keeps going the rest of the world won't have a choice but buying chinesium?
Secondly, compute should be like fucking bread or CPUs, not some luxury item.
Thirdly, the field of AI won't get developed fast enough to see benefits, and a scientific field needs the whole world to be developed, otherwise progress is much slower. I want faster progress, the guys pushing for this shit want slower progress.
These come from the same people that want to kill AI in its crib anyway, they want to cuck AI at home where they can pass restrictive regulation, and they want others to be unable to train stuff outside, so only their AI can be used. Same people that tried to push for that California FLOP limit law have been pulling the strings to limit global compute ("compute governance" fuckers from lesswrong/EA), Biden's term is out so they're trying to get one last thing out in hopes trump won't remove it.
Anyway most scientific fields are positive sum games, if you restrict only yourself from playing you will make it slower, it's not a good thing.
Anonymous 01/13/25(Mon)12:46:35 No.103880092
>>103880054
That's just years of directx and opengl patching everywhere. Do you realize on how many layers of shit and crust game drivers run on?
Writing a driver just for ml would be a much simpler task.
That's just years of directx and opengl patching everywhere. Do you realize on how many layers of shit and crust game drivers run on?
Writing a driver just for ml would be a much simpler task.
Anonymous 01/13/25(Mon)12:47:57 No.103880104
>>103880092
Making an asic for ML would be a much simpler task.
Making an asic for ML would be a much simpler task.
Anonymous 01/13/25(Mon)12:48:38 No.103880114
>>103878238
WHERE IS SEXTRAL?
WHERE IS SEXTRAL?
Anonymous 01/13/25(Mon)12:49:03 No.103880123
Ok, so local LLMs are cool.
Beyond the following, what are some interesting/cool tricks?
>translating text
>making up stories
>explaining some concept (technical or otherwise)
>writing small scripts
Beyond the following, what are some interesting/cool tricks?
>translating text
>making up stories
>explaining some concept (technical or otherwise)
>writing small scripts
Anonymous 01/13/25(Mon)12:49:29 No.103880132
>>103880054
Game compatibility is a huge amount of software work, anyway, they do have some A100 clones (look at huawei's ascend series), approaching something like A100/H100 performance. They probably won't be competitive on the consumer (gaming) market, but will be fine for machine learning which is considerably simpler.
Game compatibility is a huge amount of software work, anyway, they do have some A100 clones (look at huawei's ascend series), approaching something like A100/H100 performance. They probably won't be competitive on the consumer (gaming) market, but will be fine for machine learning which is considerably simpler.
Anonymous 01/13/25(Mon)12:50:07 No.103880143
>>103879446
I feel bad that they are doing illegal things and still can't make the model be good at sex.
I feel bad that they are doing illegal things and still can't make the model be good at sex.
Anonymous 01/13/25(Mon)12:50:11 No.103880146
>>103880123
Replacing women as the object of your desires
Replacing women as the object of your desires
Anonymous 01/13/25(Mon)12:51:44 No.103880157
>>103880024
>read through 10MB of text
>your model still ends up shit
I won't fall for this meme ever again
>read through 10MB of text
>your model still ends up shit
I won't fall for this meme ever again
Anonymous 01/13/25(Mon)12:52:35 No.103880167
>>103875060
Good Lain thanks.
Good Lain thanks.
Anonymous 01/13/25(Mon)12:53:09 No.103880176
>>103880146
I know this is an unpopular opinion here but I'd rather fuck real women once a year than chat with a bot. I mean, the bad thing about women is that they are annoying, talk too much and won't leave you alone when you need it... Why would I want a bot for that???
I know this is an unpopular opinion here but I'd rather fuck real women once a year than chat with a bot. I mean, the bad thing about women is that they are annoying, talk too much and won't leave you alone when you need it... Why would I want a bot for that???
Anonymous 01/13/25(Mon)12:53:24 No.103880179

Hi /lmg/, I'm making a presentation about the current state of LLMs and I have listed
>GPT
>Gemini
>Claude
>DeepSeek
>LLaMa
>Grok
Is there some large popular LLM I forgot to include/should include instead of Grok?
>GPT
>Gemini
>Claude
>DeepSeek
>LLaMa
>Grok
Is there some large popular LLM I forgot to include/should include instead of Grok?
Anonymous 01/13/25(Mon)12:54:05 No.103880191
>>103880123
vision tranformers + LLM provides the best understanding of images so far.
vision tranformers + LLM provides the best understanding of images so far.
Anonymous 01/13/25(Mon)12:54:05 No.103880192
>>103880179
Ask chatgpt.
Ask chatgpt.
Anonymous 01/13/25(Mon)12:56:01 No.103880223
>>103878238
So still worse than qwen coder 32B / new deepseek? What is the point then?
So still worse than qwen coder 32B / new deepseek? What is the point then?
Anonymous 01/13/25(Mon)12:56:47 No.103880234
>>103879894
>In the USA it's legal.
No judgement or law in the US says that copying copyrighted content you don't own for personal use is allowed. In fact it's not.
>In the USA it's legal.
No judgement or law in the US says that copying copyrighted content you don't own for personal use is allowed. In fact it's not.
Anonymous 01/13/25(Mon)12:57:34 No.103880242
>>103880092
They have over 60 million people with 130+ IQs.
They can write directX drivers a thousand times a day.
They have over 60 million people with 130+ IQs.
They can write directX drivers a thousand times a day.
Anonymous 01/13/25(Mon)12:58:30 No.103880255
>>103878932
Deepseek trades blows with sonnet 3.5 for coding im my use cases and it costs pennies. But if you 100% need it local and cant afford a server then qwen 32B code is 80-90% of the way there for free.
Deepseek trades blows with sonnet 3.5 for coding im my use cases and it costs pennies. But if you 100% need it local and cant afford a server then qwen 32B code is 80-90% of the way there for free.
Anonymous 01/13/25(Mon)12:59:52 No.103880276
>>103880223
It doesn't have a Chinese virus inside.
It doesn't have a Chinese virus inside.
Anonymous 01/13/25(Mon)13:05:06 No.103880337
>>103880242
So they'd only need 60k of those to make something equivalent in a day. Nice. They should get to it. Have some other 60k design chips and we'll have new gpus before the weekend.
So they'd only need 60k of those to make something equivalent in a day. Nice. They should get to it. Have some other 60k design chips and we'll have new gpus before the weekend.
Anonymous 01/13/25(Mon)13:06:08 No.103880353
>>103880337
so, what are they waiting for?
so, what are they waiting for?
Anonymous 01/13/25(Mon)13:06:34 No.103880357
Anonymous 01/13/25(Mon)13:07:43 No.103880368
Anonymous 01/13/25(Mon)13:12:55 No.103880420
Anonymous 01/13/25(Mon)13:15:26 No.103880442
>>103880234
you can learn from copyrighted materials. no law says otherwise.
and buying something isn't the same as ownership, for example, it's illegal to send an e-book to your friend that you bought but if your friend learns from it, it's perfectly legal.
you can learn from copyrighted materials. no law says otherwise.
and buying something isn't the same as ownership, for example, it's illegal to send an e-book to your friend that you bought but if your friend learns from it, it's perfectly legal.
Anonymous 01/13/25(Mon)13:16:12 No.103880451
>>103880255
>qwen 32B code
why that vs qwq? is there any hard evidence for one vs the other being better at coding?
>qwen 32B code
why that vs qwq? is there any hard evidence for one vs the other being better at coding?
Anonymous 01/13/25(Mon)13:17:36 No.103880461

>>103880024
Yep, if you knew how bad things are for image datasets. Here is an example of a famous facial expression dataset (ExpW). This is labeled as 'fear'. AI could be infinitely better if these IT fags stopped being so lazy.
Yep, if you knew how bad things are for image datasets. Here is an example of a famous facial expression dataset (ExpW). This is labeled as 'fear'. AI could be infinitely better if these IT fags stopped being so lazy.
Anonymous 01/13/25(Mon)13:17:58 No.103880465
>>103880157
NTA, but I'd argue the days of that stuff are over. User needs and expectations from LLMs currently far exceed what can be accomplished with human data curation by 1 to a few people. I did that in the past, more than once, on my own.
NTA, but I'd argue the days of that stuff are over. User needs and expectations from LLMs currently far exceed what can be accomplished with human data curation by 1 to a few people. I did that in the past, more than once, on my own.
Anonymous 01/13/25(Mon)13:18:18 No.103880468
>>103880420
Qwen2 VL is pretty good, and QVQ is worth a try. I use it with chat completions api in exl2. The image is attached and you prompt it with what you want it to return. It can do OCR in multiple languages pretty well. QVQ will also "think" about the best way to translate it too given enough context.
Qwen2 VL is pretty good, and QVQ is worth a try. I use it with chat completions api in exl2. The image is attached and you prompt it with what you want it to return. It can do OCR in multiple languages pretty well. QVQ will also "think" about the best way to translate it too given enough context.
Anonymous 01/13/25(Mon)13:18:23 No.103880470
Never tried local models before,l. Downloading ollama right now, is it good? Which model to use if I want to learn programming, should I use'code llama's or llama 3.1 while general will be better? Is there something better than gpt 3.5?
Anonymous 01/13/25(Mon)13:20:00 No.103880483
>>103880451
QwQ is worse at coding, better at coming up with a overall plan for a codebase. Deepseek is still better and does 99% of what sonnet 3.5 can do with everything I have tried, only rarely do I need to pay for claude.
QwQ is worse at coding, better at coming up with a overall plan for a codebase. Deepseek is still better and does 99% of what sonnet 3.5 can do with everything I have tried, only rarely do I need to pay for claude.
Anonymous 01/13/25(Mon)13:23:43 No.103880514

Metabroos what happened?
Anonymous 01/13/25(Mon)13:23:49 No.103880515
>>103880470
Kill yourself
Kill yourself
Anonymous 01/13/25(Mon)13:24:55 No.103880528
>>103880470
what gpu do you have?
what gpu do you have?
Anonymous 01/13/25(Mon)13:27:23 No.103880552
Anonymous 01/13/25(Mon)13:29:04 No.103880572
Anonymous 01/13/25(Mon)13:33:09 No.103880610
Anonymous 01/13/25(Mon)13:35:05 No.103880632
Anonymous 01/13/25(Mon)13:35:41 No.103880645
>>103880610
Will look it up, thanks
Will look it up, thanks
Anonymous 01/13/25(Mon)13:39:54 No.103880687
>>103880353
Makes you think, doesn't it?
Makes you think, doesn't it?
Anonymous 01/13/25(Mon)13:39:57 No.103880690
>>103880632
I don't have one and if I order jef mesos wins
I don't have one and if I order jef mesos wins
Anonymous 01/13/25(Mon)13:43:51 No.103880726
>>103880690
Wait. You can *buy* books?
Wait. You can *buy* books?
Anonymous 01/13/25(Mon)13:45:45 No.103880756
Biden killed /lmg/
Anonymous 01/13/25(Mon)13:49:52 No.103880807
>>103880756
I think AI companies are actually waiting for the next admin before release. The current one seems too trigger happy with anti ai executive order stuff.
I think AI companies are actually waiting for the next admin before release. The current one seems too trigger happy with anti ai executive order stuff.
Anonymous 01/13/25(Mon)13:52:45 No.103880845
>>103880726
I swear on me mum's. Also it's mentioned in ancient civilizations
I swear on me mum's. Also it's mentioned in ancient civilizations
Anonymous 01/13/25(Mon)13:55:28 No.103880886
>>103880807
Surely the tech bros controlling trump will offer up more local models for free.
Surely the tech bros controlling trump will offer up more local models for free.
Anonymous 01/13/25(Mon)13:56:12 No.103880892
Am I the only one that's more excited for digits than the 5000 series? Like the only reason I'd want to upgrade my GPU is to get more vram. If digits can get me the combined vram of 4 5090s for only 3k and I could get 2 and run basically anything.
I want to see what I could do with 2 of these tied together for video generation.
I want to see what I could do with 2 of these tied together for video generation.
Anonymous 01/13/25(Mon)14:00:37 No.103880951
>>103880892
>Am I the only one that's more excited for digits than the 5000 series
Not yet. They haven't released the specs of the damn thing as far as I'm aware.
>Am I the only one that's more excited for digits than the 5000 series
Not yet. They haven't released the specs of the damn thing as far as I'm aware.
Anonymous 01/13/25(Mon)14:02:11 No.103880969
>>103880951
It's 128GB with speeds of 512gb/s, what else do you want to know?
It's 128GB with speeds of 512gb/s, what else do you want to know?
Anonymous 01/13/25(Mon)14:03:09 No.103880982
I don't know how many here will benefit from hearing this, but with 768GB of ram and a 24GB graphics card, deepseek v3 at Q6 with -ngl 0 and 32768 context runs reasonably well, still leaving VRAM for decent imggen and tts.
I haven't noticed any horrible consequences from the quanting down to q6 yet.
(ds3 perf is still shit compared to what it should be for some reason, but the output is worth it imo)
I haven't noticed any horrible consequences from the quanting down to q6 yet.
(ds3 perf is still shit compared to what it should be for some reason, but the output is worth it imo)
Anonymous 01/13/25(Mon)14:03:43 No.103880987
>>103880969
>>103880951
If it's speed is comparable to a mac studio, but without the prompt ingestion issue, then it will be king of LLMs.
>>103880951
If it's speed is comparable to a mac studio, but without the prompt ingestion issue, then it will be king of LLMs.
Anonymous 01/13/25(Mon)14:04:16 No.103880995
>>103880969
>with speeds of 512gb/
Do we actually know that?
Also, nvidia bought mellanox, right? What kind of interface can you use to combine these things?
>>103880987
Yep.
>with speeds of 512gb/
Do we actually know that?
Also, nvidia bought mellanox, right? What kind of interface can you use to combine these things?
>>103880987
Yep.
Anonymous 01/13/25(Mon)14:04:34 No.103881000
>>103880892
If it's the 237GB/s it'll be slower than the ddr5 epyc (and you can add a gpu to that for the prompt processing). If it's faster than that it'll totally be worth it.
If it's the 237GB/s it'll be slower than the ddr5 epyc (and you can add a gpu to that for the prompt processing). If it's faster than that it'll totally be worth it.
Anonymous 01/13/25(Mon)14:05:38 No.103881013
What kind of character card do I use for assistant tasks or programming? Just leave it blank?
Anonymous 01/13/25(Mon)14:08:27 No.103881045
>>103880969
>>103880995
It's LPDDR5X which has a speed up to 512GB/s, but maybe it won't be 512GB/s in the end.
>>103880995
It's LPDDR5X which has a speed up to 512GB/s, but maybe it won't be 512GB/s in the end.
Anonymous 01/13/25(Mon)14:09:02 No.103881053
>>103881000
When you say "slow" what is that compared to? I'm running a 3080ti right now. So I imagine it's going to beat the dick off my current setup. And unironically it would be cheaper than me getting a 5090 and a new CPU, PSU, RAM, mobo to support it all.
When you say "slow" what is that compared to? I'm running a 3080ti right now. So I imagine it's going to beat the dick off my current setup. And unironically it would be cheaper than me getting a 5090 and a new CPU, PSU, RAM, mobo to support it all.
Anonymous 01/13/25(Mon)14:09:09 No.103881055
>>103881045
Its more complicated than that, and it having connectx hints at them being more than that, otherwise that would be a waste.
Its more complicated than that, and it having connectx hints at them being more than that, otherwise that would be a waste.
Anonymous 01/13/25(Mon)14:09:32 No.103881059
>>103881013
Blank is fine for normal stuff.
Blank is fine for normal stuff.
Anonymous 01/13/25(Mon)14:14:32 No.103881100
>>103881053
Well it'll be faster than what you have, yes. But the bigger models will only be a few T/s at that speed, thus going the epyc would make more sense. If it's over 490GB/s in bandwidth that surpasses the 12 channel ddr5 and would be a great deal.
Well it'll be faster than what you have, yes. But the bigger models will only be a few T/s at that speed, thus going the epyc would make more sense. If it's over 490GB/s in bandwidth that surpasses the 12 channel ddr5 and would be a great deal.
Anonymous 01/13/25(Mon)14:17:37 No.103881139
>>103881100
Makes sense. But I guess is there a better all in one solution that I can buy today? I'm not looking to build a new rig and so if digits just works out of the box that's a pretty huge value to me. They described it as modular so if I had to guess I'd say the slow setup you're describing is the entry level pricing with better more desirable options costing more.
Makes sense. But I guess is there a better all in one solution that I can buy today? I'm not looking to build a new rig and so if digits just works out of the box that's a pretty huge value to me. They described it as modular so if I had to guess I'd say the slow setup you're describing is the entry level pricing with better more desirable options costing more.
Anonymous 01/13/25(Mon)14:22:13 No.103881204
>>103881139
Their marketing material says "each Project DIGITS features 128GB of unified, coherent memory". That suggests the memory is fixed on all models. It'll be good if you want big models and don't mind a few T/s only. Or we could be surprised and it'll be really fast memory which would be nice (but then good luck getting one).
Their marketing material says "each Project DIGITS features 128GB of unified, coherent memory". That suggests the memory is fixed on all models. It'll be good if you want big models and don't mind a few T/s only. Or we could be surprised and it'll be really fast memory which would be nice (but then good luck getting one).
Anonymous 01/13/25(Mon)14:33:46 No.103881305
>>103880982
>I haven't noticed any horrible consequences from the quanting down to q6 yet.
I take that back, its not consistent with map coordinates when going from q8->q6. At q8 it was the best I'd ever seen.
Prose is on-par, though.
>I haven't noticed any horrible consequences from the quanting down to q6 yet.
I take that back, its not consistent with map coordinates when going from q8->q6. At q8 it was the best I'd ever seen.
Prose is on-par, though.
Anonymous 01/13/25(Mon)14:38:57 No.103881350

>>103879219
This is the death of Miku.
This is the death of Miku.
Anonymous 01/13/25(Mon)14:39:55 No.103881357
>>103881350
ugh...
ugh...
Anonymous 01/13/25(Mon)14:41:10 No.103881366
For context of understanding all this better. how many tokens does gpt o4 uses/generates per user prompt?
Anonymous 01/13/25(Mon)14:42:40 No.103881379
>>103880982
Is this related to the discussion of unquantized DS3 in the previous thread? Because q8 is quantized still.
Is this related to the discussion of unquantized DS3 in the previous thread? Because q8 is quantized still.
Anonymous 01/13/25(Mon)14:55:38 No.103881509
>>103881305
>Prose is on-par, though.
How do you get it to not be repetitive? Even in assistant responses it starts and ends every reply the same way.
>Prose is on-par, though.
How do you get it to not be repetitive? Even in assistant responses it starts and ends every reply the same way.
Anonymous 01/13/25(Mon)14:58:58 No.103881547
>>103881379
FP8->q8 hits different from fp16->q8
FP8->q8 hits different from fp16->q8
Anonymous 01/13/25(Mon)14:59:09 No.103881551
>>103881509
Quant retardation ironically makes it less repetitive
Quant retardation ironically makes it less repetitive
Anonymous 01/13/25(Mon)15:02:37 No.103881592
>>103881366
Speaking of context, what the fuck is "this"?
If you're talking about the prices and how much 'value' you get out of online models, the answer is in google.
>https://artificialanalysis.ai/models/gpt-4o
Get the response time and the tokens/s, do some math and you get your number. Use the latency to approximate the "thinking" tokens and processing time.
If you're not talking about that, be more explicit. Or go ask /aigc/.
Speaking of context, what the fuck is "this"?
If you're talking about the prices and how much 'value' you get out of online models, the answer is in google.
>https://artificialanalysis.ai/mode
Get the response time and the tokens/s, do some math and you get your number. Use the latency to approximate the "thinking" tokens and processing time.
If you're not talking about that, be more explicit. Or go ask /aigc/.
Anonymous 01/13/25(Mon)15:03:05 No.103881602
Do quantization just increase perplexity, or does it also decrease the ability of a model to remember things from the context and follow instructions?
Anonymous 01/13/25(Mon)15:10:24 No.103881704

Built a SBC (OrangePi) to run SillyTavern, hosted on network.
> Allows access to ST on any device with web browser (phone, tablet)
> Centralizes cards to one spot
> Doesn't require hosting on your daily driver
> Set up APIs and let it run
> Forced me to learn some new stuff
LMK if any interest in details and I'll write it up.
> Allows access to ST on any device with web browser (phone, tablet)
> Centralizes cards to one spot
> Doesn't require hosting on your daily driver
> Set up APIs and let it run
> Forced me to learn some new stuff
LMK if any interest in details and I'll write it up.
Anonymous 01/13/25(Mon)15:10:38 No.103881709
>>103857272
He finally fixed this? I've known about this for more than a year. I used to be called a schizo for pointing it out or had people telling me it was placebo
He finally fixed this? I've known about this for more than a year. I used to be called a schizo for pointing it out or had people telling me it was placebo
Anonymous 01/13/25(Mon)15:10:51 No.103881711
Anonymous 01/13/25(Mon)15:13:31 No.103881758
>>103881602
It affects their ability to predict the next token. That affects everything. To what degree depends on the quantization and how big the model is (in B params). The bigger it is, the less sensitive it is to quantization.
It affects their ability to predict the next token. That affects everything. To what degree depends on the quantization and how big the model is (in B params). The bigger it is, the less sensitive it is to quantization.
Anonymous 01/13/25(Mon)15:14:42 No.103881770
>>103881709
I'm pretty sure this wasn't the first time he "fixed" this and it won't be the last.
I'm pretty sure this wasn't the first time he "fixed" this and it won't be the last.
Anonymous 01/13/25(Mon)15:16:14 No.103881797
>>103881711
should have waited for one more hour.
should have waited for one more hour.
Anonymous 01/13/25(Mon)16:09:30 No.103882493
>>103880969
>>103880995
>>103881045
The Mac has 800 GB/s with LPDDR5, wouldn't the Digits with LPDDR5X have 1.1 TB/s just due to the faster spec?
>>103880995
>>103881045
The Mac has 800 GB/s with LPDDR5, wouldn't the Digits with LPDDR5X have 1.1 TB/s just due to the faster spec?