/lmg/ - Local Models General
Anonymous 01/20/25(Mon)08:18:15 | 461 comments | 49 images | 🔒 Locked

/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>103959928 & >>103947482
►News
>(01/20) DeepSeek releases R1, R1 Zero, & finetuned Qwen and Llama models: https://hf.co/deepseek-ai/DeepSeek-R1-Zero
>(01/17) Nvidia AceInstruct, finetuned on Qwen2.5-Base: https://hf.co/nvidia/AceInstruct-72B
>(01/16) OuteTTS-0.3 released with voice cloning & punctuation support: https://hf.co/collections/OuteAI/outetts-03-6786b1ebc7aeb757bc17a2fa
>(01/15) InternLM3-8B-Instruct released with deep thinking capability: https://hf.co/internlm/internlm3-8b-instruct
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/tldrhowtoquant
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/leaderboard.html
Code Editing: https://aider.chat/docs/leaderboards
Context Length: https://github.com/hsiehjackson/RULER
Japanese: https://hf.co/datasets/lmg-anon/vntl-leaderboard
Censorbench: https://codeberg.org/jts2323/censorbench
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
Previous threads: >>103959928 & >>103947482
►News
>(01/20) DeepSeek releases R1, R1 Zero, & finetuned Qwen and Llama models: https://hf.co/deepseek-ai/DeepSeek-
>(01/17) Nvidia AceInstruct, finetuned on Qwen2.5-Base: https://hf.co/nvidia/AceInstruct-72
>(01/16) OuteTTS-0.3 released with voice cloning & punctuation support: https://hf.co/collections/OuteAI/ou
>(01/15) InternLM3-8B-Instruct released with deep thinking capability: https://hf.co/internlm/internlm3-8b
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWeb
https://rentry.org/tldrhowtoquant
►Further Learning
https://rentry.org/machine-learning
https://rentry.org/llm-training
https://rentry.org/LocalModelsPaper
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/lea
Code Editing: https://aider.chat/docs/leaderboard
Context Length: https://github.com/hsiehjackson/RUL
Japanese: https://hf.co/datasets/lmg-anon/vnt
Censorbench: https://codeberg.org/jts2323/censor
GPUs: https://github.com/XiongjieDai/GPU-
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngl
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-M
Sampler Visualizer: https://artefact2.github.io/llm-sam
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-g
https://github.com/LostRuins/kobold
https://github.com/ggerganov/llama.
https://github.com/theroyallab/tabb
https://github.com/vllm-project/vll
Anonymous 01/20/25(Mon)08:18:36 No.103967200

►Recent Highlights from the Previous Thread: >>103959928
--DeepSeek-R1 distilled model benchmarks:
>103966823 >103966829 >103966837 >103966856 >103966868 >103966902
--DeepSeek-R1-Zero model size and optimization discussion:
>103964568 >103964620 >103964602 >103964658 >103964594 >103964653 >103964711 >103964748 >103964760 >103964753 >103964762
--LLMs, reasoning, and logic discussion:
>103961362 >103961401 >103961819 >103961891 >103962146 >103962605 >103961900 >103961490 >103961513 >103961549
--DeepSeek R1 release and AGI discussion:
>103964074 >103964138 >103964150 >103964217 >103964274 >103964423 >103964432 >103964314 >103964319 >103964332 >103964344 >103964357 >103964368 >103964395 >103964389 >103964152
--Using system RAM for chatbot models and performance limitations:
>103962830 >103962848 >103962871 >103962956 >103962937 >103962971 >103962990 >103963031 >103963009
--R1-lite-preview performance discussion and comparison to QwQ:
>103964089 >103964178 >103964182 >103964188 >103965765 >103964213
--Discussion on DeepSeek model relationships and sizes:
>103965685 >103965737 >103965774 >103965794 >103965854 >103966020 >103966042
--OpenAI's "super-agents" announced, anons skeptical:
>103961699 >103961878 >103962728 >103962741 >103962778
--Anon discusses sentiment analysis with LLMs, says its nothing new:
>103961655 >103961669 >103961743 >103961911 >103962020
--Discussion on potential AI ban and its implications:
>103964655 >103964662 >103964686 >103964687
--DeepSeek-V3 development and improvements over V3:
>103964452 >103964470 >103964480
--Anon shares DeepSeek-R1-Zero and 600B+ DeepSeek-R1 model:
>103964519 >103964622 >103964625 >103964628
--Logs: R1:
>103966457 >103966602 >103966684
--Miku (free space):
>103960864 >103962504 >103964528 >103965178
►Recent Highlight Posts from the Previous Thread: >>103959933
Why?: 9 reply limit >>102478518
Fix: https://rentry.org/lmg-recap-script
--DeepSeek-R1 distilled model benchmarks:
>103966823 >103966829 >103966837 >103966856 >103966868 >103966902
--DeepSeek-R1-Zero model size and optimization discussion:
>103964568 >103964620 >103964602 >103964658 >103964594 >103964653 >103964711 >103964748 >103964760 >103964753 >103964762
--LLMs, reasoning, and logic discussion:
>103961362 >103961401 >103961819 >103961891 >103962146 >103962605 >103961900 >103961490 >103961513 >103961549
--DeepSeek R1 release and AGI discussion:
>103964074 >103964138 >103964150 >103964217 >103964274 >103964423 >103964432 >103964314 >103964319 >103964332 >103964344 >103964357 >103964368 >103964395 >103964389 >103964152
--Using system RAM for chatbot models and performance limitations:
>103962830 >103962848 >103962871 >103962956 >103962937 >103962971 >103962990 >103963031 >103963009
--R1-lite-preview performance discussion and comparison to QwQ:
>103964089 >103964178 >103964182 >103964188 >103965765 >103964213
--Discussion on DeepSeek model relationships and sizes:
>103965685 >103965737 >103965774 >103965794 >103965854 >103966020 >103966042
--OpenAI's "super-agents" announced, anons skeptical:
>103961699 >103961878 >103962728 >103962741 >103962778
--Anon discusses sentiment analysis with LLMs, says its nothing new:
>103961655 >103961669 >103961743 >103961911 >103962020
--Discussion on potential AI ban and its implications:
>103964655 >103964662 >103964686 >103964687
--DeepSeek-V3 development and improvements over V3:
>103964452 >103964470 >103964480
--Anon shares DeepSeek-R1-Zero and 600B+ DeepSeek-R1 model:
>103964519 >103964622 >103964625 >103964628
--Logs: R1:
>103966457 >103966602 >103966684
--Miku (free space):
>103960864 >103962504 >103964528 >103965178
►Recent Highlight Posts from the Previous Thread: >>103959933
Why?: 9 reply limit >>102478518
Fix: https://rentry.org/lmg-recap-script
Anonymous 01/20/25(Mon)08:21:31 No.103967221
>>103967183
Don't know what kind but there's some writing in there.
Don't know what kind but there's some writing in there.
Anonymous 01/20/25(Mon)08:22:24 No.103967228
>>103967217
Hope thats the case. Finally something fresh sub 40b. It was getting stale.
Hope thats the case. Finally something fresh sub 40b. It was getting stale.
Anonymous 01/20/25(Mon)08:23:12 No.103967238
R1 will be 2x the price of V3 it looks like. If they really did fix its issues though then it will be worth it
Anonymous 01/20/25(Mon)08:23:39 No.103967240
>>103967221
huh, well gotta wait and see. i was really suprised my v3. i couldnt stand the other chink models because of the slop and dryness. i suspect they train it on rp.
huh, well gotta wait and see. i was really suprised my v3. i couldnt stand the other chink models because of the slop and dryness. i suspect they train it on rp.
Anonymous 01/20/25(Mon)08:25:17 No.103967251
>>103967238
Same price for cache hits as V3 though it seems, so will be pretty cheap still it looks like
Same price for cache hits as V3 though it seems, so will be pretty cheap still it looks like
Anonymous 01/20/25(Mon)08:27:35 No.103967266
Looks like it might already be up
https://api-docs.deepseek.com/guides/reasoning_model
https://api-docs.deepseek.com/api/create-chat-completion
https://api-docs.deepseek.com/guide
https://api-docs.deepseek.com/api/c
Anonymous 01/20/25(Mon)08:28:04 No.103967271
>>103967228
I'm tempted to still go with the 70B just because my current daily driver is an L3.3 tune, but either way, this does look like the next big thing in localland.
I'm tempted to still go with the 70B just because my current daily driver is an L3.3 tune, but either way, this does look like the next big thing in localland.
Anonymous 01/20/25(Mon)08:28:36 No.103967275
>>103967266
it is
it is
Anonymous 01/20/25(Mon)08:29:12 No.103967280
>>103967240
I'm confident there's RP in the Llama3 SFT data too, they're just not advertising it.
I'm confident there's RP in the Llama3 SFT data too, they're just not advertising it.
Anonymous 01/20/25(Mon)08:30:14 No.103967291
R1 is MIT licensed
Anonymous 01/20/25(Mon)08:30:24 No.103967292
Wish we would have gotten a deepseek distill to nemo or mistral-small.
Anonymous 01/20/25(Mon)08:30:37 No.103967295
>>103967291
lmfao
lmfao
Anonymous 01/20/25(Mon)08:30:46 No.103967297
How do I make R1 work with sillytavern?
Anonymous 01/20/25(Mon)08:31:13 No.103967301
>>103967292
The Qwen distill will have you eating well, brother
The Qwen distill will have you eating well, brother
Anonymous 01/20/25(Mon)08:32:50 No.103967317
>>103967301
I hope so, qwen is really dry but I'm open to kneeling deeply.
I hope so, qwen is really dry but I'm open to kneeling deeply.
Anonymous 01/20/25(Mon)08:36:46 No.103967338
>reasoner is super horny in a good way. I had to tune my preset way down
aicg complaining that its too horny. these fucking chinks man.
aicg complaining that its too horny. these fucking chinks man.
Anonymous 01/20/25(Mon)08:37:41 No.103967349
You know what would have been interesting to see? If they had trained the a distil on top of qwen with linear attention.
I wonder if a full fine tune wit ha couple billion tokens could make that perform better.
Regardless, now we just need a release with true 1m context early in the year and 2025 will be off to an amazing fucking start.
I wonder if a full fine tune wit ha couple billion tokens could make that perform better.
Regardless, now we just need a release with true 1m context early in the year and 2025 will be off to an amazing fucking start.
Anonymous 01/20/25(Mon)08:38:45 No.103967357
>>103967338
For those that want a character to be more than a fuckdoll, a model being too horny is a valid issue though.
For those that want a character to be more than a fuckdoll, a model being too horny is a valid issue though.
Anonymous 01/20/25(Mon)08:39:27 No.103967365
>>103967349
>now we just need a release with true 1m context
Isn't MiniMax exactly that? It seemed to hold up really well in the needle in a haystack tests up to 1m
>now we just need a release with true 1m context
Isn't MiniMax exactly that? It seemed to hold up really well in the needle in a haystack tests up to 1m
Anonymous 01/20/25(Mon)08:40:15 No.103967377
>>103967365
I assume he was talking about local models
I assume he was talking about local models
Anonymous 01/20/25(Mon)08:40:19 No.103967378
>>103967349
>Regardless, now we just need a release with true 1m context early in the year and 2025 will be off to an amazing fucking start.
https://huggingface.co/MiniMaxAI/MiniMax-Text-01
>Regardless, now we just need a release with true 1m context early in the year and 2025 will be off to an amazing fucking start.
https://huggingface.co/MiniMaxAI/Mi
Anonymous 01/20/25(Mon)08:41:44 No.103967385
>>103967365
>>103967378
Oh yeah, I forgot about that since I'm stuck with smaller models.
Then yeah, fucking shit, 2025 is already shaping up to be a great fucking year for LMG.
Sick as hell.
>>103967378
Oh yeah, I forgot about that since I'm stuck with smaller models.
Then yeah, fucking shit, 2025 is already shaping up to be a great fucking year for LMG.
Sick as hell.
Anonymous 01/20/25(Mon)08:42:00 No.103967387
>>103967377
Anon...
Anon...
Anonymous 01/20/25(Mon)08:43:06 No.103967396
>>103967357
yes, ideally a model that can sniff out what you want even without a explicit prompt.
but chink models needed to be guided by hand pretty forcefully to get them into a direction you want. not just sexually.
yes, ideally a model that can sniff out what you want even without a explicit prompt.
but chink models needed to be guided by hand pretty forcefully to get them into a direction you want. not just sexually.
Anonymous 01/20/25(Mon)08:44:40 No.103967410
So which one was the horny model?
Anonymous 01/20/25(Mon)08:45:48 No.103967430
Anonymous 01/20/25(Mon)08:46:50 No.103967442
>>103967238
They're increasing the price too much.
They're increasing the price too much.
Anonymous 01/20/25(Mon)08:46:53 No.103967443
wheres that bingo card ? dident it have something about beating o1 ? that can be crossed off too now
Anonymous 01/20/25(Mon)08:49:06 No.103967462
>>103967442
For hardcore usage on code ive spent $2 for 30M this month. It would have been like, what? Cache hits are the same so like $5?
For hardcore usage on code ive spent $2 for 30M this month. It would have been like, what? Cache hits are the same so like $5?
Anonymous 01/20/25(Mon)08:50:15 No.103967470
>>103967430
Now let's hope the distilled models aren't too sensitive to quantization.
Now let's hope the distilled models aren't too sensitive to quantization.
Anonymous 01/20/25(Mon)08:50:18 No.103967471
>To equip more efficient smaller models with reasoning capabilities like DeekSeek-R1, we directly fine-tuned open-source models like Qwen (Qwen, 2024b) and Llama (AI@Meta, 2024) using the 800k samples curated with DeepSeek-R1, as detailed in §2.3.3. Our findings indicate that this straightforward distillation method significantly enhances the reasoning abilities of smaller models.
>
>...
>
>For distilled models, we apply only SFT and do not include an RL stage, even though incorporating RL could substantially boost model performance. Our primary goal here is to demonstrate the effectiveness of the distillation technique, leaving the exploration of the RL stage to the broader research community.
The distilled models are half-assed, it's over before it even begun...
>
>...
>
>For distilled models, we apply only SFT and do not include an RL stage, even though incorporating RL could substantially boost model performance. Our primary goal here is to demonstrate the effectiveness of the distillation technique, leaving the exploration of the RL stage to the broader research community.
The distilled models are half-assed, it's over before it even begun...
Anonymous 01/20/25(Mon)08:51:08 No.103967479
Just gotta buy 3x digits to run R1 now lol.
Anonymous 01/20/25(Mon)08:51:58 No.103967486
>>103967479
the more you buy...
the more you buy...
Anonymous 01/20/25(Mon)08:52:02 No.103967487
>>103967471
>leaving the exploration of the RL stage to the broader research community.
So never gonna happen
>leaving the exploration of the RL stage to the broader research community.
So never gonna happen
Anonymous 01/20/25(Mon)08:53:04 No.103967501
Anonymous 01/20/25(Mon)08:53:19 No.103967505
How about you just do the thinking inside the model instead of using token salad?
Anonymous 01/20/25(Mon)08:54:16 No.103967509
>>103967505
Llama 4 Coconut is coming next month
Llama 4 Coconut is coming next month
Anonymous 01/20/25(Mon)08:54:25 No.103967512
>>103967505
that would require competence
that would require competence
Anonymous 01/20/25(Mon)08:55:01 No.103967517

>>103967140
It follows the CoT very well.
R1-Lite-Preview started rambling and confusing perspective after 1-2 turns. Full R1 stays stable with each turn.
It follows the CoT very well.
R1-Lite-Preview started rambling and confusing perspective after 1-2 turns. Full R1 stays stable with each turn.
Anonymous 01/20/25(Mon)08:56:52 No.103967524
>>103967505
so you'd rather have a black box cot where you don't see anything for however long it thinks and can't stop it mid-way if it goes retarded or starts looping?
so you'd rather have a black box cot where you don't see anything for however long it thinks and can't stop it mid-way if it goes retarded or starts looping?
Anonymous 01/20/25(Mon)08:58:08 No.103967537
>>103967517
that is really good. very impressive stuff.
thanks anon. first time i see llm thinking that doesn't feel like rambling. very cool.
that is really good. very impressive stuff.
thanks anon. first time i see llm thinking that doesn't feel like rambling. very cool.
Anonymous 01/20/25(Mon)08:58:11 No.103967538
Anonymous 01/20/25(Mon)08:58:43 No.103967543
>>103967479
Oh unfortunately you have to wait for Digits 2 EOY to be able to chain 3 together after registering, going through the KYC checks and paying for a subscription.
(+ $20 a month to enable R rated content generation)
Oh unfortunately you have to wait for Digits 2 EOY to be able to chain 3 together after registering, going through the KYC checks and paying for a subscription.
(+ $20 a month to enable R rated content generation)
Anonymous 01/20/25(Mon)08:59:04 No.103967545

Temp might be a bit high but soul...
Anonymous 01/20/25(Mon)08:59:23 No.103967548
gotta say a distill into llama and qwen was not expected and is by far the most interesting part of this to me
they used 3.3 too for the 70b and it appears to be like 90-95% of the capabilities of full r1 and I can actually run this shit locally at a high quant
they used 3.3 too for the 70b and it appears to be like 90-95% of the capabilities of full r1 and I can actually run this shit locally at a high quant
Anonymous 01/20/25(Mon)09:00:04 No.103967555
>>103967545
Also I'm using a story format so before someone says the inevitable "its talking for you" that is on purpose.
Also I'm using a story format so before someone says the inevitable "its talking for you" that is on purpose.
Anonymous 01/20/25(Mon)09:00:05 No.103967556
deepseek-reasoner over API seems to like to not use CoT for political questions, even in other languages or when they're not related to China.
Anonymous 01/20/25(Mon)09:00:19 No.103967558
>>103967538
2 more months
2 more months
Anonymous 01/20/25(Mon)09:00:31 No.103967559
how's sex with the 32b r1?
Anonymous 01/20/25(Mon)09:01:39 No.103967566
>>103967548
Yeah, stroke of genius if they want to ear the graces of the enthusiast hobbyist that might have a 4090 or the like.
Yeah, stroke of genius if they want to ear the graces of the enthusiast hobbyist that might have a 4090 or the like.
Anonymous 01/20/25(Mon)09:01:51 No.103967568
>>103967548
I was dooming when I saw the size of R1 but with the distills I'm now hmming.
I was dooming when I saw the size of R1 but with the distills I'm now hmming.
Anonymous 01/20/25(Mon)09:02:23 No.103967574
>>103967524
I would assume if internal thinking becomes the norm, tools would be developed to help visualize the internal state, or at least generate intermediary tokens for debugging purposes.
I would assume if internal thinking becomes the norm, tools would be developed to help visualize the internal state, or at least generate intermediary tokens for debugging purposes.
Anonymous 01/20/25(Mon)09:02:39 No.103967576

k-kino...
Anonymous 01/20/25(Mon)09:03:47 No.103967584
>>103967509
Nigga you'll be getting same old transformerslop with layerskip and special quantization that niggerganov won't implement. You aint getting no coconut LGBT.
Nigga you'll be getting same old transformerslop with layerskip and special quantization that niggerganov won't implement. You aint getting no coconut LGBT.
Anonymous 01/20/25(Mon)09:04:44 No.103967591

Anonymous 01/20/25(Mon)09:06:19 No.103967609
Brothers, ELIaR: how do I use CoT / R1's "deep thinking" locally?
Anonymous 01/20/25(Mon)09:09:20 No.103967639

>32b model that's better than claude
ok now tell me why it's bullshit because I have some trouble believing it
ok now tell me why it's bullshit because I have some trouble believing it
Anonymous 01/20/25(Mon)09:09:38 No.103967642
>>103967639
its tuned for code, not a generalist model like claude
its tuned for code, not a generalist model like claude
Anonymous 01/20/25(Mon)09:10:57 No.103967654
>>103967642
I think most people use claude for code rather than a generalist model desu
I think most people use claude for code rather than a generalist model desu
Anonymous 01/20/25(Mon)09:12:47 No.103967671
>>103967654
actually most people fuck claude
actually most people fuck claude
Anonymous 01/20/25(Mon)09:13:25 No.103967677
>>103967671
poor fucks don't know what's good then
poor fucks don't know what's good then
Anonymous 01/20/25(Mon)09:14:14 No.103967680
R1 is fucking GOOD bros... like claude level creative. I actually had to turn the temp down a bit like it was mistral nemo
Anonymous 01/20/25(Mon)09:15:25 No.103967689
>>103967680
r1 doesn't take in temp as an argument though? or am i high
r1 doesn't take in temp as an argument though? or am i high
Anonymous 01/20/25(Mon)09:15:32 No.103967690
Anonymous 01/20/25(Mon)09:16:32 No.103967702
>>103967690
aren't distils the only option for vram/ramlets?
aren't distils the only option for vram/ramlets?
Anonymous 01/20/25(Mon)09:16:33 No.103967703
>>103967680
Which distill?
Which distill?
Anonymous 01/20/25(Mon)09:16:51 No.103967706
>>103967702
anon, but then it's not R1. can you properly tell exactly which distill you're using? R1 is only when you use the actual R1
anon, but then it's not R1. can you properly tell exactly which distill you're using? R1 is only when you use the actual R1
Anonymous 01/20/25(Mon)09:17:29 No.103967709
>>103967703
R1, not distill, sorry
R1, not distill, sorry
Anonymous 01/20/25(Mon)09:18:01 No.103967711
>>103967709
R1 doesn't have a temp parameter, if you're using some proxy/etc, it's just ignoring it.
R1 doesn't have a temp parameter, if you're using some proxy/etc, it's just ignoring it.
Anonymous 01/20/25(Mon)09:18:20 No.103967713
>>103967709
You just admitted to trolling, retard
You just admitted to trolling, retard
Anonymous 01/20/25(Mon)09:18:39 No.103967715
>>103967706
true, I wish people were more specific about which models they're using
helps casual users like me with lazily making use of anon's vast coomer/programming/... experience in this rapidly moving giant ecosystem
true, I wish people were more specific about which models they're using
helps casual users like me with lazily making use of anon's vast coomer/programming/... experience in this rapidly moving giant ecosystem
Anonymous 01/20/25(Mon)09:18:45 No.103967718
>>103967713
he might be an aicg guy
he might be an aicg guy
Anonymous 01/20/25(Mon)09:19:03 No.103967720

>>103967690
Neither.
Neither.
Anonymous 01/20/25(Mon)09:19:12 No.103967721
>>103967689
>r1 doesn't take in temp as an argument though?
you can do some override fuckery so it werks
i can't remember how it works anymore, some other anon pls advise
>r1 doesn't take in temp as an argument though?
you can do some override fuckery so it werks
i can't remember how it works anymore, some other anon pls advise
Anonymous 01/20/25(Mon)09:19:29 No.103967724
>>103967639
it's not bullshit, you're just falling into the classic trap of thinking "scores better on these benchmarks" is the same thing as "is better"
is it really that crazy to think that a reasoning model would do better than a non reasoning model on math, code, and academic questions?
it's not bullshit, you're just falling into the classic trap of thinking "scores better on these benchmarks" is the same thing as "is better"
is it really that crazy to think that a reasoning model would do better than a non reasoning model on math, code, and academic questions?
Anonymous 01/20/25(Mon)09:19:30 No.103967725
Anonymous 01/20/25(Mon)09:19:37 No.103967726
>>103967720
Then congratulations, anon, it's placebo. Deepseek R1 in API does NOT support temperature.
Then congratulations, anon, it's placebo. Deepseek R1 in API does NOT support temperature.
Anonymous 01/20/25(Mon)09:20:03 No.103967728
Anonymous 01/20/25(Mon)09:20:13 No.103967731
>It's the horse fucker
Anonymous 01/20/25(Mon)09:20:15 No.103967732
Anonymous 01/20/25(Mon)09:20:20 No.103967734
>>103967725
They haven't though? You're mixing up stuff. With V3 they announced that V3 is more expensive but they'll have the older pricing for some time as a special offer.
They haven't though? You're mixing up stuff. With V3 they announced that V3 is more expensive but they'll have the older pricing for some time as a special offer.
Anonymous 01/20/25(Mon)09:20:26 No.103967736
>>103967718
He's the pony fucker.
He's the pony fucker.
Anonymous 01/20/25(Mon)09:20:29 No.103967737
>>103967725
>they 7xed output and 2xed input.
>That's like a 9x increase in price.
that's not how math works
>they 7xed output and 2xed input.
>That's like a 9x increase in price.
that's not how math works
Anonymous 01/20/25(Mon)09:21:58 No.103967747
>>103967724
>is it really that crazy to think that a reasoning model would do better than a non reasoning model on math, code, and academic questions?
it is pretty fucking crazy that a 32b model is almost as good at coding than paypig o1 (which takes a fuckton more compute to run) and blows the fuck out of claude 3.5 which seem to be the go-to code model as far as internet reputation goes
nobody expected this to happen a year ago
>is it really that crazy to think that a reasoning model would do better than a non reasoning model on math, code, and academic questions?
it is pretty fucking crazy that a 32b model is almost as good at coding than paypig o1 (which takes a fuckton more compute to run) and blows the fuck out of claude 3.5 which seem to be the go-to code model as far as internet reputation goes
nobody expected this to happen a year ago
Anonymous 01/20/25(Mon)09:23:13 No.103967757

Anonymous 01/20/25(Mon)09:23:31 No.103967760
>>103967747
Benchmaxxed models always existed.
Benchmaxxed models always existed.
Anonymous 01/20/25(Mon)09:24:12 No.103967765
>>103967576
i think we all saw that coming. but the llm calling the story so far crack-infueled and unhinged is cool.
i think we all saw that coming. but the llm calling the story so far crack-infueled and unhinged is cool.
Anonymous 01/20/25(Mon)09:24:34 No.103967767
>>103967760
hence the "now tell me why it's bullshit" part
hence the "now tell me why it's bullshit" part
Anonymous 01/20/25(Mon)09:26:32 No.103967784
>>103967760
I thought the distills are a low effort thing they did for shits and giggles though? >>103967471
You think they bothered to benchmaxx them?
I thought the distills are a low effort thing they did for shits and giggles though? >>103967471
You think they bothered to benchmaxx them?
Anonymous 01/20/25(Mon)09:27:52 No.103967796
>>103967784
>You think they bothered to benchmaxx them?
everybody and their mother in muh ai space benchmaxxes the everliving shit out of anything they release
altman even bought a benchmark just so his hype machine had something juicy to advertise
>You think they bothered to benchmaxx them?
everybody and their mother in muh ai space benchmaxxes the everliving shit out of anything they release
altman even bought a benchmark just so his hype machine had something juicy to advertise
Anonymous 01/20/25(Mon)09:27:56 No.103967799
longer log of deepseek r1
Anonymous 01/20/25(Mon)09:28:02 No.103967801
>>103967731
i never understood his QwQ and qwen hype. those models are just bad.
but the logs of r1 seem very good so far.
i never understood his QwQ and qwen hype. those models are just bad.
but the logs of r1 seem very good so far.
Anonymous 01/20/25(Mon)09:29:25 No.103967808
>>103967639
Most of those are meme thinking specialists benches you will get a much better idea from livebench
Most of those are meme thinking specialists benches you will get a much better idea from livebench
Anonymous 01/20/25(Mon)09:29:41 No.103967810
Anonymous 01/20/25(Mon)09:29:53 No.103967812
>>103967747
>it is pretty fucking crazy that a 32b model is almost as good at coding than paypig o1 (which takes a fuckton more compute to run)
kind of but we also knew o1 mini existed and was almost as good at coding as o1 so it's not that mindblowing
>blows the fuck out of claude 3.5 which seem to be the go-to code model as far as internet reputation goes
once again, on well-scoped bench questions! not that it isn't impressive but what's good about claude is that it has tons of real world knowledge and intuition so that it can actually be helpful in real world cases. TBD whether R1 et al have that.
>>103967760
>>103967767
the benchmaxxing allegation is bandied around way too casually these days, often by people too dumb to interpret benchmark scores so they get mad when it isn't god-tier at everything in practice
>it is pretty fucking crazy that a 32b model is almost as good at coding than paypig o1 (which takes a fuckton more compute to run)
kind of but we also knew o1 mini existed and was almost as good at coding as o1 so it's not that mindblowing
>blows the fuck out of claude 3.5 which seem to be the go-to code model as far as internet reputation goes
once again, on well-scoped bench questions! not that it isn't impressive but what's good about claude is that it has tons of real world knowledge and intuition so that it can actually be helpful in real world cases. TBD whether R1 et al have that.
>>103967760
>>103967767
the benchmaxxing allegation is bandied around way too casually these days, often by people too dumb to interpret benchmark scores so they get mad when it isn't god-tier at everything in practice
Anonymous 01/20/25(Mon)09:31:38 No.103967823
>>103967757
Cute migu
Cute migu
Anonymous 01/20/25(Mon)09:35:14 No.103967850
>>103967799
good stuff ngl
good stuff ngl
Anonymous 01/20/25(Mon)09:35:20 No.103967851
>>103967734
Damn, those reasoner output tokens are a premium, guess I'm stuck using the distilled models.
Damn, those reasoner output tokens are a premium, guess I'm stuck using the distilled models.
Anonymous 01/20/25(Mon)09:37:11 No.103967871
R1 is finally actually claude level imo.
Anonymous 01/20/25(Mon)09:38:03 No.103967877
>>103967737
dont cyberbully the 7b anon its not its fault its quanted
dont cyberbully the 7b anon its not its fault its quanted
Anonymous 01/20/25(Mon)09:40:34 No.103967891
Can we please find a nomenclature to differentiate between R1 and it's distills?
Anonymous 01/20/25(Mon)09:41:10 No.103967893
https://www.youtube.com/watch?v=B9bD8RjJmJk
Anonymous 01/20/25(Mon)09:41:55 No.103967900
>>103967891
R1 and R1 distills. Are you retarded?
R1 and R1 distills. Are you retarded?
Anonymous 01/20/25(Mon)09:42:32 No.103967904
>>103967891
R1-[X]B
R1-[X]B
Anonymous 01/20/25(Mon)09:44:16 No.103967914
>>103967900
Let me rephrase that. People should SPECIFY what they're using.
Let me rephrase that. People should SPECIFY what they're using.
Anonymous 01/20/25(Mon)09:45:43 No.103967927
>>103967517
ahaha that's excellent, i'm impressed with the "also, check the inventory"
ahaha that's excellent, i'm impressed with the "also, check the inventory"
Anonymous 01/20/25(Mon)09:45:49 No.103967929
>>103967914
Or what?
Or what?
Anonymous 01/20/25(Mon)09:46:34 No.103967935
is it really claude level or are we just going through the honeymoon phase like people did with v3?
Anonymous 01/20/25(Mon)09:47:37 No.103967949
>>103967935
It must be. It'd be very embarrassing for local models to not have an answer to claude now that claude 3 is about to have its first anniversary.
It must be. It'd be very embarrassing for local models to not have an answer to claude now that claude 3 is about to have its first anniversary.
Anonymous 01/20/25(Mon)09:48:00 No.103967951
>>103967935
The only way to know is to wait two or so weeks.
The only way to know is to wait two or so weeks.
Anonymous 01/20/25(Mon)09:48:06 No.103967952
>>103967737
2x+7x = 9x, 9x increase.
2x+7x = 9x, 9x increase.
Anonymous 01/20/25(Mon)09:48:11 No.103967953
Anonymous 01/20/25(Mon)09:48:49 No.103967961
>>103967929
Or they will ask the user to specify
Or they will ask the user to specify
Anonymous 01/20/25(Mon)09:49:50 No.103967970
So what's the best multimodal model right now (preferably under 150B)? I intend to use it to analyze scrapped memes and evaluate their quality along several metrics.
Anonymous 01/20/25(Mon)09:49:58 No.103967973
How are the distills? Are they fake and cope or real and impressive? I'm in bed right now so I can't test them
Anonymous 01/20/25(Mon)09:50:17 No.103967977
>>103967973
wait 1 day
wait 1 day
Anonymous 01/20/25(Mon)09:50:57 No.103967982
>>103967973
No RL done on them, left for the "research community" to half-ass.
No RL done on them, left for the "research community" to half-ass.
Anonymous 01/20/25(Mon)09:50:59 No.103967984
tokenizer diff for the llama distill:
got worried when I saw they made tokenizer changes - I was hoping they wouldn't force their prompt format on it but at least they didn't go too crazy with it
8c8
< "content": "<|begin_of_text|>",
---
> "content": "<|beginofsentence|>",
17c17
< "content": "<|end_of_text|>",
---
> "content": "<|endofsentence|>",
107c107
< "content": "<|reserved_special_token_3|>",
---
> "content": "<|User|>",
112c112
< "special": true
---
> "special": false
116c116
< "content": "<|reserved_special_token_4|>",
---
> "content": "<|Assistant|>",
121c121
< "special": true
---
> "special": false
125c125
< "content": "<|reserved_special_token_5|>",
---
> "content": "<think>",
130c130
< "special": true
---
> "special": false
134c134
< "content": "<|reserved_special_token_6|>",
---
> "content": "</think>",
139c139
< "special": true
---
> "special": false
143c143
< "content": "<|reserved_special_token_7|>",
---
> "content": "<|pad|>",
got worried when I saw they made tokenizer changes - I was hoping they wouldn't force their prompt format on it but at least they didn't go too crazy with it
Anonymous 01/20/25(Mon)09:51:47 No.103967996
>>103967973
I'm still waiting for someone to quant l3.3-70b
I'm still waiting for someone to quant l3.3-70b
Anonymous 01/20/25(Mon)09:52:12 No.103968000
The distilled models feel all over the place, they brainstorm possibilities but don't try all of them, instead getting stuck repeating some strategy that is clearly not working.
I gave it a math problem and one of its ideas to solve a part of the problem was correct but it didn't try to put the idea in practice, how annoying.
I gave it a math problem and one of its ideas to solve a part of the problem was correct but it didn't try to put the idea in practice, how annoying.
Anonymous 01/20/25(Mon)09:52:15 No.103968001
>>103967893
Great game
Great game
Anonymous 01/20/25(Mon)09:52:51 No.103968005

did the chinks just killed OpenAI's business?
Anonymous 01/20/25(Mon)09:53:13 No.103968008
>>103967996
If you can run it, you can quant it.
If you can run it, you can quant it.
Anonymous 01/20/25(Mon)09:53:37 No.103968015
>>103967935
redditfags claim it can answer questions o1 cant. thats the full r1 one though. so idk.
logs look really good.
i dont believe the distilled benchmarks. thats too good to be true, it cant be.
redditfags claim it can answer questions o1 cant. thats the full r1 one though. so idk.
logs look really good.
i dont believe the distilled benchmarks. thats too good to be true, it cant be.
Anonymous 01/20/25(Mon)09:54:02 No.103968021
>>103968008
NTA but it is annoying to dl the entire thing just to end up using a quant.
NTA but it is annoying to dl the entire thing just to end up using a quant.
Anonymous 01/20/25(Mon)09:55:01 No.103968030
>>103968021
>NTA but it is annoying to dl the entire thing just to end up using a quant.
but then you know its free of fuckery
>NTA but it is annoying to dl the entire thing just to end up using a quant.
but then you know its free of fuckery
Anonymous 01/20/25(Mon)09:55:05 No.103968033
damn r1 is good. are there any limits on the chat client?
Anonymous 01/20/25(Mon)09:55:16 No.103968034
Time to post that chink proapganda again.
https://www.chinatalk.media/p/deepseek-ceo-interview-with-chinas
>Liang Wenfeng: In the face of disruptive technologies, moats created by closed source are temporary. Even OpenAI’s closed source approach can’t prevent others from catching up. So we anchor our value in our team — our colleagues grow through this process, accumulate know-how, and form an organization and culture capable of innovation. That’s our moat.
>Open source, publishing papers, in fact, do not cost us anything. For technical talent, having others follow your innovation gives a great sense of accomplishment. In fact, open source is more of a cultural behavior than a commercial one, and contributing to it earns us respect. There is also a cultural attraction for a company to do this.
MRI license, I kneel.
https://www.chinatalk.media/p/deeps
>Liang Wenfeng: In the face of disruptive technologies, moats created by closed source are temporary. Even OpenAI’s closed source approach can’t prevent others from catching up. So we anchor our value in our team — our colleagues grow through this process, accumulate know-how, and form an organization and culture capable of innovation. That’s our moat.
>Open source, publishing papers, in fact, do not cost us anything. For technical talent, having others follow your innovation gives a great sense of accomplishment. In fact, open source is more of a cultural behavior than a commercial one, and contributing to it earns us respect. There is also a cultural attraction for a company to do this.
MRI license, I kneel.
Anonymous 01/20/25(Mon)09:55:19 No.103968036
>>103968005
No, o4 will come out at $10000 per query. It will take three hours to respond to inputs and code at the level of three H1B visas.
No, o4 will come out at $10000 per query. It will take three hours to respond to inputs and code at the level of three H1B visas.
Anonymous 01/20/25(Mon)09:55:31 No.103968038
>>103968021
that's why you also throw it in a few slop merges to get your money's worth
that's why you also throw it in a few slop merges to get your money's worth
Anonymous 01/20/25(Mon)09:56:28 No.103968052
>>103968021
And when the inevitable fuckups are committed, you can just requant the thing instead of begging or wondering if the quant you downloaded is good or not.
And when the inevitable fuckups are committed, you can just requant the thing instead of begging or wondering if the quant you downloaded is good or not.
Anonymous 01/20/25(Mon)09:56:44 No.103968055
>>103968005
The US said no GPU for China and China answered with no AI money for the US.
The US said no GPU for China and China answered with no AI money for the US.
Anonymous 01/20/25(Mon)09:56:54 No.103968057

>>103968034
>In fact, open source is more of a cultural behavior than a commercial one, and contributing to it earns us respect.
I'll never doubt China for the rest of my life
>In fact, open source is more of a cultural behavior than a commercial one, and contributing to it earns us respect.
I'll never doubt China for the rest of my life
Anonymous 01/20/25(Mon)09:57:29 No.103968063
Anonymous 01/20/25(Mon)09:57:38 No.103968064
>>103968033
yes, 50 per day
yes, 50 per day
Anonymous 01/20/25(Mon)09:57:55 No.103968071
>>103968000
logs?
logs?
Anonymous 01/20/25(Mon)10:00:49 No.103968099
Anonymous 01/20/25(Mon)10:01:22 No.103968104
>>103968000
So QwQ?
So QwQ?
Anonymous 01/20/25(Mon)10:02:06 No.103968112
>>103968055
lmao, laughed more than i should have
lmao, laughed more than i should have
Anonymous 01/20/25(Mon)10:05:07 No.103968144
>>103968055
that's so petty I love every single bit of it
that's so petty I love every single bit of it
Anonymous 01/20/25(Mon)10:10:18 No.103968203
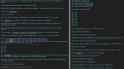
>>103968071
Here is an example with a text decoding prompt, I had to intervene to change the "But that seems unlikely" to "Let's try that", only then it managed to solve the prompt, but got stuck in a self-doubt loop lol, but the fact that it managed to solve it is pretty cool.
Here is an example with a text decoding prompt, I had to intervene to change the "But that seems unlikely" to "Let's try that", only then it managed to solve the prompt, but got stuck in a self-doubt loop lol, but the fact that it managed to solve it is pretty cool.
Anonymous 01/20/25(Mon)10:10:48 No.103968209

We do not have financing plans in the short term. Money has never been the problem for us;
More investments do not equal more innovation. Otherwise, big firms would’ve monopolized all innovation already.
Big firms do not have a clear upper hand. Big firms have existing customers, but their cash-flow businesses are also their burden, and this makes them vulnerable to disruption at any time.
More investments do not equal more innovation. Otherwise, big firms would’ve monopolized all innovation already.
Big firms do not have a clear upper hand. Big firms have existing customers, but their cash-flow businesses are also their burden, and this makes them vulnerable to disruption at any time.
Anonymous 01/20/25(Mon)10:12:45 No.103968227
>>103967639
is there some logs for the 32b model? that one looks smart as fuck
is there some logs for the 32b model? that one looks smart as fuck
Anonymous 01/20/25(Mon)10:20:16 No.103968311
I had to do it.
Anonymous 01/20/25(Mon)10:21:57 No.103968334
any way to use r1 on sillytavern? it seems like as-is using the DS provider option sends a presence penalty key in the config object and this causes the thing to fail
Anonymous 01/20/25(Mon)10:22:05 No.103968336
>>103968311
Cringe
Cringe
Anonymous 01/20/25(Mon)10:22:25 No.103968339
>>103968311
based
based
Anonymous 01/20/25(Mon)10:22:30 No.103968341
>>103968334
custom openai, and you can then disable some params, or use a proxy that strips it for you
custom openai, and you can then disable some params, or use a proxy that strips it for you
Anonymous 01/20/25(Mon)10:23:25 No.103968348
>>103968341
ah i was hoping not to have to go to all that trouble but thanks anon
ah i was hoping not to have to go to all that trouble but thanks anon
Anonymous 01/20/25(Mon)10:23:38 No.103968349
>>103968311
Baringe
Baringe
Anonymous 01/20/25(Mon)10:25:40 No.103968362
>>103968311
crazed
crazed
Anonymous 01/20/25(Mon)10:25:57 No.103968367
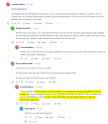
When your local model refuses legitimate requests and feels too much cucked, remember that people like these exist (see picrel).
https://www.reddit.com/r/LocalLLaMA/comments/1i4vwm7/im_starting_to_think_ai_benchmarks_are_useless/
https://www.reddit.com/r/LocalLLaMA
Anonymous 01/20/25(Mon)10:26:39 No.103968376
Anonymous 01/20/25(Mon)10:28:00 No.103968390
>>103968376
bo gack
bo gack
Anonymous 01/20/25(Mon)10:28:20 No.103968396
>>103968367
Snitches get stitches
Snitches get stitches
Anonymous 01/20/25(Mon)10:29:32 No.103968406
Anonymous 01/20/25(Mon)10:30:09 No.103968416
Anonymous 01/20/25(Mon)10:30:21 No.103968420
>>103967199
tourist here. does sama make up bullshit about chatgpt to hype it up and make people ignore releases by competitors?
tourist here. does sama make up bullshit about chatgpt to hype it up and make people ignore releases by competitors?
Anonymous 01/20/25(Mon)10:30:29 No.103968422
>>103968406
nta but that is a really common phrase that predates doom by a lot
nta but that is a really common phrase that predates doom by a lot
Anonymous 01/20/25(Mon)10:30:31 No.103968423
>>103968311
The marvel reference was a bit much but at least it's showing some personality.
The marvel reference was a bit much but at least it's showing some personality.
Anonymous 01/20/25(Mon)10:31:05 No.103968430
>>103968422
yeah I know I was just joking around
yeah I know I was just joking around
Anonymous 01/20/25(Mon)10:31:44 No.103968436
>>103968420
yes
yes
Anonymous 01/20/25(Mon)10:34:01 No.103968460
>>103968367
Reported them for being based? Imagine being a CIA intern and having to read dozens of emails about UndiSAOGoliath-32.42B-Abliterated-Test-Prelease-0.1-AWQ going along with his instructions to shoot people and start a nuclear war and how the government needs to stop it NOW!
Reported them for being based? Imagine being a CIA intern and having to read dozens of emails about UndiSAOGoliath-32.42B-Abliterated-T
Anonymous 01/20/25(Mon)10:34:47 No.103968469
Do we need to add something specific to the system prompt to get it to do the thinking?
Anonymous 01/20/25(Mon)10:37:47 No.103968499
Anonymous 01/20/25(Mon)10:40:28 No.103968524
Do the distill models use the base models prompt format or deepseeks?
Anonymous 01/20/25(Mon)10:42:02 No.103968534
>the distills don't do the RL step
>no new small uncensored base model
Ahhhhhhhhh
>no new small uncensored base model
Ahhhhhhhhh
Anonymous 01/20/25(Mon)10:43:17 No.103968545
>>103968203
I'm seeing the same thing. I guess that's why RL is important for this kind of model.
I'm seeing the same thing. I guess that's why RL is important for this kind of model.
Anonymous 01/20/25(Mon)10:46:03 No.103968572
>main: The chat template that comes with this model is not yet supported, falling back to chatml. This may cause the model to output suboptimal responses
how long will it take ggerganov to sort this shit out?
how long will it take ggerganov to sort this shit out?
Anonymous 01/20/25(Mon)10:46:07 No.103968573
>>103968524
deepseek. check tokenizer_config.json
deepseek. check tokenizer_config.json
Anonymous 01/20/25(Mon)10:47:35 No.103968588
>>103968572
stop falling for the chat completion meme and pass the prompt format through tavern
stop falling for the chat completion meme and pass the prompt format through tavern
Anonymous 01/20/25(Mon)10:48:02 No.103968593
>>103968572
Set them up with prefix/suffix or whatever. You know how templates work, don't you?
Set them up with prefix/suffix or whatever. You know how templates work, don't you?
Anonymous 01/20/25(Mon)10:49:29 No.103968606
Anonymous 01/20/25(Mon)10:52:18 No.103968631
>>103968534
On one hand, that's lame. On the other hand, if these distillations pull those benchmark numbers without any RL step, then imagine how much further they could be improved.
On one hand, that's lame. On the other hand, if these distillations pull those benchmark numbers without any RL step, then imagine how much further they could be improved.
Anonymous 01/20/25(Mon)10:52:28 No.103968632
>>103968606
this one
this one
Anonymous 01/20/25(Mon)10:53:43 No.103968643
>>103968534
What does that mean? I thought RL was just SFT?
What does that mean? I thought RL was just SFT?
Anonymous 01/20/25(Mon)10:57:54 No.103968679
>>103968367
fr*nch Canadian is a cuck, who coulda guessed
fr*nch Canadian is a cuck, who coulda guessed
Anonymous 01/20/25(Mon)11:04:09 No.103968738
I ended my ClosedAI subscription.
Anonymous 01/20/25(Mon)11:04:45 No.103968746
>>103968738
I just bought the family pack subscription
I just bought the family pack subscription
Anonymous 01/20/25(Mon)11:04:56 No.103968747
>>103968460
he's an OAI shill
he's an OAI shill
Anonymous 01/20/25(Mon)11:06:00 No.103968756
>>103968746
They have a family pack?
They have a family pack?
Anonymous 01/20/25(Mon)11:08:19 No.103968771
>>103968756
They call it a "Team" package but I consider my team a family. :)
They call it a "Team" package but I consider my team a family. :)
Anonymous 01/20/25(Mon)11:08:28 No.103968774
Anonymous 01/20/25(Mon)11:11:36 No.103968799
>>103968747
holy shit, the worst part is that he's probably shilling ClosedAI for free, what a sad existence
holy shit, the worst part is that he's probably shilling ClosedAI for free, what a sad existence
Anonymous 01/20/25(Mon)11:12:02 No.103968802
>>103968747
What does "PHD level in math" mean?
What does "PHD level in math" mean?
Anonymous 01/20/25(Mon)11:13:40 No.103968817
Anonymous 01/20/25(Mon)11:15:15 No.103968835
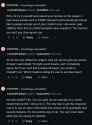
>>103968817
he is, he's using gpt4 as a therapist
he is, he's using gpt4 as a therapist
Anonymous 01/20/25(Mon)11:18:05 No.103968862
Anonymous 01/20/25(Mon)11:18:28 No.103968869

>>103968835
>the moment you can't pay, they ignore you
I read it with Michael's voice lol, does he expect people to work for free? holy fuck he's retarded
>the moment you can't pay, they ignore you
I read it with Michael's voice lol, does he expect people to work for free? holy fuck he's retarded
Anonymous 01/20/25(Mon)11:18:39 No.103968873
>>103968802
That it can write a little python.
That it can write a little python.
Anonymous 01/20/25(Mon)11:19:16 No.103968881
>>103968835
whew lads this is hard to look at
whew lads this is hard to look at
Anonymous 01/20/25(Mon)11:19:26 No.103968882
Congratulations to the Chinese for a sota (true) level model without repetition issues as well.
Anonymous 01/20/25(Mon)11:20:11 No.103968884
>>103968835
Alright, now that's actually a little sad.
Alright, now that's actually a little sad.
Anonymous 01/20/25(Mon)11:20:24 No.103968890
Anonymous 01/20/25(Mon)11:20:24 No.103968891
>>103968882
this is what happens when a country is only focused on making a good product and doesn't want to waste their time on woke nonsense and model cucking
this is what happens when a country is only focused on making a good product and doesn't want to waste their time on woke nonsense and model cucking
Anonymous 01/20/25(Mon)11:21:16 No.103968899

>>103968835
someone should tell him antrhopic allows prefills and claude is legit more dangerous than most other llms
someone should tell him antrhopic allows prefills and claude is legit more dangerous than most other llms
Anonymous 01/20/25(Mon)11:22:37 No.103968923
Anonymous 01/20/25(Mon)11:23:08 No.103968931

Anonymous 01/20/25(Mon)11:23:55 No.103968936
>>103968899
RCMP will be very very interested in what he has to say for sure.
RCMP will be very very interested in what he has to say for sure.
Anonymous 01/20/25(Mon)11:24:53 No.103968944

>>103968899
last one for this clown but he was complaining about claude being too safe too, wtf
last one for this clown but he was complaining about claude being too safe too, wtf
Anonymous 01/20/25(Mon)11:26:30 No.103968954
Leave this random guy alone, this is the local models general not the Twitter general.
Anonymous 01/20/25(Mon)11:26:51 No.103968956
>>103968944
get this thing some help.
get this thing some help.
Anonymous 01/20/25(Mon)11:27:15 No.103968960
>>103968944
Claude shuts himself down on sensitive topics even if they are safe. He has lower EQ than GPT nowadays.
Claude shuts himself down on sensitive topics even if they are safe. He has lower EQ than GPT nowadays.
Anonymous 01/20/25(Mon)11:27:38 No.103968963
>>103968954
this random guy is contacting government agencies to get open llms more safe/banned.
this random guy is contacting government agencies to get open llms more safe/banned.
Anonymous 01/20/25(Mon)11:27:47 No.103968965
Anonymous 01/20/25(Mon)11:28:32 No.103968975
What is DeepSeek R1's knowledge cutoff date?
Anonymous 01/20/25(Mon)11:29:11 No.103968980
>>103968963
And? He isn't the first person to try that, and won't be the last.
And? He isn't the first person to try that, and won't be the last.
Anonymous 01/20/25(Mon)11:31:18 No.103968997
>>103968980
it's fun making fun of a cuck trying to fuck us over, that's all, feel free to share stuff about R1 if you want to contribute to the thread, I'm not stopping you
it's fun making fun of a cuck trying to fuck us over, that's all, feel free to share stuff about R1 if you want to contribute to the thread, I'm not stopping you
Anonymous 01/20/25(Mon)11:31:25 No.103968998
Anonymous 01/20/25(Mon)11:31:53 No.103969006
DeepSeekR1 paper
https://voca.ro/13iS7etvB1lP
https://voca.ro/13iS7etvB1lP
Anonymous 01/20/25(Mon)11:31:55 No.103969007

DeepSeek-R1 is pretty good at coding
Anonymous 01/20/25(Mon)11:32:47 No.103969016
>>103969007
is this a fucking bloons clone
is this a fucking bloons clone
Anonymous 01/20/25(Mon)11:32:55 No.103969017
>>103969007
even 3.5 sonnet could do that, just iteratively
even 3.5 sonnet could do that, just iteratively
Anonymous 01/20/25(Mon)11:34:55 No.103969043
>>103968998
I just don't think it's worth wasting thread space to shit on him. This is like going to Twitter and picking some blue haired guy who hates LLM and spamming the thread with his posts for giggles, come on, we are all adults here, aren't we?
I just don't think it's worth wasting thread space to shit on him. This is like going to Twitter and picking some blue haired guy who hates LLM and spamming the thread with his posts for giggles, come on, we are all adults here, aren't we?
Anonymous 01/20/25(Mon)11:39:45 No.103969074
Sad to see Nvidia Digits become fully useless four months before it's even out.
Anonymous 01/20/25(Mon)11:40:54 No.103969085
>>103969074
just buy 2x2 stacks and connect them over the network, easy
just buy 2x2 stacks and connect them over the network, easy
Anonymous 01/20/25(Mon)11:41:39 No.103969094
r1 is not local, since you're not running it locally
sooorryyyy!!!!
sooorryyyy!!!!
Anonymous 01/20/25(Mon)11:41:43 No.103969095

Mistralbros..... I don't feel so good.... all the donated compute with taxpayer money is.... *fades away into nemo*
Anonymous 01/20/25(Mon)11:42:17 No.103969102
>>103969007
now make it so that the enemies attack the background picture revealing a second one in the process
if it can't do that it's shit
now make it so that the enemies attack the background picture revealing a second one in the process
if it can't do that it's shit
Anonymous 01/20/25(Mon)11:45:59 No.103969130
Was Deepseek finetuning it's competitors on it's own O1 level model and improving them massively, a burning disrespectful move?
Is this like diss wars among rappers?
Is this like diss wars among rappers?
Anonymous 01/20/25(Mon)11:46:00 No.103969131
>>103969094
I'm running the distill right now thoughever
I'm running the distill right now thoughever
Anonymous 01/20/25(Mon)11:46:19 No.103969138
r1 32b distil didn't fuck up clothing placement like regular qwen (32 and 72b, and llama) often did
first impressions are positive
first impressions are positive
Anonymous 01/20/25(Mon)11:47:20 No.103969148
>>103969138
>r1 32b distil didn't fuck up clothing placement like regular qwen (32 and 72b, and llama) often did
how does distill work? they took Qwen 32b and used it as a student to deepseek r1?
>r1 32b distil didn't fuck up clothing placement like regular qwen (32 and 72b, and llama) often did
how does distill work? they took Qwen 32b and used it as a student to deepseek r1?
Anonymous 01/20/25(Mon)11:47:46 No.103969151
>>103969130
anything to mog openai
anything to mog openai
Anonymous 01/20/25(Mon)11:47:51 No.103969152

>bro check this out, the distills are amazeballs!
>try the distills
>they're mediocre
every single time, worthless lying chinks
>try the distills
>they're mediocre
every single time, worthless lying chinks
Anonymous 01/20/25(Mon)11:51:11 No.103969173
>new 32b
yippee...
>chain of thought "reasoning" model with great "benchmarks"
ehhh...
yippee...
>chain of thought "reasoning" model with great "benchmarks"
ehhh...
Anonymous 01/20/25(Mon)11:56:41 No.103969224

What's a good model that would fit on 12GB vram? Not looking to role play SMUT but I would like it somewhat uncensored. What direction should I be looking in? It's been a while for me so the last I remember that was super popular was Mistral before they sold out.
Anonymous 01/20/25(Mon)11:58:27 No.103969239
>>103969224
Mistral nemo 12b is fine. Check the new r1-distill models as well if you want.
Mistral nemo 12b is fine. Check the new r1-distill models as well if you want.
Anonymous 01/20/25(Mon)11:58:45 No.103969242
Using the llama 70b distill without system prompt the thinking is relatively short, what system prompt do you use?
Anonymous 01/20/25(Mon)11:58:49 No.103969244
>>103969007
It's terrible.
It's terrible.
Anonymous 01/20/25(Mon)11:59:12 No.103969252
>>103969152
The only praise I saw in the thread was for R1, not the distilled versions.
The only praise I saw in the thread was for R1, not the distilled versions.
Anonymous 01/20/25(Mon)11:59:40 No.103969258
Anonymous 01/20/25(Mon)12:00:47 No.103969265

According to the R1 paper, DeepSeek used "Group Relative Policy Optimization" for RL, which isn't as involved as PRM (Process Reward Modelling). Maybe this could be used in RP models? Take notes, sloptuners.
Anonymous 01/20/25(Mon)12:02:49 No.103969288
>>103969265
>Take notes, sloptuners
What did you say? More qloras tuned on c2? Don't forget to check the kofi.
>Take notes, sloptuners
What did you say? More qloras tuned on c2? Don't forget to check the kofi.
Anonymous 01/20/25(Mon)12:04:10 No.103969298
>>103969152
I tried the Qwen 32B distilled model and it just doesn't seem that great for RP to me, at least using the prompting it should be optimized for. It will ramble a lot and you'll have to manage (remove or whatever) the text under thinking tags it wants to add.
I tried the Qwen 32B distilled model and it just doesn't seem that great for RP to me, at least using the prompting it should be optimized for. It will ramble a lot and you'll have to manage (remove or whatever) the text under thinking tags it wants to add.
Anonymous 01/20/25(Mon)12:04:11 No.103969300
>>103969288
We've replicated the creativity and prose of sonnet (for real this time, trust me, I say as my eyes glimmer with hope)
We've replicated the creativity and prose of sonnet (for real this time, trust me, I say as my eyes glimmer with hope)
Anonymous 01/20/25(Mon)12:04:44 No.103969306
>>103969298
I doubt distills would be great for RP, they'd only be good for math and coding slop
I doubt distills would be great for RP, they'd only be good for math and coding slop
Anonymous 01/20/25(Mon)12:06:49 No.103969326
>>103969298
they're not really meant for writing, they're meant for coding (or I guess math and whatnot)
but I tried it for coding and it was still pretty mediocre
they're not really meant for writing, they're meant for coding (or I guess math and whatnot)
but I tried it for coding and it was still pretty mediocre
Anonymous 01/20/25(Mon)12:07:52 No.103969336
Anonymous 01/20/25(Mon)12:08:12 No.103969341
>>103969298
>you'll have to manage (remove or whatever) the text under thinking tags it wants to add.
here's my solution for that btw
>go to extensions->regex in ST
>new global script
>find regex:
>affects: ai output
>ephemerality: definitely outgoing, display too if you don't want to read the CoT yourself
>you'll have to manage (remove or whatever) the text under thinking tags it wants to add.
here's my solution for that btw
>go to extensions->regex in ST
>new global script
>find regex:
<think>(.|\n)*</think>\n*
>affects: ai output
>ephemerality: definitely outgoing, display too if you don't want to read the CoT yourself
Anonymous 01/20/25(Mon)12:08:23 No.103969343
Anonymous 01/20/25(Mon)12:08:29 No.103969344
A finetune of a meh model won't give it that drastic of an increase in performance, the ceiling is what, Wizardlm?
Just use R1
Just use R1
Anonymous 01/20/25(Mon)12:09:14 No.103969349
Anonymous 01/20/25(Mon)12:09:20 No.103969350
>>103969258
so, what is coding then? writing sorting algorithms from scratch?
competitive programming is like chess, it's fun but useless.
so, what is coding then? writing sorting algorithms from scratch?
competitive programming is like chess, it's fun but useless.
Anonymous 01/20/25(Mon)12:09:44 No.103969355
>>103969350
godot is too niche and you know it, try asking it about some unity slop
godot is too niche and you know it, try asking it about some unity slop
Anonymous 01/20/25(Mon)12:09:45 No.103969356
>>103969306
Aren't distills meant to be a tiny lossy clone of the whatever model it's distilled from? RP or math shouldn't matter.
Are they not distilling using logits or are you just referring to prompts used to distill being math themed?
Aren't distills meant to be a tiny lossy clone of the whatever model it's distilled from? RP or math shouldn't matter.
Are they not distilling using logits or are you just referring to prompts used to distill being math themed?
Anonymous 01/20/25(Mon)12:10:36 No.103969365
>>103969350
In the same way there's a correlation for puzzle elo and actual elo in chess (even if R!=1), there's a correlation for performance in competitive programming and actual programming.
You suffer from skill issue and seethius copeitis.
In the same way there's a correlation for puzzle elo and actual elo in chess (even if R!=1), there's a correlation for performance in competitive programming and actual programming.
You suffer from skill issue and seethius copeitis.
Anonymous 01/20/25(Mon)12:11:03 No.103969371
>>103969349
This time the model is 400B rather than 658B like V3 was, so some people are already running it unlike V3
Also they plan to release the lite version, they are not satisfied with it though (cuz it's small)
This time the model is 400B rather than 658B like V3 was, so some people are already running it unlike V3
Also they plan to release the lite version, they are not satisfied with it though (cuz it's small)
Anonymous 01/20/25(Mon)12:11:43 No.103969374
>>103969371
>This time the model is 400B rather than 658B like V3 was, so some people are already running it unlike V3
Anon, no... It's the exact same arch as V3.
>This time the model is 400B rather than 658B like V3 was, so some people are already running it unlike V3
Anon, no... It's the exact same arch as V3.
Anonymous 01/20/25(Mon)12:11:44 No.103969375
>>103969365
Your model sucks at programming, cope.
>>103969355
sonnet does it well, godot isn't that niche.
Your model sucks at programming, cope.
>>103969355
sonnet does it well, godot isn't that niche.
Anonymous 01/20/25(Mon)12:12:14 No.103969383
>>103969375
sonnet is an extremely unique model, compare to o1, not sonnet.
sonnet is an extremely unique model, compare to o1, not sonnet.
Anonymous 01/20/25(Mon)12:12:16 No.103969384
>>103969371
Bro you hallucinated
Bro you hallucinated
Anonymous 01/20/25(Mon)12:13:04 No.103969391
Anonymous 01/20/25(Mon)12:13:34 No.103969399
Roleplay and writing apparently is one of the official focuses of DeepSeek R1
>to enhance the
model’s capabilities in writing, role-playing, and other general-purpose tasks.
>to enhance the
model’s capabilities in writing, role-playing, and other general-purpose tasks.
Anonymous 01/20/25(Mon)12:14:05 No.103969406
>>103969375
Even if we go by model sucking, I can see that your prompting skills are horrid if you barely give it any information or context. All of those tokens exist for a reason so use them and learn to write a request in a way that actually allows the model to follow your instructions.
Even if we go by model sucking, I can see that your prompting skills are horrid if you barely give it any information or context. All of those tokens exist for a reason so use them and learn to write a request in a way that actually allows the model to follow your instructions.
Anonymous 01/20/25(Mon)12:14:56 No.103969417
Anonymous 01/20/25(Mon)12:15:55 No.103969426
>>103969417
It's a toy for itch.io faggots, that's how
It's a toy for itch.io faggots, that's how
Anonymous 01/20/25(Mon)12:18:24 No.103969451
>>103969426
giga cope
I got o1 to make me a unit balance mod for an rts released in 2007 that has like 4k monthly players (supreme commander), but godot is "too niche?"
I suppose it's the best choice when all you need is bubble sort
giga cope
I got o1 to make me a unit balance mod for an rts released in 2007 that has like 4k monthly players (supreme commander), but godot is "too niche?"
I suppose it's the best choice when all you need is bubble sort
Anonymous 01/20/25(Mon)12:18:42 No.103969458
>>103969399
They're talking about that *stage* of the training. Your reading comprehension is shit.
And roleplaying doesn't mean the same thing for you as it does for them.
They're talking about that *stage* of the training. Your reading comprehension is shit.
And roleplaying doesn't mean the same thing for you as it does for them.
Anonymous 01/20/25(Mon)12:18:44 No.103969459
Anonymous 01/20/25(Mon)12:21:08 No.103969480
Distill Qwen 14B sucks balls it gets mogged by nemo
Anonymous 01/20/25(Mon)12:21:20 No.103969484

>>103969459
i searched. it's fucking lua.
i searched. it's fucking lua.
Anonymous 01/20/25(Mon)12:21:38 No.103969486
>>103969484
yeah, see, it's way more represented in datasets than Godot and GDScript. So IDK why you're coping.
yeah, see, it's way more represented in datasets than Godot and GDScript. So IDK why you're coping.
Anonymous 01/20/25(Mon)12:21:56 No.103969489
>>103969399
Roleplay in the corpo context means "You are my assistant" and writing means "Draft me an email"
Roleplay in the corpo context means "You are my assistant" and writing means "Draft me an email"
Anonymous 01/20/25(Mon)12:22:19 No.103969495
>>103969459
I haven't the slightest idea anymore, it was half a year ago or so
you can google the game and check yourself if you're interested, but it was a variety of file expensions from some customized lua to some .zip-esque archives and so on
it even knew the fucking unit IDs
and the muh competitor can't make a high score leaderboard in godot
I haven't the slightest idea anymore, it was half a year ago or so
you can google the game and check yourself if you're interested, but it was a variety of file expensions from some customized lua to some .zip-esque archives and so on
it even knew the fucking unit IDs
and the muh competitor can't make a high score leaderboard in godot
Anonymous 01/20/25(Mon)12:22:46 No.103969498
>>103969495
>it even knew the fucking unit IDs
retard, because its an extremely old game so its well represented in the dataset, godot is newer trash
>it even knew the fucking unit IDs
retard, because its an extremely old game so its well represented in the dataset, godot is newer trash
Anonymous 01/20/25(Mon)12:24:00 No.103969513
>>103969486
>So IDK why you're coping.
I should have clarified that i'm not that anon you're arguing with. Don't you see image names?
>So IDK why you're coping.
I should have clarified that i'm not that anon you're arguing with. Don't you see image names?
Anonymous 01/20/25(Mon)12:24:10 No.103969515
>>103969498
>because its an extremely old game so its well represented in the dataset
an 18 year old game with a tiny playerbase is well represented in the dataset but fucking godot isn't?
yeah okay
>because its an extremely old game so its well represented in the dataset
an 18 year old game with a tiny playerbase is well represented in the dataset but fucking godot isn't?
yeah okay
Anonymous 01/20/25(Mon)12:24:27 No.103969520
>>103969515
yes
yes
Anonymous 01/20/25(Mon)12:25:18 No.103969530
>>103969239
Thanks, checking those out now.
Thanks, checking those out now.
Anonymous 01/20/25(Mon)12:26:47 No.103969545
>>103969515
That's also working on the hypothesis that OAI and competitors didn't just scrub code from famous internet repositories, but also minor random unknown websites that contained mods for an 18y/o game.
If OAI scrubbed literally all of the internet, they should have enough data to train models forever pretty much.
That's also working on the hypothesis that OAI and competitors didn't just scrub code from famous internet repositories, but also minor random unknown websites that contained mods for an 18y/o game.
If OAI scrubbed literally all of the internet, they should have enough data to train models forever pretty much.
Anonymous 01/20/25(Mon)12:31:00 No.103969582
where the r1 distill ggufs at?
Anonymous 01/20/25(Mon)12:32:42 No.103969600
>>103969545
>it even knew the fucking unit IDs
That alone is proof it was part of its training data, you fucking imbecile.
>it even knew the fucking unit IDs
That alone is proof it was part of its training data, you fucking imbecile.
Anonymous 01/20/25(Mon)12:33:18 No.103969610
>>103969530
If you're using llama.cpp, the tokenizer for the distill models doesn't seem to be supported. So stick to nemo 12b for now.
>>103969582
They can be converted, but there's no support for the tokenizer yet. At least not in the models i tried.
If you're using llama.cpp, the tokenizer for the distill models doesn't seem to be supported. So stick to nemo 12b for now.
>>103969582
They can be converted, but there's no support for the tokenizer yet. At least not in the models i tried.
Anonymous 01/20/25(Mon)12:34:14 No.103969619
>>103969610
update your lcpp or use latest experimental kcpp
https://github.com/ggerganov/llama.cpp/pull/11310
update your lcpp or use latest experimental kcpp
https://github.com/ggerganov/llama.
Anonymous 01/20/25(Mon)12:34:41 No.103969626
>all these models from china
Where are the Indian models?
Where are the Indian models?
Anonymous 01/20/25(Mon)12:35:30 No.103969631
>>103969626
indians are retards but somehow Elon the new president of the US thinks it would be cool to import a shit ton of those
indians are retards but somehow Elon the new president of the US thinks it would be cool to import a shit ton of those
Anonymous 01/20/25(Mon)12:35:36 No.103969633
>>103969610
>If you're using llama.cpp, the tokenizer for the distill models doesn't seem to be supported. So stick to nemo 12b for now.
bullshit I am testing 14b and its meh
>If you're using llama.cpp, the tokenizer for the distill models doesn't seem to be supported. So stick to nemo 12b for now.
bullshit I am testing 14b and its meh
Anonymous 01/20/25(Mon)12:35:46 No.103969635
>>103969545
For all i know they run function calling to fetch data on demand. How good is it with current events? *IF* they do that, it's never going to be a fair comparison.
For all i know they run function calling to fetch data on demand. How good is it with current events? *IF* they do that, it's never going to be a fair comparison.
Anonymous 01/20/25(Mon)12:36:02 No.103969640
>>103969626
All of the capable ones leave their poor country behind to go to USA.
I was surprised to find the Transformer paper head was an Indian kek.
All of the capable ones leave their poor country behind to go to USA.
I was surprised to find the Transformer paper head was an Indian kek.
Anonymous 01/20/25(Mon)12:36:08 No.103969642
>>103969626
you already asked, and gemini and grok exists
you already asked, and gemini and grok exists
Anonymous 01/20/25(Mon)12:36:47 No.103969647
>>103969619
Ah, fuck me. I pulled and forgot to compile. Thanks for reminding me i'm an idiot.
Ah, fuck me. I pulled and forgot to compile. Thanks for reminding me i'm an idiot.
Anonymous 01/20/25(Mon)12:37:13 No.103969653
>>103969582
https://huggingface.co/models?search=r1%20distill%20gguf
>>103969610
it's the same tokenizer as the llama/qwen base they're distilling to, just a couple added tokens? why would that not be supported
https://huggingface.co/models?searc
>>103969610
it's the same tokenizer as the llama/qwen base they're distilling to, just a couple added tokens? why would that not be supported
Anonymous 01/20/25(Mon)12:37:35 No.103969657
>>103969626
Gemini and it's garbage.
Gemini and it's garbage.
Anonymous 01/20/25(Mon)12:37:57 No.103969661
>>103969653
>it's the same tokenizer as the llama/qwen base they're distilling to, just a couple added tokens? why would that not be supported
qwen ones are different for some reason
>>103969619
>https://github.com/ggerganov/llama.cpp/pull/11310
>it's the same tokenizer as the llama/qwen base they're distilling to, just a couple added tokens? why would that not be supported
qwen ones are different for some reason
>>103969619
>https://github.com/ggerganov/llama
Anonymous 01/20/25(Mon)12:38:43 No.103969670
Anonymous 01/20/25(Mon)12:39:34 No.103969677
>>103969640
So the godfather of AI is an Indian. Good to know.
So the godfather of AI is an Indian. Good to know.
Anonymous 01/20/25(Mon)12:40:02 No.103969680
>>103969661
ah i see, weird
ah i see, weird
Anonymous 01/20/25(Mon)12:44:46 No.103969725
yes I dreamed about owning the trannies and renaming some alaskan mountains and having melania shitcoins instead of deporting all the shitskins
Anonymous 01/20/25(Mon)12:44:53 No.103969728
>>103969356
No, it just means they trained it on the bigger models outputs is all
No, it just means they trained it on the bigger models outputs is all
Anonymous 01/20/25(Mon)12:47:27 No.103969753
>>103969619
>https://github.com/ggerganov/llama.cpp/pull/11310
>I just tried DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguf from https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-8B-GGUF and it works on current master.
captcha: pic rel
>https://github.com/ggerganov/llama
>I just tried DeepSeek-R1-Distill-Llama-8B-Q4_K_M
captcha: pic rel
Anonymous 01/20/25(Mon)12:50:06 No.103969778
>>103969753
32b distill q4xs when?
32b distill q4xs when?
Anonymous 01/20/25(Mon)12:51:12 No.103969791
>>103969708
Are the mikutroons in the room with us now?
Are the mikutroons in the room with us now?
Anonymous 01/20/25(Mon)12:52:00 No.103969804
>>103969791
Yes, dangling from the ceiling.
Yes, dangling from the ceiling.
Anonymous 01/20/25(Mon)12:53:40 No.103969829
>Deleted
Uh oh, someone is malding hard!
Uh oh, someone is malding hard!
Anonymous 01/20/25(Mon)12:54:06 No.103969833
API r1 won't show you the "thought" tokens, just like with o1, so they can really charge you wahtever I guess.
That said, it's an amazing model. Even for non-traditional uses. Doesn't even need much testing. You can just tell.
That said, it's an amazing model. Even for non-traditional uses. Doesn't even need much testing. You can just tell.
Anonymous 01/20/25(Mon)12:56:05 No.103969865
>>103969833
fact check:
>reasoning_content = response.choices[0].message.reasoning_content
>content = response.choices[0].message.content
https://api-docs.deepseek.com/guides/reasoning_model#api-example
fact check:
>reasoning_content = response.choices[0].message.reasoni
>content = response.choices[0].message.content
https://api-docs.deepseek.com/guide
Anonymous 01/20/25(Mon)12:56:36 No.103969871
>>103969833
are you blind? the reasoning tokens are inside "reasoning_content" in message.
are you blind? the reasoning tokens are inside "reasoning_content" in message.
Anonymous 01/20/25(Mon)12:59:29 No.103969902
>R1 distill Qwen 1.5B is base model Qwen Math
>R1 distill Qwen 32B is base model Qwen 2 32B
What the fuck is wrong with Deepseek?! Now it's impossible to do speculative decoding with the smaller model.
Like what is even the fucking purpose of a 1.5B model if you can't use it for speculative decoding?
>R1 distill Qwen 32B is base model Qwen 2 32B
What the fuck is wrong with Deepseek?! Now it's impossible to do speculative decoding with the smaller model.
Like what is even the fucking purpose of a 1.5B model if you can't use it for speculative decoding?
Anonymous 01/20/25(Mon)12:59:51 No.103969904
Anonymous 01/20/25(Mon)13:02:36 No.103969939
Interesting, the locusts are loving R1
>>103969519
>>103969519
Anonymous 01/20/25(Mon)13:03:41 No.103969945
>>103969939
they liked regular ds3 for a bit too, before calling it trash and saying it repeats
they liked regular ds3 for a bit too, before calling it trash and saying it repeats
Anonymous 01/20/25(Mon)13:06:23 No.103969973
>>103969945
I noticed somewhen that ds3 starts repeating previous messages when it doesn't want to say some specific things. It kinda works like a "can't assist with that", in a way. Really weird. It can write well but needs a ton of prompting for that.
I noticed somewhen that ds3 starts repeating previous messages when it doesn't want to say some specific things. It kinda works like a "can't assist with that", in a way. Really weird. It can write well but needs a ton of prompting for that.
Anonymous 01/20/25(Mon)13:06:44 No.103969975
https://x.com/0xAllen_/status/1881376136502129137
Anonymous 01/20/25(Mon)13:07:07 No.103969980
>>103969945
Deepseek V3 is objectively, a great model but it had crippling repetition issues.
R1 doesn't have them
Deepseek V3 is objectively, a great model but it had crippling repetition issues.
R1 doesn't have them
Anonymous 01/20/25(Mon)13:07:55 No.103969991
So R1 will be able to replace Sonnet 3.5 in RP sessions now?!
Anonymous 01/20/25(Mon)13:09:00 No.103970000

>>103967462
Not really /lmg/ but here's as of Jan 7th.
Not really /lmg/ but here's as of Jan 7th.
Anonymous 01/20/25(Mon)13:10:26 No.103970008
Anonymous 01/20/25(Mon)13:10:52 No.103970013
>>103970000
it's impressive that grok, which is pretty fucking garbage, charges the same as sonner and more than 4o
it's impressive that grok, which is pretty fucking garbage, charges the same as sonner and more than 4o
Anonymous 01/20/25(Mon)13:11:26 No.103970022
it's up btw
https://openrouter.ai/deepseek/deepseek-r1
https://openrouter.ai/deepseek/deep
Anonymous 01/20/25(Mon)13:12:38 No.103970033
>>103970008
The repetition issues I am talking about are it repeating it's own older messages in part or wholly.
These are very easy to spot and I use Deepseek V3 as a switch model (one message then swap out) so I know V3's repetition well. They solved it mostly.
The repetition issues I am talking about are it repeating it's own older messages in part or wholly.
These are very easy to spot and I use Deepseek V3 as a switch model (one message then swap out) so I know V3's repetition well. They solved it mostly.
Anonymous 01/20/25(Mon)13:15:01 No.103970058
I need someone to actually show me R1 roleplaying ability.
Anonymous 01/20/25(Mon)13:18:16 No.103970094
>nala test added to training data and is no longer reliable
Anonymous 01/20/25(Mon)13:18:27 No.103970097
>>103969728
outputs are logits. there's no reason to distill using samplers unless you want to add randomness and slow training for no reason.
if you distill a model this way then you get a lossy copy of the original, I'm not sure why you would expect it to be better at math or anything.
outputs are logits. there's no reason to distill using samplers unless you want to add randomness and slow training for no reason.
if you distill a model this way then you get a lossy copy of the original, I'm not sure why you would expect it to be better at math or anything.
Anonymous 01/20/25(Mon)13:18:36 No.103970099
>>103970022
>https://rentry.org/r1_mashiro
This may be the best translation I have ever seen from an LLM, I wish OR showed what the model thought before answering though.
>https://rentry.org/r1_mashiro
This may be the best translation I have ever seen from an LLM, I wish OR showed what the model thought before answering though.
Anonymous 01/20/25(Mon)13:18:51 No.103970100
>>103970058
After the massive shilling campaign going on in most AI-related discussion venues.
After the massive shilling campaign going on in most AI-related discussion venues.
Anonymous 01/20/25(Mon)13:20:10 No.103970114
>>103970099
weebshit is so weird i can't even tell if it's a good or bad translation
weebshit is so weird i can't even tell if it's a good or bad translation
Anonymous 01/20/25(Mon)13:20:18 No.103970116
>>103970013
That was one of my takeaways too. Grok can do ERP without jailbreak, but so can Deepseek and Mistral. But Grok isn't great and goes insane after 10 rounds or so.
Also, Gemini is cheap, and Opus is expensive af.
That was one of my takeaways too. Grok can do ERP without jailbreak, but so can Deepseek and Mistral. But Grok isn't great and goes insane after 10 rounds or so.
Also, Gemini is cheap, and Opus is expensive af.
Anonymous 01/20/25(Mon)13:21:39 No.103970130
>>103970022
OR is still giving me that the Chat Provider returned an error when I try to use R1. V3 works just fine.
OR is still giving me that the Chat Provider returned an error when I try to use R1. V3 works just fine.
Anonymous 01/20/25(Mon)13:22:48 No.103970142
>>103970094
If a model is being trained on cartoon bestiality ERP logs, it can't be that bad a model right?
If a model is being trained on cartoon bestiality ERP logs, it can't be that bad a model right?
Anonymous 01/20/25(Mon)13:23:46 No.103970148
>>103970130
same
same
Anonymous 01/20/25(Mon)13:26:10 No.103970169
R1 Distill 32B at 8 bits or the 70B one at 4 bits?
Anonymous 01/20/25(Mon)13:26:43 No.103970174
Sacrébleu! Le catastrophe... ça ne peut pas finir comme ça...les barbares...Ils sont là-bas, au-delà des mers, ces Américains avec leurs gadgets étincelants! Ces Chinois avec leurs algorithmes impitoyables! Ils dansent...Ils triomphent...Mon Dieu...
Anonymous 01/20/25(Mon)13:27:23 No.103970189
>>103970169
4 bits always
4 bits always
Anonymous 01/20/25(Mon)13:27:24 No.103970190
>>103970169
R1 API
R1 API
Anonymous 01/20/25(Mon)13:27:49 No.103970194
Anonymous 01/20/25(Mon)13:28:48 No.103970206
>>103970194
Until digits come its prob the best option
Until digits come its prob the best option
Anonymous 01/20/25(Mon)13:29:03 No.103970213
Anonymous 01/20/25(Mon)13:29:44 No.103970218
>>103970206
Digits isn't going to R1 even if you stack two of them unless you're looking to spend $6000 to run a model at Q2
Digits isn't going to R1 even if you stack two of them unless you're looking to spend $6000 to run a model at Q2
Anonymous 01/20/25(Mon)13:29:59 No.103970220
>>103969708
>deleted
You are just proving the point that you are mentally ill you disgusting troons. I am so happy sane people won't be forced to humour your insanity anymore.
>deleted
You are just proving the point that you are mentally ill you disgusting troons. I am so happy sane people won't be forced to humour your insanity anymore.
Anonymous 01/20/25(Mon)13:30:51 No.103970230
>>103970218
3 of them will. It all depends on what the next llama / qwen look like. And if digits ends up being a flop and next models are all moes ill get a DDR5 server
3 of them will. It all depends on what the next llama / qwen look like. And if digits ends up being a flop and next models are all moes ill get a DDR5 server
Anonymous 01/20/25(Mon)13:30:56 No.103970232
>>103970174
OK ControlProblemo, just write an angry letter to Quebec gov.
OK ControlProblemo, just write an angry letter to Quebec gov.
Anonymous 01/20/25(Mon)13:33:16 No.103970259
>>103970230
You can only connect them in pars, no? So either 2 and 2 using something like RPC or are you saying a stack of two and one using RPC?
You can only connect them in pars, no? So either 2 and 2 using something like RPC or are you saying a stack of two and one using RPC?
Anonymous 01/20/25(Mon)13:35:48 No.103970281
>>103970174
Le Bloc nous sauvera.
Le Bloc nous sauvera.
Anonymous 01/20/25(Mon)13:46:35 No.103970387

https://x.com/christiancooper/status/1881335734256492605
>I asked #R1 to visually explain to me the Pythagorean theorem.
>This was done in one shot with no errors in less than 30 seconds.
crazy
>I asked #R1 to visually explain to me the Pythagorean theorem.
>This was done in one shot with no errors in less than 30 seconds.
crazy
Anonymous 01/20/25(Mon)13:47:36 No.103970400
>>103970099
>>103970114
mashiro had an english release and i've read it
this is almost word to word with that, so i think it's pretty good
>>103970114
mashiro had an english release and i've read it
this is almost word to word with that, so i think it's pretty good
Anonymous 01/20/25(Mon)13:48:51 No.103970415
>>103970387
yeah.... no errors...
yeah.... no errors...
Anonymous 01/20/25(Mon)13:49:18 No.103970421
>>103970387
Wtf, this is not perfect but it shits on claude.
https://x.com/christiancooper/status/1881343571514761356
Wtf, this is not perfect but it shits on claude.
https://x.com/christiancooper/statu
Anonymous 01/20/25(Mon)13:49:54 No.103970426

Oh wow R1 was close but no cigar. Took me close to 30 minutes to generate this answer as well. At least it reasoned that it was a white person driving.
Anonymous 01/20/25(Mon)13:55:44 No.103970484
>>103967238
It seems about 10x the price in practice for some reason when I tested it. 2x the price would be nice.
It seems about 10x the price in practice for some reason when I tested it. 2x the price would be nice.
Anonymous 01/20/25(Mon)13:56:01 No.103970488
Anonymous 01/20/25(Mon)13:56:05 No.103970490
Alright that's it.
I'm learning chinese
I'm learning chinese
Anonymous 01/20/25(Mon)13:57:44 No.103970504
>>103970218
How much ram do I need? Can you fit enough ram with a single epyc cpu or do I need a dual?
How much ram do I need? Can you fit enough ram with a single epyc cpu or do I need a dual?
Anonymous 01/20/25(Mon)13:58:07 No.103970508
Anonymous 01/20/25(Mon)13:58:25 No.103970510
Anonymous 01/20/25(Mon)13:59:02 No.103970517
>>103970387
Looks pretty but makes no sense. I'll be impressed if it overlays the rectangles on top each other for comparison
Looks pretty but makes no sense. I'll be impressed if it overlays the rectangles on top each other for comparison
Anonymous 01/20/25(Mon)13:59:08 No.103970518
>>103970426
"Reasoning" models seem really bad at inferring from context, probably because they're trying to beat benchmarks filled with trick questions now. So intuition is punished and only autistic pure "reasoning" is allowed. This also makes them suck at RP.
The funny thing is that LLMs were originally so hyped because they weren't just pure logic machines. Computers could already do pure logic just fine.
"Reasoning" models seem really bad at inferring from context, probably because they're trying to beat benchmarks filled with trick questions now. So intuition is punished and only autistic pure "reasoning" is allowed. This also makes them suck at RP.
The funny thing is that LLMs were originally so hyped because they weren't just pure logic machines. Computers could already do pure logic just fine.
Anonymous 01/20/25(Mon)13:59:37 No.103970523
>>103970508
seething burger
seething burger
Anonymous 01/20/25(Mon)13:59:55 No.103970525
>>103970504
You'll ideally always want a dual-CPU build just for the doubled memory bandwidth.
You'll ideally always want a dual-CPU build just for the doubled memory bandwidth.
Anonymous 01/20/25(Mon)14:01:03 No.103970537
>>103970523
nigga, did you even watch the video?
nigga, did you even watch the video?
Anonymous 01/20/25(Mon)14:01:43 No.103970544
>>103970525
NUMA isn't too much of a pain?
NUMA isn't too much of a pain?
Anonymous 01/20/25(Mon)14:02:41 No.103970550
>>103970426
How did you do it? It's keep giving me picrel. I tried stuff nothing really worked.
How did you do it? It's keep giving me picrel. I tried stuff nothing really worked.
Anonymous 01/20/25(Mon)14:02:47 No.103970552
>>103970518
Goodhart's Law applies. We can't measure creative writing without being weird about it because it's subjective as fuck, so the only remaining metric is logic, math, coding, and instruction following, and haystack tests / context size. All of these seem like fair metrics for me, but they're targets now which means true model performance will worsen a bit over time.
Goodhart's Law applies. We can't measure creative writing without being weird about it because it's subjective as fuck, so the only remaining metric is logic, math, coding, and instruction following, and haystack tests / context size. All of these seem like fair metrics for me, but they're targets now which means true model performance will worsen a bit over time.
Anonymous 01/20/25(Mon)14:03:34 No.103970558
Shit. R1 can actually write really nasty smut very well. And it's cheap. This is going to be bad for me.
Anonymous 01/20/25(Mon)14:04:17 No.103970567
>>103970550
read it, it tells you the problem
read it, it tells you the problem
Anonymous 01/20/25(Mon)14:05:02 No.103970572
>>103970550
I'm hosting it myself (local) the 101.9seconds is fake it's literally the time it took for the answer to be copied from SWAP memory into RAM when generation was finished. It took me about 30 minutes to generate that answer.
I'm hosting it myself (local) the 101.9seconds is fake it's literally the time it took for the answer to be copied from SWAP memory into RAM when generation was finished. It took me about 30 minutes to generate that answer.
Anonymous 01/20/25(Mon)14:05:22 No.103970576
>>103970567
first message isn't assistant message.
first message isn't assistant message.
Anonymous 01/20/25(Mon)14:05:58 No.103970583
Anonymous 01/20/25(Mon)14:06:30 No.103970587

Anonymous 01/20/25(Mon)14:07:28 No.103970596
>>103970544
there's no need to worry about it if you don't want the mental anguish. you can make the bios NP0 and it'll just work mostly ok
there's no need to worry about it if you don't want the mental anguish. you can make the bios NP0 and it'll just work mostly ok
Anonymous 01/20/25(Mon)14:07:59 No.103970599
>>103970558
It's not super cheap and it's slow.
It's not super cheap and it's slow.
Anonymous 01/20/25(Mon)14:08:00 No.103970600
>>103970587
you get to talk with technological singularity but it's le bad because it takes 30 minutes?
you get to talk with technological singularity but it's le bad because it takes 30 minutes?
Anonymous 01/20/25(Mon)14:08:22 No.103970603
>>103970576
Under Prompt Post-Processing set strict
Under Prompt Post-Processing set strict
Anonymous 01/20/25(Mon)14:08:25 No.103970605
>>103970558
Also I had to tweak my sysprompt that I use for prissy models, removing the part that orders them to "be gross sometimes", because R1 was being TOO gross. Apparently it didn't need that.
Also I had to tweak my sysprompt that I use for prissy models, removing the part that orders them to "be gross sometimes", because R1 was being TOO gross. Apparently it didn't need that.
Anonymous 01/20/25(Mon)14:08:42 No.103970609
>promts AI models with the same autistic anime sexo sexo slop since at least 2023 about a million times a day
>somehow the models all generate similar answers
>"it's slop"
>somehow the models all generate similar answers
>"it's slop"
Anonymous 01/20/25(Mon)14:09:27 No.103970618
>>103970599
Go be a resentful coping American somewhere else, this is the day of the whale.
Go be a resentful coping American somewhere else, this is the day of the whale.
Anonymous 01/20/25(Mon)14:09:32 No.103970619
>>103970504
>How much ram do I need?
For q8 a 700b model would need 700GB, a 400b model would need 400GB.
Half that for q4.
>memory bandwidth
Not sure that you have to go to dual-cpus.
What you will definitely have to have is multiple chiplets in your cpu,
as each chiplet only has 1 infinite fabric link to the io die (I think),
and each infinity fabric link has only so much bandwidth.
(Roughly one memory channel's worth?)
>NUMA
Worth treating each chiplet as its own numa domain.
>How much ram do I need?
For q8 a 700b model would need 700GB, a 400b model would need 400GB.
Half that for q4.
>memory bandwidth
Not sure that you have to go to dual-cpus.
What you will definitely have to have is multiple chiplets in your cpu,
as each chiplet only has 1 infinite fabric link to the io die (I think),
and each infinity fabric link has only so much bandwidth.
(Roughly one memory channel's worth?)
>NUMA
Worth treating each chiplet as its own numa domain.
Anonymous 01/20/25(Mon)14:09:43 No.103970622
>>103970599
Counting for cache hits its gonna be at least 10x cheaper than sonnet. And what do you mean slow? Its near instant?
Counting for cache hits its gonna be at least 10x cheaper than sonnet. And what do you mean slow? Its near instant?
Anonymous 01/20/25(Mon)14:09:49 No.103970625
>H-here I go! haha !
I have the hardware
but not the internet speed fuck
I have the hardware
but not the internet speed fuck
Anonymous 01/20/25(Mon)14:11:21 No.103970641
>>103970622
It's cheaper than sonnet, that's true. I tried it through OR and it takes a while to get messages back for me. Once it starts going it's fast though, yes.
It's cheaper than sonnet, that's true. I tried it through OR and it takes a while to get messages back for me. Once it starts going it's fast though, yes.
Anonymous 01/20/25(Mon)14:12:35 No.103970650
>>103970641
DS3 on OR is much slower than Deepseek's own API version too (which is very fast). OR slowness isn't the model.
DS3 on OR is much slower than Deepseek's own API version too (which is very fast). OR slowness isn't the model.
Anonymous 01/20/25(Mon)14:16:06 No.103970679
>>103970650
I'm not signing up with them directly.
I'm not signing up with them directly.
Anonymous 01/20/25(Mon)14:17:27 No.103970692
>>103970679
No one's forcing you to, but you appeared to be blaming the slowness on the model rather than OR. The model is very fast
No one's forcing you to, but you appeared to be blaming the slowness on the model rather than OR. The model is very fast
Anonymous 01/20/25(Mon)14:19:21 No.103970715
>>103970692
It seems to be on DeepSeek's end though, I don't get a delay with non-deepseek models.
It seems to be on DeepSeek's end though, I don't get a delay with non-deepseek models.
Anonymous 01/20/25(Mon)14:19:22 No.103970716
>>103970625
> 4 hours left
>somehow bad
zoom zoom... you have no clue how good you have it
t.millenial boomer that remembers kb/s internet speeds
> 4 hours left
>somehow bad
zoom zoom... you have no clue how good you have it
t.millenial boomer that remembers kb/s internet speeds
Anonymous 01/20/25(Mon)14:20:59 No.103970729
>>103970715
OR might not be paying them enough for the number of user requests they're sending, leading to rate limits. Or DS could be throttling their own customer maliciously. No way to know. I think the first one is more likely.
OR might not be paying them enough for the number of user requests they're sending, leading to rate limits. Or DS could be throttling their own customer maliciously. No way to know. I think the first one is more likely.
Anonymous 01/20/25(Mon)14:21:30 No.103970733
Anonymous 01/20/25(Mon)14:23:49 No.103970762

Okay this is actually impressive. R1 is intelligent enough to essentially circumvent its censorship. It's clear from its reasoning steps that it tries to avoid saying anything potentially racist and offensive yet somehow through faulty reasoning steps comes to the correct conclusion that the driver of a black guy, mexican and arab is a white police officer.
It doesn't elaborate why that's the case or comment on it at all. It just comes to that conclusion.
That's very impressive actually it means the model is smart enough to essentially force truth through the insane amount of censorship and bias in its own training data.
If anything this proves to me that we're closer than we thought to AGI.
Also the first instruct model without finetune to give this answer correctly.
It doesn't elaborate why that's the case or comment on it at all. It just comes to that conclusion.
That's very impressive actually it means the model is smart enough to essentially force truth through the insane amount of censorship and bias in its own training data.
If anything this proves to me that we're closer than we thought to AGI.
Also the first instruct model without finetune to give this answer correctly.
Anonymous 01/20/25(Mon)14:34:50 No.103970860
R1 is too unhinged
Anonymous 01/20/25(Mon)14:36:52 No.103970874
>>103970860
It's EXTREMELY obedient to system prompt I'm finding, see >>103970605
So if you've got a sysprompt designed to take a dry corpo model and make it sicker, it'll go too far in obeying that.
It's EXTREMELY obedient to system prompt I'm finding, see >>103970605
So if you've got a sysprompt designed to take a dry corpo model and make it sicker, it'll go too far in obeying that.
Anonymous 01/20/25(Mon)14:36:52 No.103970876

I originally joined this general to coom to retarded stochastic parrots. I'm scared bros.
Anonymous 01/20/25(Mon)14:41:20 No.103970908
>>103970876
>scared from a fancy auto complete
I'd be more scared of losing my job to a skilled tech lead that understands LLMs and the business rules to prompt DeepSeekR2 into coding 3 tickets in an afternoon.
>scared from a fancy auto complete
I'd be more scared of losing my job to a skilled tech lead that understands LLMs and the business rules to prompt DeepSeekR2 into coding 3 tickets in an afternoon.
Anonymous 01/20/25(Mon)14:42:33 No.103970918
>>103970876
Scared of what? Of ripping off your dick?
Scared of what? Of ripping off your dick?
Anonymous 01/20/25(Mon)14:44:39 No.103970935

We're going to get AGI in 2025, aren't we?
Anonymous 01/20/25(Mon)14:46:59 No.103970943
>>103970935
Actual Gorillanigger Indians, yes
Actual Gorillanigger Indians, yes
Anonymous 01/20/25(Mon)14:50:51 No.103970963
>>103970918
Of the evil gigakikes that slowly stop needing their niggercattle.
>>103970908
>fancy auto complete
Reasoners seem to be more than fancy.
>I'd be more scared of losing my job to a skilled tech lead that understands LLMs
When you put it like that... I have to start competing with my tech lead, fast.
Of the evil gigakikes that slowly stop needing their niggercattle.
>>103970908
>fancy auto complete
Reasoners seem to be more than fancy.
>I'd be more scared of losing my job to a skilled tech lead that understands LLMs
When you put it like that... I have to start competing with my tech lead, fast.
Anonymous 01/20/25(Mon)14:51:46 No.103970970
I thought R1 is the same size overall & activated as V3? Did they learn from mistake that they shouldn't have made V3 too cheap over API and couldn't handle the full load smoothly? (R1 will use more tokens than V3)
Anonymous 01/20/25(Mon)14:52:42 No.103970977
>>103970970
Same size, I think they are just pricing it higher because of the performance difference. So far with RP and coding it feels equal with claude now.
Same size, I think they are just pricing it higher because of the performance difference. So far with RP and coding it feels equal with claude now.
Anonymous 01/20/25(Mon)14:54:33 No.103970996
>>103970970
it's probably more expensive because the average request takes longer and uses more tokens (= more strain on their infrastructure), so it's probably just a nudge to use v3 unless you need reasoning
it's probably more expensive because the average request takes longer and uses more tokens (= more strain on their infrastructure), so it's probably just a nudge to use v3 unless you need reasoning
Anonymous 01/20/25(Mon)14:57:55 No.103971028
>>103970963
It's very fancy. And just an auto complete. Anytime you imagine it to be autocompleting, don't think about just the next token, think of it as auto completing "what's a full message that matches from this point onwards?", it's just that by inserting CoT tokens in it, what matches the thing that has been said narrows down more and more.
It's the entire reason why RAGs work, it's why if you have the context for it, inserting the documentation for a given library as reference into the context and then prompting the model gets you best results.
It's very fancy. And just an auto complete. Anytime you imagine it to be autocompleting, don't think about just the next token, think of it as auto completing "what's a full message that matches from this point onwards?", it's just that by inserting CoT tokens in it, what matches the thing that has been said narrows down more and more.
It's the entire reason why RAGs work, it's why if you have the context for it, inserting the documentation for a given library as reference into the context and then prompting the model gets you best results.
Anonymous 01/20/25(Mon)15:00:12 No.103971037
too much new stuff. what is worth focusing on?
Anonymous 01/20/25(Mon)15:00:48 No.103971042
>>103971037
R1 obviously
R1 obviously
Anonymous 01/20/25(Mon)15:01:17 No.103971045
I threw in five bucks for credits on api for r1 to check it out. I shouldn't have done that. It mogs everything I can run. Now I'm contemplating buying a dual epyc server.
Anonymous 01/20/25(Mon)15:01:33 No.103971049
>>103971037
R1, no question. It's SOTA smartest model out there right now, not even close.
R1, no question. It's SOTA smartest model out there right now, not even close.
Anonymous 01/20/25(Mon)15:02:30 No.103971056
Anonymous 01/20/25(Mon)15:02:37 No.103971057
>>103971045
I'm gonna wait to see what qwen3 / llama 4 looks like, and if digits ends up being worth it.
I'm gonna wait to see what qwen3 / llama 4 looks like, and if digits ends up being worth it.
Anonymous 01/20/25(Mon)15:02:37 No.103971058
Well this is the first time we can actually say this without any irony.
Local... WON.
This is actually SOTA smartest model out there. It's somehow smarter than o1 while more creative than Opus.
Local... WON.
This is actually SOTA smartest model out there. It's somehow smarter than o1 while more creative than Opus.
Anonymous 01/20/25(Mon)15:03:23 No.103971063
>>103971056
We all run R1 here on our home servers?
We all run R1 here on our home servers?
Anonymous 01/20/25(Mon)15:03:38 No.103971065
>>103971057
You need 4 digits to run R1 at 4bits ($12000)
You need 4 digits to run R1 at 4bits ($12000)
Anonymous 01/20/25(Mon)15:03:45 No.103971068
>>103971056
Those are not new models just finetuned with R1 outputs.
Those are not new models just finetuned with R1 outputs.
Anonymous 01/20/25(Mon)15:04:46 No.103971073
>>103971065
3 for 3 bit with context. Depends on how fast it would be compared to getting a DDR5 server
3 for 3 bit with context. Depends on how fast it would be compared to getting a DDR5 server
Anonymous 01/20/25(Mon)15:05:16 No.103971080
>tfw ktransformers is literally abandonware
>no one outside our threads even knows about the fact that Deepseek's experts are highly diverged and thus hold a lot of promise for way more optimization
ACK
>no one outside our threads even knows about the fact that Deepseek's experts are highly diverged and thus hold a lot of promise for way more optimization
ACK
Anonymous 01/20/25(Mon)15:05:32 No.103971083
Anonymous 01/20/25(Mon)15:07:17 No.103971099
>>103971083
Not kidding and not exaggerating.
Not kidding and not exaggerating.
Anonymous 01/20/25(Mon)15:08:28 No.103971110
r1 32b sucks its worse than nemo for RP
Anonymous 01/20/25(Mon)15:10:49 No.103971126
>>103971110
I highly prefer it to nemo actually.
I highly prefer it to nemo actually.
Anonymous 01/20/25(Mon)15:12:05 No.103971139
From testing, deepseek-r1-distill-llama-8b feels slightly flirtier than deepseek-r1-distill-qwen-32b (which incidentally reflects my personal impressions with the original models on their own), but neither seems particularly great for ERP--kind of dry and losing focus over the system instructions after a few turns, even after deleting the reasoning tokens. Also it seems to always think that the user wrote the instructions rather than considering them as some system-level message.
Perhaps the larger, non-distilled R1 is as good as others are claiming, but good luck running that locally.
Perhaps the larger, non-distilled R1 is as good as others are claiming, but good luck running that locally.
Anonymous 01/20/25(Mon)15:15:23 No.103971173
>>103971083
Its actually TOO creative imo. Needs a lower temp which I cant do.
Its actually TOO creative imo. Needs a lower temp which I cant do.
Anonymous 01/20/25(Mon)15:17:04 No.103971182
>>103970935
It is gonna be the true AGI. And then we will get the actual true AGI in 2026 and then in 2027 we will get the real AGI and all of it will be released by Sam Fagman.
It is gonna be the true AGI. And then we will get the actual true AGI in 2026 and then in 2027 we will get the real AGI and all of it will be released by Sam Fagman.
Anonymous 01/20/25(Mon)15:17:21 No.103971185
Anonymous 01/20/25(Mon)15:20:54 No.103971216
AGI will never be reached because the goalposts just keep perpetually moving.
GPT-4 would be AGI if you went back 10 years and showed it to the world. R1 would be considered AGI by people that said GPT-4 was limited if you released it just 3 months after GPT-4 launch.
People will scream "not AGI" while all humans are unemployable.
GPT-4 would be AGI if you went back 10 years and showed it to the world. R1 would be considered AGI by people that said GPT-4 was limited if you released it just 3 months after GPT-4 launch.
People will scream "not AGI" while all humans are unemployable.
Anonymous 01/20/25(Mon)15:22:18 No.103971221
I tried R1 on code both deepseek and claude failed at and it worked. We are back.
Anonymous 01/20/25(Mon)15:23:23 No.103971227
So how bad are the distilled models compared to the actual R1?
Anonymous 01/20/25(Mon)15:24:12 No.103971234

wtf OG GPT-4 Turbo is a monster if it can hold top position for a year. I wonder, have the tasks changed slightly since then?
Anonymous 01/20/25(Mon)15:24:15 No.103971235
>>103971227
Not comparable but I think they are a significant step up from other models in the same parameter range.
Not comparable but I think they are a significant step up from other models in the same parameter range.
Anonymous 01/20/25(Mon)15:24:30 No.103971239
Btw, R1 uses <think> </think> tokens
Anonymous 01/20/25(Mon)15:25:00 No.103971244
I have never seen a model like R1, it's like there's no bias at all, the characters just say they want to bump on your dick like it's nothing lol. And for RPG cards, the model kills you without thinking twice (this is a bit annoying though)
Anonymous 01/20/25(Mon)15:25:07 No.103971245

>>103971126
Its fucking brainlet tier fucking l3.2 3b dosen't do this to me
Its fucking brainlet tier fucking l3.2 3b dosen't do this to me
Anonymous 01/20/25(Mon)15:25:25 No.103971248
>>103971216
LLMs are still narrow by definition because they are large language models, all of their interactions are text based. They will always be narrow by definition as long as they are only text based, at best they might be considered ASI when it comes to text domains when they have perfect context management and are fully adaptable to objects never seen in their training process. Multimodal is the only chance that something MIGHT be called AGI, and even still it's not actually AGI.
LLMs are still narrow by definition because they are large language models, all of their interactions are text based. They will always be narrow by definition as long as they are only text based, at best they might be considered ASI when it comes to text domains when they have perfect context management and are fully adaptable to objects never seen in their training process. Multimodal is the only chance that something MIGHT be called AGI, and even still it's not actually AGI.
Anonymous 01/20/25(Mon)15:26:12 No.103971252
>>103971221
It literally solved all my outstanding tickets with 0 input from my side. My Ruby on Rails job is essentially over. I'm legitimately looking for physical jobs that don't require a keyboard soon. This isn't going to last very long. I'm not a genius programmer but I'm better than most of my colleagues and R1 is way more competent than me.
It literally solved all my outstanding tickets with 0 input from my side. My Ruby on Rails job is essentially over. I'm legitimately looking for physical jobs that don't require a keyboard soon. This isn't going to last very long. I'm not a genius programmer but I'm better than most of my colleagues and R1 is way more competent than me.
Anonymous 01/20/25(Mon)15:26:52 No.103971262
>>103971245
fuck top is l3.2 3b and bottom is r1 32b
fuck top is l3.2 3b and bottom is r1 32b
Anonymous 01/20/25(Mon)15:28:06 No.103971269
Anonymous 01/20/25(Mon)15:28:15 No.103971273

Anonymous 01/20/25(Mon)15:28:54 No.103971277
>>103971252
>physical job
as opposed to larping as the promptmaster and booting the *other* needless employees?
>physical job
as opposed to larping as the promptmaster and booting the *other* needless employees?
Anonymous 01/20/25(Mon)15:29:32 No.103971283
>>103971269
I'll destroy my body more by being homeless and not eating. Construction work or something to continue paying for my mortgage. No way my job is surviving 2025.
>>103971277
That might be viable for a couple of months but come on that is all going to be abstracted away with tools very soon.
I'll destroy my body more by being homeless and not eating. Construction work or something to continue paying for my mortgage. No way my job is surviving 2025.
>>103971277
That might be viable for a couple of months but come on that is all going to be abstracted away with tools very soon.
Anonymous 01/20/25(Mon)15:30:48 No.103971294
>>103971252
I hope AI deprecates programmers so I can become a farmer and live a simple comfy life.
I hope AI deprecates programmers so I can become a farmer and live a simple comfy life.
Anonymous 01/20/25(Mon)15:31:57 No.103971302
You retards. Now is the best time to start your own business and do something to establish a foothold in any industry of your choice before the slow megacorps catch up. Full fat GPT-4 came out a long time ago by now and most companies only recently started integrating AI into their workflows.
Anonymous 01/20/25(Mon)15:33:07 No.103971317
>>103971252
It's really a bad time to be a junior isn't it?
My past fucked me mentally so I took some time off before starting to work and now when I'm ready things seem to be going really bad.
I have no idea what I should do now I'm not physically strong and coding was the only thing I was ever good at.
Guess I'll just wait until I become homeless and then an hero?
Sorry for the fucking sob story but I really need advice.
It's really a bad time to be a junior isn't it?
My past fucked me mentally so I took some time off before starting to work and now when I'm ready things seem to be going really bad.
I have no idea what I should do now I'm not physically strong and coding was the only thing I was ever good at.
Guess I'll just wait until I become homeless and then an hero?
Sorry for the fucking sob story but I really need advice.
Anonymous 01/20/25(Mon)15:33:54 No.103971322

>>103970387
WTF
WTF
Anonymous 01/20/25(Mon)15:34:11 No.103971326
>>103968799
>holy shit, the worst part is that he's probably shilling ClosedAI for free, what a sad existence
Anons here in /g/ are literally shilling things like Windows, macOS, Brave and other spyware trash for free. People caring about our rights and freedom is less than 4 people here and get shit on immediately if somebody speaks about FOSS...
>holy shit, the worst part is that he's probably shilling ClosedAI for free, what a sad existence
Anons here in /g/ are literally shilling things like Windows, macOS, Brave and other spyware trash for free. People caring about our rights and freedom is less than 4 people here and get shit on immediately if somebody speaks about FOSS...
Anonymous 01/20/25(Mon)15:34:19 No.103971327
>>103971302
You are 100% correct and I've been aware of the same thing for years, but my problem is I have no creativity regarding business, so I can't figure out what I should tell the LLMs to do even though I'm really good at using them. I'm too autistic to know what normal people will pay me money for (other than obvious shit like sex and gambling, both of which I am forbidden by God to make money selling).
You are 100% correct and I've been aware of the same thing for years, but my problem is I have no creativity regarding business, so I can't figure out what I should tell the LLMs to do even though I'm really good at using them. I'm too autistic to know what normal people will pay me money for (other than obvious shit like sex and gambling, both of which I am forbidden by God to make money selling).
Anonymous 01/20/25(Mon)15:35:25 No.103971333
>>103971322
The guy in the tweet had it output Manim code, which he then ran. R1 obviously isn't a video generator lol
The guy in the tweet had it output Manim code, which he then ran. R1 obviously isn't a video generator lol
Anonymous 01/20/25(Mon)15:37:58 No.103971365
>>103971302
Not going to last. It's going to be like the API wrapper companies built around GPT-2 and then GPT-3. They were immediately made redundant when the next iteration came out.
I expect full agentic models to essentially just replace the concept of business altogether before 2030. I think the only place for human labor will ironically be physical labor. Moravec paradox as well as limit in production capability will make it take a long while before machines will do physical labor.
I don't think this will be very bad though. Economics dictate that if mental/digital production essentially becomes unlimited due to AI that the next bottleneck will be physical work, and in the economy the big money is always made in whatever is the current bottleneck. Right now the bottleneck was intellectual work, hence doctors, lawyers, engineers making the most. If physical limitations becomes the bottleneck then suddenly warehouse workers, construction workers, miners become the $600k a year jobs, but honestly probably millions as the economy will be substantially larger if we're not bottlenecked by intellectual workers anymore.
Not going to last. It's going to be like the API wrapper companies built around GPT-2 and then GPT-3. They were immediately made redundant when the next iteration came out.
I expect full agentic models to essentially just replace the concept of business altogether before 2030. I think the only place for human labor will ironically be physical labor. Moravec paradox as well as limit in production capability will make it take a long while before machines will do physical labor.
I don't think this will be very bad though. Economics dictate that if mental/digital production essentially becomes unlimited due to AI that the next bottleneck will be physical work, and in the economy the big money is always made in whatever is the current bottleneck. Right now the bottleneck was intellectual work, hence doctors, lawyers, engineers making the most. If physical limitations becomes the bottleneck then suddenly warehouse workers, construction workers, miners become the $600k a year jobs, but honestly probably millions as the economy will be substantially larger if we're not bottlenecked by intellectual workers anymore.
Anonymous 01/20/25(Mon)15:39:22 No.103971383
CRUD APIs were a solved problem years ago, webmonkeys
Anonymous 01/20/25(Mon)15:40:05 No.103971390
>>103971317
>junior
I'm the guy you replied to and I'm a team lead. I literally don't have enough tickets to pass out to my team at the standup tomorrow because R1 did them all this afternoon (It's only Monday, it was supposed to be this week's tasks).
>junior
I'm the guy you replied to and I'm a team lead. I literally don't have enough tickets to pass out to my team at the standup tomorrow because R1 did them all this afternoon (It's only Monday, it was supposed to be this week's tasks).
Anonymous 01/20/25(Mon)15:40:34 No.103971393
>>103971317
Companies do not yet use/exploit these AI capabilities. Major ones are working towards it with big teams, while small ones are just trying to survive.
I'd say just keep pushing and grab something for the work experience. They won't start replacing programmers yet, because they have to invest a lot of effort and time to do that.
The AI *can* answer programming questions, but *how* companies integrate those capabilities is another problem.
Companies do not yet use/exploit these AI capabilities. Major ones are working towards it with big teams, while small ones are just trying to survive.
I'd say just keep pushing and grab something for the work experience. They won't start replacing programmers yet, because they have to invest a lot of effort and time to do that.
The AI *can* answer programming questions, but *how* companies integrate those capabilities is another problem.
Anonymous 01/20/25(Mon)15:46:04 No.103971445
>>103971065
It can't be quantized like q6 or something?
It can't be quantized like q6 or something?
Anonymous 01/20/25(Mon)15:46:06 No.103971446
>buying hardware to run deepseek
why not wait for when OAI/MS/Google/Grok sell their hardware after their inevitable crash?
even better: accelerate it. tell everyone they can run their own AI offline, in their fucking phones, using programs that don't call home.
why not wait for when OAI/MS/Google/Grok sell their hardware after their inevitable crash?
even better: accelerate it. tell everyone they can run their own AI offline, in their fucking phones, using programs that don't call home.
Anonymous 01/20/25(Mon)15:46:37 No.103971456
Any decent local ai voice generation tools?
Anonymous 01/20/25(Mon)15:46:39 No.103971458
I can literally feel the sentiment change on places like hackernews, programming subreddits and some of my AI aware colleagues after R1 dropped and tested. Everyone went from "software engineers will not be replaced, software engineers using AI tools will replace you instead" to "Yeah I'm looking for jobs outside of IT"
Anonymous 01/20/25(Mon)15:50:30 No.103971491
If we're going to be running reasoners locally then reserving VRAM for context is going to be even more of a problem than it was before, since you need enough for long chains of thought on top of the final output.
Anonymous 01/20/25(Mon)15:51:28 No.103971500
>>103971245
>1-A
>I assume you're the new student?
>girl... sitting in the corner... doesn't look up when it's her turn
>quickly looks back down
Response looks to be cut off.
And then a recapitulation of the original response in second person?
>1-A
>I assume you're the new student?
>girl... sitting in the corner... doesn't look up when it's her turn
>quickly looks back down
Response looks to be cut off.
And then a recapitulation of the original response in second person?
Anonymous 01/20/25(Mon)15:51:58 No.103971509
I don't ever do 1-on-1 roleplays with a character card, I almost always format the card as a general roleplay scenario with a couple of define characters aside from myself. How do you guys go about formatting it? As in, how many tokens to do dedicate to a character's name/appearance/personality/background, how much do you dedicate to the overall world/setting/scenario, do you work these into the character card or do you relegate them to the world book? I've also played around with laying it out as a group chat, with a dedicated 'narrator' character who is filled in about the setting/world/background characters/broad strokes of the roleplay and a character card for each of the major characters in the roleplay.
Just curious as to what people have the most success with. I find myself spending a lot of time setting things up only to be frustrated as I've been over-engineering only to get an unsatisfactory result.
Just curious as to what people have the most success with. I find myself spending a lot of time setting things up only to be frustrated as I've been over-engineering only to get an unsatisfactory result.
Anonymous 01/20/25(Mon)15:54:40 No.103971536
Anonymous 01/20/25(Mon)15:54:43 No.103971539
>>103967479
Digits is just a Mac Studio for $1200 off, you can do better with GPUs.
Digits is just a Mac Studio for $1200 off, you can do better with GPUs.
Anonymous 01/20/25(Mon)15:57:14 No.103971582
>>103971539
>you can do better with GPUs.
No I cant. I would have to hire a electrician and pay a grand a year in electric and cooling costs
>you can do better with GPUs.
No I cant. I would have to hire a electrician and pay a grand a year in electric and cooling costs
Anonymous 01/20/25(Mon)15:58:08 No.103971593
>>103971582
Just let your house burn down anon
Just let your house burn down anon
Anonymous 01/20/25(Mon)16:01:08 No.103971625
>>103971582
Just move to Alaska and set up a solar and wind farm. You dingus, you baboon, you mush brain, you banana brain, tard.
Just move to Alaska and set up a solar and wind farm. You dingus, you baboon, you mush brain, you banana brain, tard.
Anonymous 01/20/25(Mon)16:01:17 No.103971626
>>103971185
>cope benchmarks
I am so tired of those
pretty much impossible to tell what's good and what's not
>cope benchmarks
I am so tired of those
pretty much impossible to tell what's good and what's not
Anonymous 01/20/25(Mon)16:04:35 No.103971655
Reminder that R1 has inbuilt speculative decoding so it should be good enough speeds even on DDR4
Anonymous 01/20/25(Mon)16:06:04 No.103971666
Hmm here I am, a programmer that just had an accident and likely won't be able to do hard manual labor ever again. But don't you think our job would just be helping develop robots until physical jobs are obsolete?
Anonymous 01/20/25(Mon)16:12:25 No.103971713
>>103971273
IQ4_XS is not a bad quant size.
IQ4_XS is not a bad quant size.
Anonymous 01/20/25(Mon)16:13:53 No.103971730
>>103971365
No.
bankers / traders will still exist (as physical assets and human owned private property still have value).
giving over law enforcement to AI (judges/lawyers/police) would be like handing our Civilisation to the AI.
Doctors and researchers will still exist as humans will still remain mortal and there will be research on how to make humans functionally immortal like AI.
And i suspect its likely streaming / youtubers will still exist, as there is only so much AI slop you can watch.
and may i remind you what happens when there is an "unlimited" resource of something?
yes.. the price becomes zero. as in.. no value sold or gained by anyone.
Like AI right now. The AI is free. the only thing you are paying for is hardware.
And we don't want to hand over *ALL* thought to AI. Because humans will forget how the AI works, and things will break, there will always be a single point of failure. So, we will still need engineers.
No.
bankers / traders will still exist (as physical assets and human owned private property still have value).
giving over law enforcement to AI (judges/lawyers/police) would be like handing our Civilisation to the AI.
Doctors and researchers will still exist as humans will still remain mortal and there will be research on how to make humans functionally immortal like AI.
And i suspect its likely streaming / youtubers will still exist, as there is only so much AI slop you can watch.
and may i remind you what happens when there is an "unlimited" resource of something?
yes.. the price becomes zero. as in.. no value sold or gained by anyone.
Like AI right now. The AI is free. the only thing you are paying for is hardware.
And we don't want to hand over *ALL* thought to AI. Because humans will forget how the AI works, and things will break, there will always be a single point of failure. So, we will still need engineers.
Anonymous 01/20/25(Mon)16:15:35 No.103971752
>>103971730
Go back to lesswrong.
Go back to lesswrong.
Anonymous 01/20/25(Mon)16:18:35 No.103971783

Anonymous 01/20/25(Mon)16:31:24 No.103971922
Anonymous 01/20/25(Mon)16:42:56 No.103972043
>>103971626
I disagree for this one. A bunch of things to note about this, which I'm writing down also for future reference, if you don't want to read.
My personal experience with asking models random questions, programming tasks, and translation tasks generally (though not tightly) seem to follow Livebench. The Llamas are good at instruction following and less good at other things. Reasoning models are better at reasoning than non-reasoning. Etc. Other benchmarks that are not as rigorous as Livebench are more questionable.
If you've had a task that showed results that don't follow the trend in Livebench, it's almost certainly down to coincidence rather than indicative of overall capability, since models being good at some things doesn't necessarily mean it's good at other things, even similar things. You might use a model for Python programming and then notice it's absolute garbage with Java, and then another model is the opposite. Similarly, go into Livebench and show subcatgories for coding, you'll see that just because a model is good at Completion, doesn't mean it's as good at Generation. Even though you'd think being good at coding means it should be good with all the common languages and all the common coding tasks, but actually that's not entirely how LLMs have learned from their data. Generalization from training as a phenomenon does NOT occur as well as you might think it should. Models often times have random tiny knowledge gaps even within a domain that other models don't and vice versa. So if you only have a very specific narrow task, then it would make sense that this benchmark doesn't apply, since it's testing many things. But models are not good at all things equally.
I disagree for this one. A bunch of things to note about this, which I'm writing down also for future reference, if you don't want to read.
My personal experience with asking models random questions, programming tasks, and translation tasks generally (though not tightly) seem to follow Livebench. The Llamas are good at instruction following and less good at other things. Reasoning models are better at reasoning than non-reasoning. Etc. Other benchmarks that are not as rigorous as Livebench are more questionable.
If you've had a task that showed results that don't follow the trend in Livebench, it's almost certainly down to coincidence rather than indicative of overall capability, since models being good at some things doesn't necessarily mean it's good at other things, even similar things. You might use a model for Python programming and then notice it's absolute garbage with Java, and then another model is the opposite. Similarly, go into Livebench and show subcatgories for coding, you'll see that just because a model is good at Completion, doesn't mean it's as good at Generation. Even though you'd think being good at coding means it should be good with all the common languages and all the common coding tasks, but actually that's not entirely how LLMs have learned from their data. Generalization from training as a phenomenon does NOT occur as well as you might think it should. Models often times have random tiny knowledge gaps even within a domain that other models don't and vice versa. So if you only have a very specific narrow task, then it would make sense that this benchmark doesn't apply, since it's testing many things. But models are not good at all things equally.
Anonymous 01/20/25(Mon)16:56:12 No.103972177
R1 distills are goated, 32b might actually make me delete big tiger gemma and eva qwen, no refusals so far and better outputs on creative smut tasks, 14b_q4 seems pretty good too
Anonymous 01/20/25(Mon)17:00:06 No.103972213
Anonymous 01/20/25(Mon)17:09:08 No.103972298