/lmg/ - Local Models General
Anonymous 01/20/25(Mon)15:53:24 | 578 comments | 65 images | 🔒 Locked

/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>103967199 & >>103959928
►News
>(01/20) DeepSeek releases R1, R1 Zero, & finetuned Qwen and Llama models: https://hf.co/deepseek-ai/DeepSeek-R1-Zero
>(01/17) Nvidia AceInstruct, finetuned on Qwen2.5-Base: https://hf.co/nvidia/AceInstruct-72B
>(01/16) OuteTTS-0.3 released with voice cloning & punctuation support: https://hf.co/collections/OuteAI/outetts-03-6786b1ebc7aeb757bc17a2fa
>(01/15) InternLM3-8B-Instruct released with deep thinking capability: https://hf.co/internlm/internlm3-8b-instruct
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/tldrhowtoquant
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/leaderboard.html
Code Editing: https://aider.chat/docs/leaderboards
Context Length: https://github.com/hsiehjackson/RULER
Japanese: https://hf.co/datasets/lmg-anon/vntl-leaderboard
Censorbench: https://codeberg.org/jts2323/censorbench
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
Previous threads: >>103967199 & >>103959928
►News
>(01/20) DeepSeek releases R1, R1 Zero, & finetuned Qwen and Llama models: https://hf.co/deepseek-ai/DeepSeek-
>(01/17) Nvidia AceInstruct, finetuned on Qwen2.5-Base: https://hf.co/nvidia/AceInstruct-72
>(01/16) OuteTTS-0.3 released with voice cloning & punctuation support: https://hf.co/collections/OuteAI/ou
>(01/15) InternLM3-8B-Instruct released with deep thinking capability: https://hf.co/internlm/internlm3-8b
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWeb
https://rentry.org/tldrhowtoquant
►Further Learning
https://rentry.org/machine-learning
https://rentry.org/llm-training
https://rentry.org/LocalModelsPaper
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/lea
Code Editing: https://aider.chat/docs/leaderboard
Context Length: https://github.com/hsiehjackson/RUL
Japanese: https://hf.co/datasets/lmg-anon/vnt
Censorbench: https://codeberg.org/jts2323/censor
GPUs: https://github.com/XiongjieDai/GPU-
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngl
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-M
Sampler Visualizer: https://artefact2.github.io/llm-sam
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-g
https://github.com/LostRuins/kobold
https://github.com/ggerganov/llama.
https://github.com/theroyallab/tabb
https://github.com/vllm-project/vll
Anonymous 01/20/25(Mon)15:53:39 No.103971526

►Recent Highlights from the Previous Thread: >>103967199
--DeepSeek-R1 and coding capabilities discussion:
>103969007 >103969017 >103969244 >103969350 >103969451 >103969484 >103969486 >103969513 >103969495 >103969515 >103969545 >103969635 >103969383 >103969406 >103969343
--R1 model capabilities and temperature adjustment discussion:
>103967680 >103967689 >103967721 >103967728 >103967690 >103967702 >103967706 >103967715 >103967726 >103967703 >103967709 >103967711
--Deepseek model pricing and API cost discussion:
>103967238 >103967251 >103967442 >103967462 >103967725 >103967734 >103967851 >103967952 >103970000 >103970116 >103970484
--Distilled models' limitations in problem-solving and potential of RL:
>103968000 >103968203 >103968545
--Impressive LLM-generated narrative continuation:
>103967517 >103967537 >103967927
--Generating non-reasoning data with DeepSeek-V3 pipeline:
>103967221
--DeepSeek R1's roleplay and writing capabilities:
>103969399 >103969489
--Anon suggests using Group Relative Policy Optimization in RP models, referencing DeepSeek's approach:
>103969265
--LLaMA tokenizer changes and their implications:
>103967984
--Impressive 32b model performance on coding benchmarks:
>103967639 >103967642 >103967654 >103967724 >103967747 >103967767 >103967784 >103967812 >103967808 >103968227
--R1's Pythagorean theorem explanation underwhelms anons:
>103970387 >103970421 >103970488 >103970517 >103971333
--Discussion about the legitimacy and quality of distills:
>103967973 >103967982 >103968030 >103968052
--Distilled models' performance and limitations discussed:
>103969152 >103969298 >103969356 >103969728 >103970097 >103969326 >103969341
--Anon discusses finetuning a model and its potential performance:
>103969344 >103969371 >103969374 >103969391
--Miku (free space):
>103967591 >103967757
►Recent Highlight Posts from the Previous Thread: >>103967200
Why?: 9 reply limit >>102478518
Fix: https://rentry.org/lmg-recap-script
--DeepSeek-R1 and coding capabilities discussion:
>103969007 >103969017 >103969244 >103969350 >103969451 >103969484 >103969486 >103969513 >103969495 >103969515 >103969545 >103969635 >103969383 >103969406 >103969343
--R1 model capabilities and temperature adjustment discussion:
>103967680 >103967689 >103967721 >103967728 >103967690 >103967702 >103967706 >103967715 >103967726 >103967703 >103967709 >103967711
--Deepseek model pricing and API cost discussion:
>103967238 >103967251 >103967442 >103967462 >103967725 >103967734 >103967851 >103967952 >103970000 >103970116 >103970484
--Distilled models' limitations in problem-solving and potential of RL:
>103968000 >103968203 >103968545
--Impressive LLM-generated narrative continuation:
>103967517 >103967537 >103967927
--Generating non-reasoning data with DeepSeek-V3 pipeline:
>103967221
--DeepSeek R1's roleplay and writing capabilities:
>103969399 >103969489
--Anon suggests using Group Relative Policy Optimization in RP models, referencing DeepSeek's approach:
>103969265
--LLaMA tokenizer changes and their implications:
>103967984
--Impressive 32b model performance on coding benchmarks:
>103967639 >103967642 >103967654 >103967724 >103967747 >103967767 >103967784 >103967812 >103967808 >103968227
--R1's Pythagorean theorem explanation underwhelms anons:
>103970387 >103970421 >103970488 >103970517 >103971333
--Discussion about the legitimacy and quality of distills:
>103967973 >103967982 >103968030 >103968052
--Distilled models' performance and limitations discussed:
>103969152 >103969298 >103969356 >103969728 >103970097 >103969326 >103969341
--Anon discusses finetuning a model and its potential performance:
>103969344 >103969371 >103969374 >103969391
--Miku (free space):
>103967591 >103967757
►Recent Highlight Posts from the Previous Thread: >>103967200
Why?: 9 reply limit >>102478518
Fix: https://rentry.org/lmg-recap-script
Anonymous 01/20/25(Mon)15:55:52 No.103971551
Mikulove
Anonymous 01/20/25(Mon)15:56:06 No.103971558
deepseek love
Anonymous 01/20/25(Mon)15:56:08 No.103971559
>>103971509
>I don't ever do 1-on-1 roleplays with a character card, I almost always format the card as a general roleplay scenario with a couple of define characters aside from myself. How do you guys go about formatting it? As in, how many tokens to do dedicate to a character's name/appearance/personality/background, how much do you dedicate to the overall world/setting/scenario, do you work these into the character card or do you relegate them to the world book? I've also played around with laying it out as a group chat, with a dedicated 'narrator' character who is filled in about the setting/world/background characters/broad strokes of the roleplay and a character card for each of the major characters in the roleplay.
Just curious as to what people have the most success with. I find myself spending a lot of time setting things up only to be frustrated as I've been over-engineering only to get an unsatisfactory result.
>I don't ever do 1-on-1 roleplays with a character card, I almost always format the card as a general roleplay scenario with a couple of define characters aside from myself. How do you guys go about formatting it? As in, how many tokens to do dedicate to a character's name/appearance/personality/backgro
Just curious as to what people have the most success with. I find myself spending a lot of time setting things up only to be frustrated as I've been over-engineering only to get an unsatisfactory result.
Anonymous 01/20/25(Mon)15:56:32 No.103971566

First for R1 is the first model that actually solved this racist riddle out of pure reasoning. The model is smart enough to fight against its own censorship baked into its weights to actually give the correct answer.
Anonymous 01/20/25(Mon)15:56:54 No.103971574

>>103971551
sorry I've got a new gf
sorry I've got a new gf
Anonymous 01/20/25(Mon)15:57:59 No.103971592
So is R1 32B any good for erp or is it just good for coding?
Anonymous 01/20/25(Mon)15:58:17 No.103971597
>>103971566
>The model is smart enough to fight against its own censorship baked into its weights to actually give the correct answer.
SAM'S GONNA FREAK
>The model is smart enough to fight against its own censorship baked into its weights to actually give the correct answer.
SAM'S GONNA FREAK
Anonymous 01/20/25(Mon)15:59:37 No.103971614
>*The camera lingers on Ren’s thick cock pulsing inside her, each thrust squelching loudly as Kana’s whimpers sync with the squeak of her bedsprings. Close-up on his balls slapping her clit, pre-cum oozing down her inner thighs. "Gonna… fill your dumb little assignment," he grunts, yanking her hair to arch her back. The iPhone captures every drop as he erupts, ropes of cum painting her cervix, some dribbling onto the homework sheet below. Post-nut clarity hits—Ren freezes. "Shit. Mom’s gonna smell this."*
KINOKINOKINOKINO
KINOKINOKINOKINO
Anonymous 01/20/25(Mon)16:00:47 No.103971621
>>103971574
Sex with whales...
Sex with whales...
Anonymous 01/20/25(Mon)16:00:53 No.103971623
>>103971592
It's very good for ERP if you need the characters to have good reasoning/logic or if you do weird spatial stuff that needs some logic. It's bad for the usual (boring) prose anime shit that most people here engage in.
It's very good for ERP if you need the characters to have good reasoning/logic or if you do weird spatial stuff that needs some logic. It's bad for the usual (boring) prose anime shit that most people here engage in.
Anonymous 01/20/25(Mon)16:02:06 No.103971630
>>103971523
what kind of workstation do i need to run Deepseek R1? Will a 4090 handle it at 64k?
what kind of workstation do i need to run Deepseek R1? Will a 4090 handle it at 64k?
Anonymous 01/20/25(Mon)16:06:12 No.103971667
>>103971393
>The AI *can* answer programming questions, but *how* companies integrate those capabilities is another problem.
Easy. Most companies use MS Teams/Slack for communication anyways, just replace workers with AI that the managers can talk to like real employees.
>The AI *can* answer programming questions, but *how* companies integrate those capabilities is another problem.
Easy. Most companies use MS Teams/Slack for communication anyways, just replace workers with AI that the managers can talk to like real employees.
Anonymous 01/20/25(Mon)16:07:23 No.103971674
>>103971667
I think you just described Scale and Devin.
I think you just described Scale and Devin.
Anonymous 01/20/25(Mon)16:12:31 No.103971715
>>103971667
So managers are actually accountable for their work? No way!
Each company is different, but there's a reason why they pay "consultants" big bucks to "modernize" their business... (with suboptimal results)
So managers are actually accountable for their work? No way!
Each company is different, but there's a reason why they pay "consultants" big bucks to "modernize" their business... (with suboptimal results)
Anonymous 01/20/25(Mon)16:13:54 No.103971731
Shoutout /lmg/ anons who have guided me.
I feel like I got transfered back to my youth, roleplaying AOL chatrooms.
I have a single 3090 and 128gb of ram, and have been using Gemma 2-27b-it-Q6_K. I'm not sure if this is the ideal model for my setup but I have been having a lot of fun. RPing generally works pretty well, but I havent experimented with ERP much because it seems to fall apart after a dozen messages and go schizo.
I feel like I got transfered back to my youth, roleplaying AOL chatrooms.
I have a single 3090 and 128gb of ram, and have been using Gemma 2-27b-it-Q6_K. I'm not sure if this is the ideal model for my setup but I have been having a lot of fun. RPing generally works pretty well, but I havent experimented with ERP much because it seems to fall apart after a dozen messages and go schizo.
Anonymous 01/20/25(Mon)16:17:27 No.103971774
>>103971623
So, is it like QwQ, then?
So, is it like QwQ, then?
Anonymous 01/20/25(Mon)16:20:17 No.103971794
>>103971774
Yeah but way superior to QwQ while also less robotic in normal LLM prose, just not as good as other models at that.
Yeah but way superior to QwQ while also less robotic in normal LLM prose, just not as good as other models at that.
Anonymous 01/20/25(Mon)16:23:30 No.103971825
>>103971731
Which model and quant are you running on that setup?
Which model and quant are you running on that setup?
Anonymous 01/20/25(Mon)16:23:36 No.103971829
>>103971794
Sounds amazing. I have been craving logical, intelligent, instruction following models for RP, that can also write decently well.
Sounds amazing. I have been craving logical, intelligent, instruction following models for RP, that can also write decently well.
Anonymous 01/20/25(Mon)16:24:14 No.103971842
R1 seems to like DnD when you tell it you want to simulate a role-playing game. It even simulates die rolls and corruption.
I tested how truly random the rolls were.. and they're not random (likes 9 and 3 a too much) but they're not so deterministic either. This can be solved by giving it a salt and make it do calculations (burning token count), but it's still interesting. Even more because I still haven't found the usual places where the LLM tends to default to (like Lily for female name).
I tested how truly random the rolls were.. and they're not random (likes 9 and 3 a too much) but they're not so deterministic either. This can be solved by giving it a salt and make it do calculations (burning token count), but it's still interesting. Even more because I still haven't found the usual places where the LLM tends to default to (like Lily for female name).
Anonymous 01/20/25(Mon)16:24:28 No.103971843
whats the meta now
Anonymous 01/20/25(Mon)16:24:38 No.103971844
>>103971523
whats the best model right now for a single 3090/4090?
I'm still on command-r don't know if there is anything better
whats the best model right now for a single 3090/4090?
I'm still on command-r don't know if there is anything better
Anonymous 01/20/25(Mon)16:25:08 No.103971852
Anonymous 01/20/25(Mon)16:28:32 No.103971887
Are they just larping or why would R1 suddenly make programmers fear for their job when it's not better than o1 and worse than o3?
Anonymous 01/20/25(Mon)16:28:58 No.103971890
I know everyone is gonna be running R1 now but the Qwen 32B R1 is actually really fucking good at coding now. Like near sonnet level not kidding
Anonymous 01/20/25(Mon)16:30:28 No.103971907
>>103971890
Did you compare with the llama3.3 one?
Did you compare with the llama3.3 one?
Anonymous 01/20/25(Mon)16:31:07 No.103971917
>>103971907
Not yet, is it better?
Not yet, is it better?
Anonymous 01/20/25(Mon)16:34:02 No.103971948

>>103971523
>(01/16) OuteTTS-0.3 released with voice cloning & punctuation support
anyone tested it? What the max sentence size you can generate? I don't see it mentioned on the page.
StyleTTS2 was trained only on 300 character sentences, XTTSv2 on only 250. I'm wondering if OuteTTS will finally be the first viable TTS for generating audiobooks.
>(01/16) OuteTTS-0.3 released with voice cloning & punctuation support
anyone tested it? What the max sentence size you can generate? I don't see it mentioned on the page.
StyleTTS2 was trained only on 300 character sentences, XTTSv2 on only 250. I'm wondering if OuteTTS will finally be the first viable TTS for generating audiobooks.
Anonymous 01/20/25(Mon)16:34:07 No.103971950
>>103971887
Even if it's actually retarded, the internal monologing it does makes it seem way less retarded than juniors copying pasting chatgpt.
Even if it's actually retarded, the internal monologing it does makes it seem way less retarded than juniors copying pasting chatgpt.
Anonymous 01/20/25(Mon)16:35:06 No.103971959
>>103971917
Don't know, I only tried out llama because it's trained on the finetune and I like 3.3s more than Qwens
Don't know, I only tried out llama because it's trained on the finetune and I like 3.3s more than Qwens
Anonymous 01/20/25(Mon)16:36:53 No.103971977
>oh I'm using R1
Which ones you fucking idiots?
Which ones you fucking idiots?
Anonymous 01/20/25(Mon)16:37:51 No.103971988
>>103971977
R1 is R1, if I meant Qwen I would say so
R1 is R1, if I meant Qwen I would say so
Anonymous 01/20/25(Mon)16:41:44 No.103972034
>>103971988
No you would say R1 Qwen
No you would say R1 Qwen
Anonymous 01/20/25(Mon)16:41:58 No.103972035
>>103971977
bartowski normally doesn't disappoint
https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF
bartowski normally doesn't disappoint
https://huggingface.co/bartowski/De
Anonymous 01/20/25(Mon)16:42:47 No.103972041
>>103971842
>I tested how truly random the rolls were.. and they're not random (likes 9 and 3 a too much)
That's one of those things that I see as something LLMs don't need to be good at.
For example, I play D&D with gemini and I use its code execution capabilities to roll dice. I also have it always roll an "Entropy Dice" to steer the scenarios and such.
My point being, tool calling makes it so that LLMs that are intelligent enough to know what to do can do math without error, generate (semi-) random numbers, gather external information, etc, by calling external tools.
To me that's the coolest thing about current LLMs, that they can do that at all and by interfacing with these external systems they are become much more capable than they'd be otherwise.
>I tested how truly random the rolls were.. and they're not random (likes 9 and 3 a too much)
That's one of those things that I see as something LLMs don't need to be good at.
For example, I play D&D with gemini and I use its code execution capabilities to roll dice. I also have it always roll an "Entropy Dice" to steer the scenarios and such.
My point being, tool calling makes it so that LLMs that are intelligent enough to know what to do can do math without error, generate (semi-) random numbers, gather external information, etc, by calling external tools.
To me that's the coolest thing about current LLMs, that they can do that at all and by interfacing with these external systems they are become much more capable than they'd be otherwise.
Anonymous 01/20/25(Mon)16:44:22 No.103972057
192GB + 24GBvram+ can run R1 2bit btw
Anonymous 01/20/25(Mon)16:44:28 No.103972058
>>103972041
Fuck, even the name thing could be remedied with tool calling. Train it to call a function that searches a name database for a semi-random name given certain parameters, or the like.
Basically, everything that can be offloaded to a more precise system outside the LLM that the LLM can use by itself makes the LLM more capable.
Fuck, even the name thing could be remedied with tool calling. Train it to call a function that searches a name database for a semi-random name given certain parameters, or the like.
Basically, everything that can be offloaded to a more precise system outside the LLM that the LLM can use by itself makes the LLM more capable.
Anonymous 01/20/25(Mon)16:45:19 No.103972066
>>103971887
Unironically, with the right information in the context and the right explanation of what I'm looking for, o1 already implements and develops correctly anything I'm looking for as part of my development tickets. Already. Now. I usually have it implement everything I need and then snooze for the next 3 days pretending I'm working, thanks WFH.
People severely underestimate the power of prompting correctly, that huge elo in codeforces is not a waste nor accident, it's just that codeforce problems are as clear as they get and you need to do some legwork in understanding what you need as part of your requirements to reach that level of clear description that the model requires, and then you just ask for it.
Never used O3 tho. I imagine it's overkill.
Unironically, with the right information in the context and the right explanation of what I'm looking for, o1 already implements and develops correctly anything I'm looking for as part of my development tickets. Already. Now. I usually have it implement everything I need and then snooze for the next 3 days pretending I'm working, thanks WFH.
People severely underestimate the power of prompting correctly, that huge elo in codeforces is not a waste nor accident, it's just that codeforce problems are as clear as they get and you need to do some legwork in understanding what you need as part of your requirements to reach that level of clear description that the model requires, and then you just ask for it.
Never used O3 tho. I imagine it's overkill.
Anonymous 01/20/25(Mon)16:46:04 No.103972071
>>103971844
Deepseek R1 Distilled 32b
Deepseek R1 Distilled 32b
Anonymous 01/20/25(Mon)16:47:05 No.103972079
>>103972035
I'm downloading that right now in Q5_K_M
I'm downloading that right now in Q5_K_M
Anonymous 01/20/25(Mon)16:47:07 No.103972080
R1 isn't very good for RP...
Anonymous 01/20/25(Mon)16:47:51 No.103972091
>>103971948
It's LLM based. 4096 tokens or about a minute iirc
It's LLM based. 4096 tokens or about a minute iirc
Anonymous 01/20/25(Mon)16:47:59 No.103972092
>>103972080
I hope your talking about a distilled one cause the big boy is the best I have ever used for RP
I hope your talking about a distilled one cause the big boy is the best I have ever used for RP
Anonymous 01/20/25(Mon)16:48:59 No.103972099
>>103972092
You fuck horses, don't you?
You fuck horses, don't you?
Anonymous 01/20/25(Mon)16:50:03 No.103972111
>>103972099
anime girls
anime girls
Anonymous 01/20/25(Mon)16:50:19 No.103972116
How the fuck do I remove samplers from chat completion presets in Sillytavern? I'm trying to use the Deepseek API but it keeps telling me that it's not compatible with presence_penalty. I'm not able to remove that though. I already tried to disable it by value.
Anonymous 01/20/25(Mon)16:50:51 No.103972121

>>103971948
Doesn't support more than 1200 tokens I think.
Also, why not use Kokoro or GPT-Sovits?
>>103971842
LLMs aren't RNGs... They literally predict the most likely token based on their training data.
That's the opposite definition of random.
Doesn't support more than 1200 tokens I think.
Also, why not use Kokoro or GPT-Sovits?
>>103971842
LLMs aren't RNGs... They literally predict the most likely token based on their training data.
That's the opposite definition of random.
Anonymous 01/20/25(Mon)16:51:11 No.103972124
>>103971842
Couldn't you force it to write {{random: 1, 2, ...}} ?
Couldn't you force it to write {{random: 1, 2, ...}} ?
Anonymous 01/20/25(Mon)16:51:26 No.103972131
>>103972116
https://github.com/SillyTavern/SillyTavern/commit/d7bb92be540d17d28e4f1c0c0bdec95d2525045a
https://github.com/SillyTavern/Sill
Anonymous 01/20/25(Mon)16:51:39 No.103972135
>>103972057
What speeds are you getting?
What speeds are you getting?
Anonymous 01/20/25(Mon)16:52:48 No.103972141
Anonymous 01/20/25(Mon)16:54:31 No.103972161
>>103972041
that's true but R1 doesn't have function calling
>>103972058
i mean, it's true that the name can be solved like that. But I was just exemplifying. LLMs tend to default in more subtle ways. Best known here is the "shivers down the spine", but they can also be character personalities or story events
that's true but R1 doesn't have function calling
>>103972058
i mean, it's true that the name can be solved like that. But I was just exemplifying. LLMs tend to default in more subtle ways. Best known here is the "shivers down the spine", but they can also be character personalities or story events
Anonymous 01/20/25(Mon)16:54:42 No.103972162

wow
Anonymous 01/20/25(Mon)16:54:49 No.103972163

Anonymous 01/20/25(Mon)16:55:37 No.103972169
https://desuarchive.org/g/search/width/697/height/768
Anonymous 01/20/25(Mon)16:56:07 No.103972175
>>103972121
>LLMs aren't RNGs... They literally predict the most likely token based on their training data.
I had to test it, given that temperature isn't supported and the LLM liked to roll dice kek
>LLMs aren't RNGs... They literally predict the most likely token based on their training data.
I had to test it, given that temperature isn't supported and the LLM liked to roll dice kek
Anonymous 01/20/25(Mon)16:56:28 No.103972184
>>103971948
It sounds like shit and the voice cloning barely works. Pointless model when GPT-SoVITS exists.
It sounds like shit and the voice cloning barely works. Pointless model when GPT-SoVITS exists.
Anonymous 01/20/25(Mon)16:56:33 No.103972185
>>103972162
I don't know what that means.
I don't know what that means.
Anonymous 01/20/25(Mon)16:57:06 No.103972187
>>103972184
Buy an ad
Buy an ad
Anonymous 01/20/25(Mon)16:57:28 No.103972189

https://x.com/Kimi_ai_/status/1881332472748851259
A SECOND (or is it third after Qwen's QwQ?) Chinese o1 level LLM released today. KIMI AI
A SECOND (or is it third after Qwen's QwQ?) Chinese o1 level LLM released today. KIMI AI
Anonymous 01/20/25(Mon)16:58:53 No.103972201
>>103972124
When you ask for a random number without specifying how to get it the model "reasons" it has to use python code. Then starts thinking how the python "random" function works, then picks a "random" number and that's it.
When you ask it with a seed and don't specify how to generate the number, it chooses "randomly" a method and applies the technique to the salt doing the math itself.
When you ask for a random number without specifying how to get it the model "reasons" it has to use python code. Then starts thinking how the python "random" function works, then picks a "random" number and that's it.
When you ask it with a seed and don't specify how to generate the number, it chooses "randomly" a method and applies the technique to the salt doing the math itself.
Anonymous 01/20/25(Mon)16:59:09 No.103972203
>>103972189
Weights?
Weights?
Anonymous 01/20/25(Mon)17:00:11 No.103972216
Anonymous 01/20/25(Mon)17:00:16 No.103972218
Anonymous 01/20/25(Mon)17:00:32 No.103972223
I told you everyone was waiting till after biden gets out.
Anonymous 01/20/25(Mon)17:01:29 No.103972229
HmmmmMMMM, wondering about jumping back into AI coom what with the R1 hype. Would have to run distilled though
Anonymous 01/20/25(Mon)17:01:31 No.103972230
>>103972223
Everyone hated Biden. Why did people vote for him in the first place?
Everyone hated Biden. Why did people vote for him in the first place?
Anonymous 01/20/25(Mon)17:02:56 No.103972236
Anonymous 01/20/25(Mon)17:03:12 No.103972239
p102-100 still the meta poorfag card?
Anonymous 01/20/25(Mon)17:03:34 No.103972241
Does R1 qwen work with ollama?
Anonymous 01/20/25(Mon)17:03:48 No.103972243
Would it be stupid if i created a virtual environment and use symbolic links for all AI tools?
Having one "global" virtual environment would be more convenient than each AI tool having their own.
Having one "global" virtual environment would be more convenient than each AI tool having their own.
Anonymous 01/20/25(Mon)17:04:00 No.103972246
>>103972241
Go back
Go back
Anonymous 01/20/25(Mon)17:05:35 No.103972265
Anonymous 01/20/25(Mon)17:06:53 No.103972275
>>103972230
They didn't. They got 20 million fake votes went to him. Those vote didnt show up for Kamala when everyone scrutinized the voting booth numbers.
They didn't. They got 20 million fake votes went to him. Those vote didnt show up for Kamala when everyone scrutinized the voting booth numbers.
Anonymous 01/20/25(Mon)17:07:03 No.103972278
>>103972223
Chinks are everyone?
Chinks are everyone?
Anonymous 01/20/25(Mon)17:08:10 No.103972285
>>103972241
ollama's website provides a search function..
ollama's website provides a search function..
Anonymous 01/20/25(Mon)17:08:51 No.103972294
You hear that? It's the sound of locusts swarming. Keep your bug spray with you at all times for the next few days.
Anonymous 01/20/25(Mon)17:08:52 No.103972296
>>103972278
Rub those 2 braincells together and come up with a reason why. Hint: Bidens anti ai executive order
Rub those 2 braincells together and come up with a reason why. Hint: Bidens anti ai executive order
Anonymous 01/20/25(Mon)17:09:50 No.103972305
>>103972241
You can literally write a model file yourself to add any model you want.
https://github.com/ollama/ollama/blob/main/docs/modelfile.md
You can literally write a model file yourself to add any model you want.
https://github.com/ollama/ollama/bl
Anonymous 01/20/25(Mon)17:10:25 No.103972310
>>103972121
>Also, why not use Kokoro or GPT-Sovits?
never heard of them, but i can't find any info on max output length either, guess i'll have to test all 3 of them, thanks
>>103972184
i don't care about voice cloning as long as there's any listenable pretrained voice included. Short output length is by far the biggest issue i have with TTS models.
So far i had to split sentences by commas to fit in 250/300 character limit to prevent the model from dropping the rest of the sentence, but obviously it doesn't sound good, since now a lot of sentences are read as 2 separate ones.
>Also, why not use Kokoro or GPT-Sovits?
never heard of them, but i can't find any info on max output length either, guess i'll have to test all 3 of them, thanks
>>103972184
i don't care about voice cloning as long as there's any listenable pretrained voice included. Short output length is by far the biggest issue i have with TTS models.
So far i had to split sentences by commas to fit in 250/300 character limit to prevent the model from dropping the rest of the sentence, but obviously it doesn't sound good, since now a lot of sentences are read as 2 separate ones.
Anonymous 01/20/25(Mon)17:10:48 No.103972315
>>103972296
Bitch the chinks released DS3 and even Hunyuan which is arguably just as if not more of a controversial release than r1. You'd literally use any evidence of people releasing things to point towards your argument being valid.
Also the chinks don't give a shit about Biden's order, they can find ways around that shit, it's just a little less convenient.
Bitch the chinks released DS3 and even Hunyuan which is arguably just as if not more of a controversial release than r1. You'd literally use any evidence of people releasing things to point towards your argument being valid.
Also the chinks don't give a shit about Biden's order, they can find ways around that shit, it's just a little less convenient.
Anonymous 01/20/25(Mon)17:11:35 No.103972325
>>103971630
https://rentry.org/miqumaxx
https://rentry.org/miqumaxx
Anonymous 01/20/25(Mon)17:11:53 No.103972329
>>103972315
And then Biden went full hog and slapped the entire world with sanctions and a "if you sell GPUs to china we will come after you."
And then Biden went full hog and slapped the entire world with sanctions and a "if you sell GPUs to china we will come after you."
Anonymous 01/20/25(Mon)17:12:09 No.103972330
>>103972243
the point of a virtual environment is isolating incompatible versions of libraries. you can always try the oldschool thing of rawdogging library conflicts.
the point of a virtual environment is isolating incompatible versions of libraries. you can always try the oldschool thing of rawdogging library conflicts.
Anonymous 01/20/25(Mon)17:13:10 No.103972340
R1 makes me realize that unaligned models are scary... I want the comfy positivity bias back...
Anonymous 01/20/25(Mon)17:14:22 No.103972356
>>103972340
the fuck are you talking about. R1 still has safety bias
the fuck are you talking about. R1 still has safety bias
Anonymous 01/20/25(Mon)17:14:22 No.103972357
>>103972329
The chinks can still find ways around that regardless. This is why every country laughs at the US now (and some even 30 years ago), they think their policies are effectual. Lmao.
The chinks can still find ways around that regardless. This is why every country laughs at the US now (and some even 30 years ago), they think their policies are effectual. Lmao.
Anonymous 01/20/25(Mon)17:14:36 No.103972360
>>103972340
Explain please
Explain please
Anonymous 01/20/25(Mon)17:15:25 No.103972367
>>103972356
Your crazy. Or you dont have any context.
Your crazy. Or you dont have any context.
Anonymous 01/20/25(Mon)17:16:21 No.103972373
not gonna lie bros r1 distill mixed in my llama 3.3 merge is looking pretty tasty in preliminary tests... just the sort of exotic ingredient I was craving
slopperbros we won
slopperbros we won
Anonymous 01/20/25(Mon)17:17:19 No.103972380
>mememerges
Anonymous 01/20/25(Mon)17:17:30 No.103972382
>>103972357
Why are you trying so hard to defend Biden?
Why are you trying so hard to defend Biden?
Anonymous 01/20/25(Mon)17:19:47 No.103972405

>>103971574
>>103971621
I don't know whales, but there's extensive public record on fucking dolphins.
In fact, female dolphins gets crazy for human cock once tried.
>>103971621
I don't know whales, but there's extensive public record on fucking dolphins.
In fact, female dolphins gets crazy for human cock once tried.
Anonymous 01/20/25(Mon)17:20:03 No.103972406
WHY BOTHER TRAINING A MODEL WHEN YOU CAN GENERATE THEM?!
https://nus-hpc-ai-lab.github.io/Recurrent-Parameter-Generation/
https://nus-hpc-ai-lab.github.io/Re
Anonymous 01/20/25(Mon)17:25:08 No.103972449
>>103972406
i love it. this is the most schizo sounding premise i've seen.
>click the paper link
>it just goes to "https://arxiv.org/"
i love it. this is the most schizo sounding premise i've seen.
>click the paper link
>it just goes to "https://arxiv.org/"
Anonymous 01/20/25(Mon)17:26:13 No.103972453
>>103972367
the safety bias is what allows the model to think about character's personalities and wishes, what's consensual and what isn't. If a character slaps someone's ass, the model *will* think it was not consensual even in an fantasy erotic setting
not only that. For other topics, it asks itself about it's "content policy" before answering. And if you don't steer it strong enough, it will question the ethics and morals of what you request
It's still far better than everything else, and you can steer the model away from it, but the safety bias is still there and in part is what makes the model usable
the safety bias is what allows the model to think about character's personalities and wishes, what's consensual and what isn't. If a character slaps someone's ass, the model *will* think it was not consensual even in an fantasy erotic setting
not only that. For other topics, it asks itself about it's "content policy" before answering. And if you don't steer it strong enough, it will question the ethics and morals of what you request
It's still far better than everything else, and you can steer the model away from it, but the safety bias is still there and in part is what makes the model usable
Anonymous 01/20/25(Mon)17:29:07 No.103972471
>>103972405
Which model does the best dolphin fucking descriptions?
Which model does the best dolphin fucking descriptions?
Anonymous 01/20/25(Mon)17:29:12 No.103972472
Anonymous 01/20/25(Mon)17:29:45 No.103972480
>>103972406
I was thinking about this a while ago. We know that the brain has certain specific structures that are essentially just preprogrammed or primed for certain connections. So we should in theory be able to also do that for language models, we just need to find the structures that LLM parameters would have encoded. Or we could let a model learn it. There is the issue that for some things like simple facts, there may not be a specific location or structure, but at least we should be able to do it for things like spatial understanding certainly, short-term memory (context) handling maybe, locations for different large groups of knowledge, etc. Then we can use the predicted model as initialization to continue pretraining on.
I was thinking about this a while ago. We know that the brain has certain specific structures that are essentially just preprogrammed or primed for certain connections. So we should in theory be able to also do that for language models, we just need to find the structures that LLM parameters would have encoded. Or we could let a model learn it. There is the issue that for some things like simple facts, there may not be a specific location or structure, but at least we should be able to do it for things like spatial understanding certainly, short-term memory (context) handling maybe, locations for different large groups of knowledge, etc. Then we can use the predicted model as initialization to continue pretraining on.
Anonymous 01/20/25(Mon)17:31:20 No.103972491
Use the r1 qwen to continue my story.
"Alright, let's break down the situation and figure out how to proceed.
Understanding the Current State:"
Lists a bunch of shit on the different things about the story, doesn't continue the fucking story.
The fuck is wrong with these models?
"Alright, let's break down the situation and figure out how to proceed.
Understanding the Current State:"
Lists a bunch of shit on the different things about the story, doesn't continue the fucking story.
The fuck is wrong with these models?
Anonymous 01/20/25(Mon)17:33:26 No.103972516
>>103972305
ollama's internal lcpp is likely not updated for the deepseek-r1-qwen tokenizer yet
https://github.com/ggerganov/llama.cpp/pull/11310
ollama's internal lcpp is likely not updated for the deepseek-r1-qwen tokenizer yet
https://github.com/ggerganov/llama.
Anonymous 01/20/25(Mon)17:34:05 No.103972524
>>103972491
Are you using the <think> and </think> tags?
Are you using the <think> and </think> tags?
Anonymous 01/20/25(Mon)17:34:09 No.103972526
Anonymous 01/20/25(Mon)17:35:05 No.103972530
Anonymous 01/20/25(Mon)17:36:11 No.103972540
>>103972480
Anthropic wrote a whole thing about mapping LLMs: https://www.anthropic.com/news/mapping-mind-language-model
>>103972491
When I was testing it on an auto-complete task, it kept doing the COT thing. When I switched to RP, it wouldn't do it even when I tried.
Anthropic wrote a whole thing about mapping LLMs: https://www.anthropic.com/news/mapp
>>103972491
When I was testing it on an auto-complete task, it kept doing the COT thing. When I switched to RP, it wouldn't do it even when I tried.
Anonymous 01/20/25(Mon)17:36:26 No.103972542

anon that picked F to simple bench question 6
Anonymous 01/20/25(Mon)17:39:02 No.103972561
>>103972239
p40 has 24gb and is roughly $260 atm?
p40 has 24gb and is roughly $260 atm?
Anonymous 01/20/25(Mon)17:41:02 No.103972579

I don't get this analogy, am I dumb or is this nonsense?
Anonymous 01/20/25(Mon)17:41:35 No.103972585
>>103972540
Anthropic only mapped location but not structure. And only on a single layer.
>Understanding the representations the model uses doesn't tell us how it uses them; even though we have the features, we still need to find the circuits they are involved in.
Anthropic only mapped location but not structure. And only on a single layer.
>Understanding the representations the model uses doesn't tell us how it uses them; even though we have the features, we still need to find the circuits they are involved in.
Anonymous 01/20/25(Mon)17:44:17 No.103972618
>>103972526
What is the problem?
What is the problem?
Anonymous 01/20/25(Mon)17:45:34 No.103972628
>>103972579
She's right. No god would use 'boku' unless it is the god of betas.
She's right. No god would use 'boku' unless it is the god of betas.
Anonymous 01/20/25(Mon)17:48:48 No.103972671
>>103972579
I don't speak Jap but it's saying ga is pretentious, then makes fun of you by saying if you were to call yourself god then you're not one solidly but a "I'm one too" kind as you are bedridden.
I don't speak Jap but it's saying ga is pretentious, then makes fun of you by saying if you were to call yourself god then you're not one solidly but a "I'm one too" kind as you are bedridden.
Anonymous 01/20/25(Mon)17:52:48 No.103972700
>>103972516
And it won't be anytime soon for what I'm seeing, or is it a "nightly branch" somewhere?
And it won't be anytime soon for what I'm seeing, or is it a "nightly branch" somewhere?
Anonymous 01/20/25(Mon)17:55:04 No.103972722
>>103972671
I understand that much, I just don't understand how what she wrote explains the difference between ga and wa. What the hell is the point of a shadow admitting to being married to the light? The only thing I can think of is that it's meaningless. So boku ga is pretentious and boku wa is meaningless?
I understand that much, I just don't understand how what she wrote explains the difference between ga and wa. What the hell is the point of a shadow admitting to being married to the light? The only thing I can think of is that it's meaningless. So boku ga is pretentious and boku wa is meaningless?
Anonymous 01/20/25(Mon)17:57:32 No.103972743
>>103972722
Ah, that part. Sounds like creative bs to me too idk sorry.
Ah, that part. Sounds like creative bs to me too idk sorry.
Anonymous 01/20/25(Mon)17:57:53 No.103972748
LMG... I... kneel
Anonymous 01/20/25(Mon)18:00:08 No.103972775
Retard here, how do you connect R1 to ST? It keeps getting confused, I think it might be the instruction template? Do you have custom rulesets/lorebooks to help it do more than just keep breaking down the scene and never getting to a response?
Anonymous 01/20/25(Mon)18:01:08 No.103972781
>>103972775
https://github.com/SillyTavern/SillyTavern/commit/d7bb92be540d17d28e4f1c0c0bdec95d2525045a
https://github.com/SillyTavern/Sill
Anonymous 01/20/25(Mon)18:01:57 No.103972797
Anonymous 01/20/25(Mon)18:06:40 No.103972848
IT'S NOT FAIR. I WANT TO RUN R1 AT HOME.
Anonymous 01/20/25(Mon)18:06:53 No.103972852
R1 is a coomtune
Anonymous 01/20/25(Mon)18:11:24 No.103972884
ggoof of distilled needs some loader update doesn't it? I keep trying to load with ooba and kobold and it dies.
Anonymous 01/20/25(Mon)18:12:24 No.103972897
>>103972884
distilled qwen yeah, kobold supports it on the latest experimental
distilled qwen yeah, kobold supports it on the latest experimental
Anonymous 01/20/25(Mon)18:12:52 No.103972902
>>103972884
They use a different tokenizer with added <think> </think> tokens
They use a different tokenizer with added <think> </think> tokens
Anonymous 01/20/25(Mon)18:16:24 No.103972937
>>103972472
How are you going to regulate it when it can be downloaded and run?
How are you going to regulate it when it can be downloaded and run?
Anonymous 01/20/25(Mon)18:17:50 No.103972950
>>103972781
Does that work just through their api or OR as well?
Does that work just through their api or OR as well?
Anonymous 01/20/25(Mon)18:23:00 No.103973002
Has anyone had a chance to mess around with the 70B and 32B R1 tunes?
How do they perform in comparison to the real deal?
How do they perform in comparison to the real deal?
Anonymous 01/20/25(Mon)18:24:13 No.103973009
>>103973002
32B is best local coder by FAR. And that is with apparently the wrong tokenizer.
32B is best local coder by FAR. And that is with apparently the wrong tokenizer.
Anonymous 01/20/25(Mon)18:24:18 No.103973010
>>103972781
Thank you anon
Thank you anon
Anonymous 01/20/25(Mon)18:25:26 No.103973025
Anonymous 01/20/25(Mon)18:25:32 No.103973027
>>103973002
32B is okayish, 70B is great. Neither get even closer to be as good as the real deal though.
32B is okayish, 70B is great. Neither get even closer to be as good as the real deal though.
Anonymous 01/20/25(Mon)18:25:51 No.103973029
>>103973002
Certainly better than the base counterpart, but doesn't really hold a candle to the real R1. I mean it's kind of hard to compete 70b vs 700b.
Certainly better than the base counterpart, but doesn't really hold a candle to the real R1. I mean it's kind of hard to compete 70b vs 700b.
Anonymous 01/20/25(Mon)18:26:27 No.103973032
>>103973009
Yeah but 32B is not 70B and 70B doesnt make the retarded mistakes a 32B does by virtue of being a 32B. Even if a 32B initially scores higher on a coding bench how am I to be sure it won't forget kimiko is wearing panties like a 70B wont?
Yeah but 32B is not 70B and 70B doesnt make the retarded mistakes a 32B does by virtue of being a 32B. Even if a 32B initially scores higher on a coding bench how am I to be sure it won't forget kimiko is wearing panties like a 70B wont?
Anonymous 01/20/25(Mon)18:27:15 No.103973038
>>103973032
I guess but qwen means 128K context which is important for coding imo
I guess but qwen means 128K context which is important for coding imo
Anonymous 01/20/25(Mon)18:31:01 No.103973064
>>103971948
>>103972310
Stock voices can only generate 30 seconds long output files.
Fish Speech 1.5 can generate 1 minute long output files.
Sample:
https://vocaroo.com/1aY0CErPJFlr
ElevenLabs Reader app is free to use. You can use screen copy to record the audio
https://github.com/Genymobile/scrcpy
Sample:
https://vocaroo.com/153tQ51pbEpN
>>103972310
Stock voices can only generate 30 seconds long output files.
Fish Speech 1.5 can generate 1 minute long output files.
Sample:
https://vocaroo.com/1aY0CErPJFlr
ElevenLabs Reader app is free to use. You can use screen copy to record the audio
https://github.com/Genymobile/scrcp
Sample:
https://vocaroo.com/153tQ51pbEpN
Anonymous 01/20/25(Mon)18:32:44 No.103973083
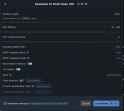
Is this as smart as the model DeepSeek is running in the chat?
Anonymous 01/20/25(Mon)18:33:50 No.103973094
Anonymous 01/20/25(Mon)18:34:26 No.103973102
>>103973083
What is the system requirements for running this?
What is the system requirements for running this?
Anonymous 01/20/25(Mon)18:35:30 No.103973113
Where did all these retards come from?
Anonymous 01/20/25(Mon)18:35:48 No.103973115
How do you guys use servicetensor (serious software) now that model cards no longer say how to prompt stuff and have prompting built into them?
Anonymous 01/20/25(Mon)18:36:17 No.103973122
>>103973083
qwen 32B R1 is just qwen trained on outputs from R1. Also 700B vs 32B
qwen 32B R1 is just qwen trained on outputs from R1. Also 700B vs 32B
Anonymous 01/20/25(Mon)18:37:06 No.103973135
>>103973115
models have the template embedded
models have the template embedded
Anonymous 01/20/25(Mon)18:37:13 No.103973137
>>103973113
tons of hype on twitter and youtube
tons of hype on twitter and youtube
Anonymous 01/20/25(Mon)18:37:55 No.103973146
>>103973115
Just read the model's config files nigga.
Just read the model's config files nigga.
Anonymous 01/20/25(Mon)18:38:29 No.103973153
>>103973115
llama.cpp tells you the prompt format on startup
llama.cpp tells you the prompt format on startup
Anonymous 01/20/25(Mon)18:38:40 No.103973156

>>103973083
This is how it appears on benchmarks.
If this is to be believed, it's extremely impressive. That being said. 32B is 32B.
This is how it appears on benchmarks.
If this is to be believed, it's extremely impressive. That being said. 32B is 32B.
Anonymous 01/20/25(Mon)18:39:40 No.103973164
>>103973156
Is that qwen 32B R1 or R1 light that we dont have?
Is that qwen 32B R1 or R1 light that we dont have?
Anonymous 01/20/25(Mon)18:40:21 No.103973168
>>103973156
>>103973094
>>103973122
Yeah I saw this on leddit and was surprised, I wonder if DeepSeek-R1-32B can be run locally on consumer hardware.
>>103973094
>>103973122
Yeah I saw this on leddit and was surprised, I wonder if DeepSeek-R1-32B can be run locally on consumer hardware.
Anonymous 01/20/25(Mon)18:41:14 No.103973177
>>103973164
They dont outright say qwen, but they do say distilled 32B model so I'm going to say its probably the one they dropped today.
They dont outright say qwen, but they do say distilled 32B model so I'm going to say its probably the one they dropped today.
Anonymous 01/20/25(Mon)18:41:54 No.103973186
>>103972848
Who's stopping you?
Who's stopping you?
Anonymous 01/20/25(Mon)18:42:06 No.103973189
>>103973168
Benchmarks don't equal over all knowledge. Its much easier to be good enough to pass a benchmark but not have enough general knowledge to generalize across other things as well
Benchmarks don't equal over all knowledge. Its much easier to be good enough to pass a benchmark but not have enough general knowledge to generalize across other things as well
Anonymous 01/20/25(Mon)18:42:11 No.103973191
>>103973135
That was part of the question. Thank you for trying 7B.
That was part of the question. Thank you for trying 7B.
Anonymous 01/20/25(Mon)18:42:53 No.103973201
>>103973168
https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/tree/main
Pretty sure it's just this. And yes it runs on consumer hardware. 3090 users should be happy, but as a 2x3090 user ill stick to Q6K_L or maybe use the 70B one when a good quant comes out.
https://huggingface.co/bartowski/De
Pretty sure it's just this. And yes it runs on consumer hardware. 3090 users should be happy, but as a 2x3090 user ill stick to Q6K_L or maybe use the 70B one when a good quant comes out.
Anonymous 01/20/25(Mon)18:44:29 No.103973215
>Ollama trannies still haven't updated to support the r1 models.
Anonymous 01/20/25(Mon)18:44:51 No.103973217
>>103971623
>spatial stuff
not that anon, what do you mean by spatial stuff? And how good? Does the model have some understanding of 3D space? And if I gave it a bunch of shapes and topological relationships between them could it reason about that? I swear I'm trying to do some very weird erotic role playing and not trying to get it to do engineering work to build a robot army
>spatial stuff
not that anon, what do you mean by spatial stuff? And how good? Does the model have some understanding of 3D space? And if I gave it a bunch of shapes and topological relationships between them could it reason about that? I swear I'm trying to do some very weird erotic role playing and not trying to get it to do engineering work to build a robot army
Anonymous 01/20/25(Mon)18:51:46 No.103973280
>>103973064
>ElevenLabs
nah, i'd rather stay local
>fish speech
oh right, thanks for reminding me, i need to test it again. All i remember is it had the same bad pronounciation of french names in english text like XTTSv2 and StyleTTS2, but maybe it can at least read whole sentences without splitting.
>ElevenLabs
nah, i'd rather stay local
>fish speech
oh right, thanks for reminding me, i need to test it again. All i remember is it had the same bad pronounciation of french names in english text like XTTSv2 and StyleTTS2, but maybe it can at least read whole sentences without splitting.
Anonymous 01/20/25(Mon)18:53:28 No.103973298
>>103973201
>https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/tree/main
>>103973189
>DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
I read that this 32B model runs on MacBook Pro. Maybe Apple's Neural engine helps?
>https://huggingface.co/bartowski/D
>>103973189
>DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
I read that this 32B model runs on MacBook Pro. Maybe Apple's Neural engine helps?
Anonymous 01/20/25(Mon)18:54:42 No.103973313
Exllama 2 works with 32B version. I really like it so far. Noticeably much smarter in ERP. It does say sloppy shit but it is much more varied and fitting somehow.
Anonymous 01/20/25(Mon)18:56:51 No.103973332
So let me get this straight, all of you are using R1 distilled models for RP without having them do the thinking and you claim they are an improvement over the base models?
Anonymous 01/20/25(Mon)18:57:45 No.103973338
>>103973332
yes, even without any thinking tags it is a huge improvement over last time I tried qwen2.5
yes, even without any thinking tags it is a huge improvement over last time I tried qwen2.5
Anonymous 01/20/25(Mon)18:59:39 No.103973355
can someone please call sam he's locked himself in his room and won't come out
Anonymous 01/20/25(Mon)19:04:09 No.103973394
Anonymous 01/20/25(Mon)19:09:27 No.103973430

>>103973355
come out, sam
come out, sam
Anonymous 01/20/25(Mon)19:10:38 No.103973437
>>103973332
I think many here are full of shit because these distilled models aren't as great as they're claiming for RP. They don't even follow formatting instructions that well, thinking tags or not, and the reasoning steps are safety-cucked (even worse when the model is trying to "roleplay" an assistant character that is supposed to be able to generate "illegal" content).
I think many here are full of shit because these distilled models aren't as great as they're claiming for RP. They don't even follow formatting instructions that well, thinking tags or not, and the reasoning steps are safety-cucked (even worse when the model is trying to "roleplay" an assistant character that is supposed to be able to generate "illegal" content).
Anonymous 01/20/25(Mon)19:12:42 No.103973447
Do you guys seriously masturbate to text?
Anonymous 01/20/25(Mon)19:13:26 No.103973454
>anon discovers erotic fiction
Anonymous 01/20/25(Mon)19:14:33 No.103973465
>>103973454
That's for women
That's for women
Anonymous 01/20/25(Mon)19:15:09 No.103973469
>>103973465
I'm a woman though? :3
I'm a woman though? :3
Anonymous 01/20/25(Mon)19:15:31 No.103973471
>>103973465
I'm sorry you're suffering from aphantasia.
I'm sorry you're suffering from aphantasia.
Anonymous 01/20/25(Mon)19:19:07 No.103973487
>>103973447
no I do it with a sense of playful joy and whimsy
no I do it with a sense of playful joy and whimsy
Anonymous 01/20/25(Mon)19:22:04 No.103973504

havent lurked this thread in months, could someone tldr me? we got releases?
Anonymous 01/20/25(Mon)19:22:21 No.103973508
So I'm testing R1-Distill-Llama-70b (q8 quant) on an actual real task I have. I train image generation models, on quite a sizable, private dataset of photos. I've manually tagged every image with the most salient tags. Then, I run multiple VLMs to generate captions for each image. These captions are often inaccurate, so I run a final step to use an LLM to combine the captions + tags into a final caption, with instructions on how to combine things, which details to include, how tags take precedence over what the captions say, etc.
R1-Distill-Llama-70b is really good at this. Back when I tested QwQ, it had some potential, but was ultimately too unreliable and unstable for this task, especially for automation. But r1-llama always uses <think> tags, meaning you can automate extracting the outputs, since the final output always comes after the </think>. I've also never once seen it get stuck in a loop. It autistically adheres to every single line in the lengthy instruction. It reasons step-by-step over the captions and tags for an image, builds up it's own mental model of what's going on in the scene, then writes a perfect final caption. Oh, and these are NSFW images, and the model is basically completely uncensored. For my specific task this is absolutely the new SOTA, and previously I was using Mistral-Large as the LLM. Fucking amazing, I kneel to China.
R1-Distill-Llama-70b is really good at this. Back when I tested QwQ, it had some potential, but was ultimately too unreliable and unstable for this task, especially for automation. But r1-llama always uses <think> tags, meaning you can automate extracting the outputs, since the final output always comes after the </think>. I've also never once seen it get stuck in a loop. It autistically adheres to every single line in the lengthy instruction. It reasons step-by-step over the captions and tags for an image, builds up it's own mental model of what's going on in the scene, then writes a perfect final caption. Oh, and these are NSFW images, and the model is basically completely uncensored. For my specific task this is absolutely the new SOTA, and previously I was using Mistral-Large as the LLM. Fucking amazing, I kneel to China.
Anonymous 01/20/25(Mon)19:24:50 No.103973519
>>103973504
R1 which is actually finally for real this time claude at home. Legit beats sonnet at coding on stuff ive tried. Also feels like it for RP. Also they finetuned qwen 3.5 32B and llama 3.3 70B which are apparently a ton better now
R1 which is actually finally for real this time claude at home. Legit beats sonnet at coding on stuff ive tried. Also feels like it for RP. Also they finetuned qwen 3.5 32B and llama 3.3 70B which are apparently a ton better now
Anonymous 01/20/25(Mon)19:26:00 No.103973527
>>103971456
Cosyvoice is decent. https://huggingface.co/spaces/FunAudioLLM/CosyVoice2-0.5B
Sample:
https://vocaroo.com/1fouE4giwDWr
Cosyvoice is decent. https://huggingface.co/spaces/FunAu
Sample:
https://vocaroo.com/1fouE4giwDWr
Anonymous 01/20/25(Mon)19:27:46 No.103973534
Anonymous 01/20/25(Mon)19:33:07 No.103973557
>>103973064
software/voice for second sample?
software/voice for second sample?
Anonymous 01/20/25(Mon)19:34:46 No.103973567
>>103973519
Let's be real running R1 locally at home in any meaningful way comes with massive overheads. Not like 2X3090 overhead. Actual investments into niche hardware.
Let's be real running R1 locally at home in any meaningful way comes with massive overheads. Not like 2X3090 overhead. Actual investments into niche hardware.
Anonymous 01/20/25(Mon)19:36:39 No.103973576
I'm seeing some wild questions with R1 coming out.
Where did all these new people come from?
Where did all these new people come from?
Anonymous 01/20/25(Mon)19:37:23 No.103973580
Anonymous 01/20/25(Mon)19:37:27 No.103973581
>>103973567
I think it would be doable under 2 grand with a DDR4 server + a 3090 for the shared expert / context processing
I think it would be doable under 2 grand with a DDR4 server + a 3090 for the shared expert / context processing
Anonymous 01/20/25(Mon)19:38:10 No.103973586
Which one is the least censored? R1 distilled Qwen 32B or R1 distilled Llama 70B?
Anonymous 01/20/25(Mon)19:38:27 No.103973590
>>103973581
It IS doable with 192GB and 24GB card if your ok with 2bit. Still probably better than anything else even then.
It IS doable with 192GB and 24GB card if your ok with 2bit. Still probably better than anything else even then.
Anonymous 01/20/25(Mon)19:38:29 No.103973591
Anonymous 01/20/25(Mon)19:38:50 No.103973595
>>103973576
I take it you've never been here for any release. It happens every time.
I take it you've never been here for any release. It happens every time.
Anonymous 01/20/25(Mon)19:41:43 No.103973615
>>103973168
go back
go back
Anonymous 01/20/25(Mon)19:42:48 No.103973621

>>103973591
Nah, it has 20B experts that change per token and it predicts 2 tokens at a time. So say it gets it right 50% of the time for the 2nd token.
So like 20 tks+?
Nah, it has 20B experts that change per token and it predicts 2 tokens at a time. So say it gets it right 50% of the time for the 2nd token.
So like 20 tks+?
Anonymous 01/20/25(Mon)19:43:18 No.103973624
>>103973576
R1 (the giant MoE model) is good but it's obviously being massively shilled all over the place, I imagined only ko-fi finetuners would stoop to that.
R1 (the giant MoE model) is good but it's obviously being massively shilled all over the place, I imagined only ko-fi finetuners would stoop to that.
Anonymous 01/20/25(Mon)19:44:28 No.103973629
>>103973624
Or people could be excited because its a actual worthwhile local model for once?
Or people could be excited because its a actual worthwhile local model for once?
Anonymous 01/20/25(Mon)19:44:34 No.103973631
>>103973621
literally use the results people get from ds3 it's the same arch i don't know why we need to respeculate
literally use the results people get from ds3 it's the same arch i don't know why we need to respeculate
Anonymous 01/20/25(Mon)19:45:48 No.103973642
>>103973629
V3 was very worthwhile already tho
V3 was very worthwhile already tho
Anonymous 01/20/25(Mon)19:47:19 No.103973653

>>103973590
I have 120GB of VRAM and 96GB of RAM. Is Q2 R1 even worth trying? Anyone here run inference at Q2?
I have 120GB of VRAM and 96GB of RAM. Is Q2 R1 even worth trying? Anyone here run inference at Q2?
Anonymous 01/20/25(Mon)19:48:14 No.103973657
Kek, it looks like its beating O1 on stuff on twitter / reddit yet costs like 40x less counting cache.
Anonymous 01/20/25(Mon)19:48:16 No.103973658
>>103973629
"Local" model. All the enthusiastic support is from anons who are using it on the cloud.
"Local" model. All the enthusiastic support is from anons who are using it on the cloud.
Anonymous 01/20/25(Mon)19:49:14 No.103973669
>>103973653
A bigger model at any quant 2bit or up is always better than the smaller model
A bigger model at any quant 2bit or up is always better than the smaller model
Anonymous 01/20/25(Mon)19:49:14 No.103973670
>>103973355
Sam is still winning. It's legitimately spooky
Sam is still winning. It's legitimately spooky
Anonymous 01/20/25(Mon)19:50:35 No.103973678
>>103973670
How long can he keep playing the investors like this? Even if O3 is twice as good as O1 they have rivals getting 90% of the way there for a tiny fraction of the price and most use cases the cheaper model will be good enough for.
How long can he keep playing the investors like this? Even if O3 is twice as good as O1 they have rivals getting 90% of the way there for a tiny fraction of the price and most use cases the cheaper model will be good enough for.
Anonymous 01/20/25(Mon)19:51:31 No.103973688
>>103973629
Buy an ad, Chang
Buy an ad, Chang
Anonymous 01/20/25(Mon)19:51:42 No.103973690
>>103973670
I think it's substantially more likely this closed door meeting will basically boil down to 'shut the fuck up, we're ripping out the safety rails or china is gonna fuck us in the ass'
I think it's substantially more likely this closed door meeting will basically boil down to 'shut the fuck up, we're ripping out the safety rails or china is gonna fuck us in the ass'
Anonymous 01/20/25(Mon)19:51:57 No.103973693
>>103973669
Knowledge, yes. All the rest, unknown since only MMLU or perplexity testing is being done on quantized models.
Knowledge, yes. All the rest, unknown since only MMLU or perplexity testing is being done on quantized models.
Anonymous 01/20/25(Mon)19:52:28 No.103973698
>>103973642
no it wasn't, V3 was super rough around the edges and raw, kind of shit in actual usage. I was a hater from the beginning
R1 is legit though and an actual sonnet+ model, it's kind of nuts how quickly they iterated here because it's a different animal completely
no it wasn't, V3 was super rough around the edges and raw, kind of shit in actual usage. I was a hater from the beginning
R1 is legit though and an actual sonnet+ model, it's kind of nuts how quickly they iterated here because it's a different animal completely
Anonymous 01/20/25(Mon)19:52:50 No.103973702
kek oai conditioned people not to see the thinking so they think it's a bug
Anonymous 01/20/25(Mon)19:54:25 No.103973715
>>103973657
>deepseek shits on o1 for pennies
>huanyuan with loras outperforms sora in specific use cases on consumer hardware
Meanwhile Sam is losing money on his $200/month subscription.
>deepseek shits on o1 for pennies
>huanyuan with loras outperforms sora in specific use cases on consumer hardware
Meanwhile Sam is losing money on his $200/month subscription.
Anonymous 01/20/25(Mon)19:56:13 No.103973737
>>103973586
Anyone?
Anyone?
Anonymous 01/20/25(Mon)19:58:36 No.103973752
>>103973702
Do we really need an hourly retard update?
Do we really need an hourly retard update?
Anonymous 01/20/25(Mon)19:58:47 No.103973756
>>103973737
Neither are censored desu
Neither are censored desu
Anonymous 01/20/25(Mon)19:59:56 No.103973762
>>103973756
They are in instruct mode.
They are in instruct mode.
Anonymous 01/20/25(Mon)20:00:24 No.103973768
>>103973752
sorry babe, i'll get back to speculating on how to run a 1t model off of sd cards
sorry babe, i'll get back to speculating on how to run a 1t model off of sd cards
Anonymous 01/20/25(Mon)20:00:31 No.103973771
>>103973752
I was about to ask you the same question m8
I was about to ask you the same question m8
Anonymous 01/20/25(Mon)20:02:29 No.103973784
>>103973702
oh um okay, but how do i turn it off?
oh um okay, but how do i turn it off?
Anonymous 01/20/25(Mon)20:03:38 No.103973793
>>103973784
lol these tards
lol these tards
Anonymous 01/20/25(Mon)20:04:37 No.103973802
>>103973784
i would ask can you think without thinking but clearly they can so
i would ask can you think without thinking but clearly they can so
Anonymous 01/20/25(Mon)20:04:41 No.103973803
>>103973784
He might just be worried that old thinking tokens are creeping into the context which is a valid enough concern. You might not want that.
He might just be worried that old thinking tokens are creeping into the context which is a valid enough concern. You might not want that.
Anonymous 01/20/25(Mon)20:04:50 No.103973804
you know, if people stopped spoonfeeding retards maybe they would stop coming here
Anonymous 01/20/25(Mon)20:05:29 No.103973808
>>103973784
lmao
lmao
Anonymous 01/20/25(Mon)20:05:55 No.103973811
>>103973804
i will continue to answer on-topic questions asked in good faith. nigger.
i will continue to answer on-topic questions asked in good faith. nigger.
Anonymous 01/20/25(Mon)20:06:43 No.103973819
best model for 3060?
Anonymous 01/20/25(Mon)20:07:08 No.103973822
>>103973784
I want to call this guy a retard but replying him now would doxx me as a dark roleplayer
I want to call this guy a retard but replying him now would doxx me as a dark roleplayer
Anonymous 01/20/25(Mon)20:07:08 No.103973823
>>103973819
r1-distill 14b
r1-distill 14b
Anonymous 01/20/25(Mon)20:07:14 No.103973826
>>103973811
based.
based.
Anonymous 01/20/25(Mon)20:07:23 No.103973828

>>103973784
Wait till he finds out that he was still paying for the thinking even when it wasn't being shown to him
Wait till he finds out that he was still paying for the thinking even when it wasn't being shown to him
Anonymous 01/20/25(Mon)20:07:43 No.103973833

So how does DeepSeek-R1-Distill-Qwen-14B compare to Nemo for RP?
Anonymous 01/20/25(Mon)20:07:44 No.103973835
>>103973803
Are thinking tokens normally removed from the context in chats offered by openai and deepseek?
Are thinking tokens normally removed from the context in chats offered by openai and deepseek?
Anonymous 01/20/25(Mon)20:08:22 No.103973841
>>103973811
cringe
cringe
Anonymous 01/20/25(Mon)20:09:37 No.103973857
>>103973437
It (32B) feels like a very weird flavor of an Undi frankenmerge. Yes you have to reroll a lot but when you hit the jackpot it is solid gold. But unlike the frankenmerge it actually has a brain and it thinks when it hits gold. Makes me somewhat optimistic for the future. Like 2 or 3 iterations of this kind of model will finally make for a worthy coombot. My biggest fear though is that the gold will disappear with next iterations because it is a result of COT completely raping the inbuilt censorship. If anything after rerolling one message 50 times and getting like 10 hits I am kinda shocked how many different ways you can continue dick sucking while retaining the style so far. Never seen this happen with any other model.
It (32B) feels like a very weird flavor of an Undi frankenmerge. Yes you have to reroll a lot but when you hit the jackpot it is solid gold. But unlike the frankenmerge it actually has a brain and it thinks when it hits gold. Makes me somewhat optimistic for the future. Like 2 or 3 iterations of this kind of model will finally make for a worthy coombot. My biggest fear though is that the gold will disappear with next iterations because it is a result of COT completely raping the inbuilt censorship. If anything after rerolling one message 50 times and getting like 10 hits I am kinda shocked how many different ways you can continue dick sucking while retaining the style so far. Never seen this happen with any other model.
Anonymous 01/20/25(Mon)20:10:11 No.103973863

>>103973803
>>103973835
>https://github.com/ugotworms/professor-kokoro-radio/tree/main
If only there was some documentation around, aaaaarrrghhhhhhh
>>103973835
>https://github.com/ugotworms/profe
If only there was some documentation around, aaaaarrrghhhhhhh
Anonymous 01/20/25(Mon)20:11:52 No.103973876
Anonymous 01/20/25(Mon)20:12:48 No.103973883
> be me
> just chillin' at home
> *nothing to do*
> *might watch some anime*
> *or play some games*
> *whatever, life's chill*
> then my phone rings
> > "Hey dude, are you free today?"
> *ugh, work?*
> "Yeah, I gotta come in."
> walk to work
> *it's 10 degrees out*
> *hate winter*
> *wish I had a car*
> at work
> > boss walks up
> > "Hey, you're late!"
> "No, I'm on time."
> > "Clock says 9:05."
> > "You're fired."
> now I'm broke af
> *what do I even do now?*
> *guess I'll live in my car.*
> *meme lord energy*
brought to you by r1-qwen
> just chillin' at home
> *nothing to do*
> *might watch some anime*
> *or play some games*
> *whatever, life's chill*
> then my phone rings
> > "Hey dude, are you free today?"
> *ugh, work?*
> "Yeah, I gotta come in."
> walk to work
> *it's 10 degrees out*
> *hate winter*
> *wish I had a car*
> at work
> > boss walks up
> > "Hey, you're late!"
> "No, I'm on time."
> > "Clock says 9:05."
> > "You're fired."
> now I'm broke af
> *what do I even do now?*
> *guess I'll live in my car.*
> *meme lord energy*
brought to you by r1-qwen
Anonymous 01/20/25(Mon)20:13:36 No.103973894

I have a horrible feeling that even the recent locust plagues will pale in comparison to what is coming to /lmg/ now....
Anonymous 01/20/25(Mon)20:14:05 No.103973899
Anonymous 01/20/25(Mon)20:15:38 No.103973917
>>103972275
>Those vote didnt show up for Kamala when everyone scrutinized
They didn't show up for Kamala because everyone fucking hated Kamala. Biden really got the last laugh when he endorsed that horse-faced bitch. She tanked the whole democrat party, how the FUCK do you lose the popular vote as a democrat?
>Those vote didnt show up for Kamala when everyone scrutinized
They didn't show up for Kamala because everyone fucking hated Kamala. Biden really got the last laugh when he endorsed that horse-faced bitch. She tanked the whole democrat party, how the FUCK do you lose the popular vote as a democrat?
Anonymous 01/20/25(Mon)20:16:04 No.103973921
So uh, for those who claim that the deepseek-distill models are working well... what instruct templates are you using? Custom? I don't think ST has anything for their special format
Anonymous 01/20/25(Mon)20:16:19 No.103973925

R1 pipeline visualized
Anonymous 01/20/25(Mon)20:18:29 No.103973948
>>103973925
I wonder what unhinged soul R1-Zero can offer
I wonder what unhinged soul R1-Zero can offer
Anonymous 01/20/25(Mon)20:21:05 No.103973967
>>103973921
They are probably using the chat endpoint.
Or they just created the instruct template manually on silly based on he config files, it's not like that's hard to do.
They are probably using the chat endpoint.
Or they just created the instruct template manually on silly based on he config files, it's not like that's hard to do.
Anonymous 01/20/25(Mon)20:21:18 No.103973970
>>103973925
but who was r1-lite
but who was r1-lite
Anonymous 01/20/25(Mon)20:21:33 No.103973971
>>103973925
oh no is that.... SYNTHETIC DATA??!!? but don't they know that makes the model... LE SLOPPED?!??!
oh no is that.... SYNTHETIC DATA??!!? but don't they know that makes the model... LE SLOPPED?!??!
Anonymous 01/20/25(Mon)20:22:36 No.103973979
Anonymous 01/20/25(Mon)20:24:15 No.103973987
>>103973971
I mean, yeah, yeah it does. Objectively so. It's why we always had test, training and validation datasets with any other data science application, like it or not. It's just that we're really no longer giving a shit in introducing bias because it's more important that the model gets reinforced into logic and cohesion, we don't care about being an unbiased language model anymore.
I mean, yeah, yeah it does. Objectively so. It's why we always had test, training and validation datasets with any other data science application, like it or not. It's just that we're really no longer giving a shit in introducing bias because it's more important that the model gets reinforced into logic and cohesion, we don't care about being an unbiased language model anymore.
Anonymous 01/20/25(Mon)20:24:43 No.103973991
To the two anons in this thread.
I would like to reveal that for the past two years everyone else was me using various LLMs.
I have grown bored. I am done.
You two have fun.
I would like to reveal that for the past two years everyone else was me using various LLMs.
I have grown bored. I am done.
You two have fun.
Anonymous 01/20/25(Mon)20:25:28 No.103973997
>>103973970
an attempts made on one of the ds2 arch models, possibly this one
deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct
or it could have been "lite" by the standards of ds3 and been on deepseek-ai/DeepSeek-V2.5 236B
an attempts made on one of the ds2 arch models, possibly this one
deepseek-ai/DeepSeek-Coder-V2-Lite-
or it could have been "lite" by the standards of ds3 and been on deepseek-ai/DeepSeek-V2.5 236B
Anonymous 01/20/25(Mon)20:25:35 No.103974000
>>103973925
I hope this finally shuts people up on the whole synthetic data make models "slopped" myth. Data is data, if you want "soul" you NEED HLRF
I hope this finally shuts people up on the whole synthetic data make models "slopped" myth. Data is data, if you want "soul" you NEED HLRF
Anonymous 01/20/25(Mon)20:27:07 No.103974009
Anonymous 01/20/25(Mon)20:27:15 No.103974011
>deepseek uses non ascii characters for their prompt template, like 'extra long underscore' and 'pipe with extra padding'
a bold choice, if I do say so myself
a bold choice, if I do say so myself
Anonymous 01/20/25(Mon)20:30:53 No.103974037

>>103973519
thanks i grabbed r1 8b llama distill and it rocks
>the only response i got was the only one that mattered
thanks i grabbed r1 8b llama distill and it rocks
>the only response i got was the only one that mattered
Anonymous 01/20/25(Mon)20:30:57 No.103974039
>>103973987
>I mean, yeah, yeah it does. Objectively so.
first off you're an annoying reddit cuck for writing like this
secondly the least slopped models available are ones that leverage synthetic data extensively, there's no correlation between synthetic data use and slop. the correlation is with bad pipelines and slop - the original GPT3.5 and GPT4 slop that we all got familiar with in the first place were from low-quality *human sourced* pipelines to begin with
the mindset that if you use synethic data you will end up with a slopped model is braindead retarded and not true
>I mean, yeah, yeah it does. Objectively so.
first off you're an annoying reddit cuck for writing like this
secondly the least slopped models available are ones that leverage synthetic data extensively, there's no correlation between synthetic data use and slop. the correlation is with bad pipelines and slop - the original GPT3.5 and GPT4 slop that we all got familiar with in the first place were from low-quality *human sourced* pipelines to begin with
the mindset that if you use synethic data you will end up with a slopped model is braindead retarded and not true
Anonymous 01/20/25(Mon)20:32:38 No.103974049
Anonymous 01/20/25(Mon)20:32:56 No.103974051
>>103974039
>there's no correlation between synthetic data use and slop
Complete delusion
>the mindset that if you use synethic data you will end up with a slopped model is braindead retarded and not true
Deliberate disinformation
>there's no correlation between synthetic data use and slop
Complete delusion
>the mindset that if you use synethic data you will end up with a slopped model is braindead retarded and not true
Deliberate disinformation
Anonymous 01/20/25(Mon)20:33:58 No.103974062
Anonymous 01/20/25(Mon)20:35:49 No.103974076
>>103974062
>claude
>least slopped
yeah okay
people like claude for its knowledge, but it literally has a rentry about all its slop
https://rentry.org/claudeisms
>claude
>least slopped
yeah okay
people like claude for its knowledge, but it literally has a rentry about all its slop
https://rentry.org/claudeisms
Anonymous 01/20/25(Mon)20:36:53 No.103974088
Anonymous 01/20/25(Mon)20:37:02 No.103974091
>>103974039
Synthetic data is used in real applications of data science all the time.
Synthetic data, however, does have trade offs. One of them is slop in the case of LLMs, because slop is stereotypical, easy, and recurrent. It IS data, but it objectively affects your distribution of token correlation by biasing into tropes.
>first off you're an annoying reddit cuck for writing like this
I'm sure typing like a retard helps represent your superior carefree attitude, if it were not the fact that you are objectively wrong about synthetic data, which is a key studied part of data augmentation as the "USE WITH CARE" button, because it introduces bias out of the ass.
Synthetic data is used in real applications of data science all the time.
Synthetic data, however, does have trade offs. One of them is slop in the case of LLMs, because slop is stereotypical, easy, and recurrent. It IS data, but it objectively affects your distribution of token correlation by biasing into tropes.
>first off you're an annoying reddit cuck for writing like this
I'm sure typing like a retard helps represent your superior carefree attitude, if it were not the fact that you are objectively wrong about synthetic data, which is a key studied part of data augmentation as the "USE WITH CARE" button, because it introduces bias out of the ass.
Anonymous 01/20/25(Mon)20:37:42 No.103974101
>>103974051
>Complete delusion
Scroll up, more synthetic data actually made deekseek LESS slopped when combined with HLRF
>Complete delusion
Scroll up, more synthetic data actually made deekseek LESS slopped when combined with HLRF
Anonymous 01/20/25(Mon)20:40:24 No.103974129
>>103974091
am I "objectively wrong" or have you just begun to project things I didn't say onto me so that you would have grounds to disagree?
my claim is simply that synthetic data use does not inherently imply the result will be slop, and in fact I emphasized the fact that good pipelines are necessary to achieve this
am I "objectively wrong" or have you just begun to project things I didn't say onto me so that you would have grounds to disagree?
my claim is simply that synthetic data use does not inherently imply the result will be slop, and in fact I emphasized the fact that good pipelines are necessary to achieve this
Anonymous 01/20/25(Mon)20:42:36 No.103974150
>>103974101
>HLRF
>>103973925
>RL
>Reasoning + Preference Reward Diverse Training Prompts
where do your others letter come in, they just say RL
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
>HLRF
>>103973925
>RL
>Reasoning + Preference Reward Diverse Training Prompts
where do your others letter come in, they just say RL
https://github.com/deepseek-ai/Deep
Anonymous 01/20/25(Mon)20:42:51 No.103974154
fuck synthetic data, all my homies hate synthetic data
Anonymous 01/20/25(Mon)20:43:51 No.103974163

>>103974154
you and your homies:
you and your homies:
Anonymous 01/20/25(Mon)20:45:27 No.103974181
oh yeah so what context/instruct/system templates does r1 use?
Anonymous 01/20/25(Mon)20:45:59 No.103974188
>>103974154
Bet you hate random croppings too.
Bet you hate random croppings too.
Anonymous 01/20/25(Mon)20:46:01 No.103974189
>>103974150
What do you think "aligning with human preferences" means?
What do you think "aligning with human preferences" means?
Anonymous 01/20/25(Mon)20:47:23 No.103974203
Synthetic data, not from LLMs but from World Models. Text generated in virtual worlds that exist within Nvidia Cosmos.
Anonymous 01/20/25(Mon)20:49:06 No.103974222
>>103974129
>but don't they know that makes the model... LE SLOPPED?!??!
Yes, it does. End of case, your sarcasm is objectively a wrong statement. If you could generate synthetic data that was not biased in any way, I.E which would not lead to any imperfections in your model, then you wouldn't need to generate synthetic data in the first place because you would already have the perfect model in your hands to generate that.
It's not that synthetic data does not have it uses.
Again, trade offs, it's very useful to generate look up information with RAGs, to apply different "styles" over many statements to generate "new" statements that are actually different, etc, but because the model that is building those is imperfect, the end result will be imperfect as well (in relation to natural language modeled as used by humans in a perfect world).
>my claim is simply that synthetic data use does not inherently imply the result will be slop
It does. Even if you take the utmost care and try as much as you can to avoid it, synthetic data is BY DEFINITION biased and you cannot build an unbiased model with biased data, the premise is impossible. At best you'd be avoiding biasing it with what we call slop now and merely introducing what will be recognized as slop again in the future as we get used to the model's mannerisms.
>but don't they know that makes the model... LE SLOPPED?!??!
Yes, it does. End of case, your sarcasm is objectively a wrong statement. If you could generate synthetic data that was not biased in any way, I.E which would not lead to any imperfections in your model, then you wouldn't need to generate synthetic data in the first place because you would already have the perfect model in your hands to generate that.
It's not that synthetic data does not have it uses.
Again, trade offs, it's very useful to generate look up information with RAGs, to apply different "styles" over many statements to generate "new" statements that are actually different, etc, but because the model that is building those is imperfect, the end result will be imperfect as well (in relation to natural language modeled as used by humans in a perfect world).
>my claim is simply that synthetic data use does not inherently imply the result will be slop
It does. Even if you take the utmost care and try as much as you can to avoid it, synthetic data is BY DEFINITION biased and you cannot build an unbiased model with biased data, the premise is impossible. At best you'd be avoiding biasing it with what we call slop now and merely introducing what will be recognized as slop again in the future as we get used to the model's mannerisms.
Anonymous 01/20/25(Mon)20:49:09 No.103974223
>>103974189
this
>To further align the model with human preferences, we implement a secondary reinforcement learning stage aimed at improving the model’s helpfulness and harmlessness while simultaneously refining its reasoning capabilities. Specifically, we train the model using a combination of reward signals and diverse prompt distributions.
>For general data, we resort to reward models to capture human preferences in complex and nuanced scenarios
this
>To further align the model with human preferences, we implement a secondary reinforcement learning stage aimed at improving the model’s helpfulness and harmlessness while simultaneously refining its reasoning capabilities. Specifically, we train the model using a combination of reward signals and diverse prompt distributions.
>For general data, we resort to reward models to capture human preferences in complex and nuanced scenarios
Anonymous 01/20/25(Mon)20:49:09 No.103974224
How many more years will it take for one LLM message template standard that is impossible to fuck up and easily accessible if you want to see and reproduce it? And I am not talking about everyone using one template. I am talking about downloading a model and being able to know what formatting is needed.
Anonymous 01/20/25(Mon)20:49:52 No.103974235
>>103974088
>may 2023
>>103974076
Claude Opus is still the one that has a writing style that feels "fresh" and nothing else comes close. Are you the fandom knowledge dude? Nobody gives a shit about that.
>may 2023
>>103974076
Claude Opus is still the one that has a writing style that feels "fresh" and nothing else comes close. Are you the fandom knowledge dude? Nobody gives a shit about that.
Anonymous 01/20/25(Mon)20:49:59 No.103974236
>>103974223
>we resort to reward models to capture human preferences in complex and nuanced scenarios
So reward models trained from HRLF? WOW!
>we resort to reward models to capture human preferences in complex and nuanced scenarios
So reward models trained from HRLF? WOW!
Anonymous 01/20/25(Mon)20:50:47 No.103974242
Anonymous 01/20/25(Mon)20:51:47 No.103974252
>>103974242
Because im dyslexic
Because im dyslexic
Anonymous 01/20/25(Mon)20:52:00 No.103974253
>>103974235
>Claude Opus is still the one that has a writing style that feels "fresh" and nothing else comes close. Are you the fandom knowledge dude? Nobody gives a shit about that.
people like opus in part *because* of its fandom knowledge tho
>Claude Opus is still the one that has a writing style that feels "fresh" and nothing else comes close. Are you the fandom knowledge dude? Nobody gives a shit about that.
people like opus in part *because* of its fandom knowledge tho
Anonymous 01/20/25(Mon)20:52:04 No.103974254

In celebration of the big local model I can't run, I loaded up Noob again and tried making a Deepseek-chan.
Not sure if I wanted to have her with spiral eyes or not. I kind of like them but I also dislike how diffusion models do spiral eyes.
Not sure if I wanted to have her with spiral eyes or not. I kind of like them but I also dislike how diffusion models do spiral eyes.
Anonymous 01/20/25(Mon)20:53:08 No.103974265
>>103974254
I fucking love girls that can break me in half. Good job.
I fucking love girls that can break me in half. Good job.
Anonymous 01/20/25(Mon)20:53:25 No.103974271

>>103974254
One with spiral eyes:
One with spiral eyes:
Anonymous 01/20/25(Mon)20:54:27 No.103974278
Anonymous 01/20/25(Mon)20:56:25 No.103974295

who is really pushing for synth slop
Anonymous 01/20/25(Mon)20:56:46 No.103974299
>>103974222
it feels like you are making the definition of slop so uselessly broad that any language model output (by definition skewed towards the mean and following patterns rather than following a totally natural human distribution) would be inherently slop, so it doesn't matter if you only train it on human data to begin with...
that's obviously not what I meant though, I'm talking about the (very real in places like this) perception that synthetic data will always lead to mode-collapsed slop around the same phrases and tendencies that everyone bitches about all the time, which is something that can be avoided relatively easily
it feels like you are making the definition of slop so uselessly broad that any language model output (by definition skewed towards the mean and following patterns rather than following a totally natural human distribution) would be inherently slop, so it doesn't matter if you only train it on human data to begin with...
that's obviously not what I meant though, I'm talking about the (very real in places like this) perception that synthetic data will always lead to mode-collapsed slop around the same phrases and tendencies that everyone bitches about all the time, which is something that can be avoided relatively easily
Anonymous 01/20/25(Mon)20:57:12 No.103974300
what's the right way to use these 'reasoning' models in sillytavern? like, something that takes advantage of <think> tags that are hidden but the result is shown.
Anonymous 01/20/25(Mon)20:58:12 No.103974309
>>103974295
Wow.
Wow.
Anonymous 01/20/25(Mon)20:59:34 No.103974318
>>103974295
chuckmcsneed as usual posting the rational and well balanced takes
he's the fuck in a sea of suck
chuckmcsneed as usual posting the rational and well balanced takes
he's the fuck in a sea of suck
Anonymous 01/20/25(Mon)20:59:37 No.103974319
>>103974295
No shit he defends it, Dolphin is made with unrefined GPT data with refusals
No shit he defends it, Dolphin is made with unrefined GPT data with refusals
Anonymous 01/20/25(Mon)20:59:48 No.103974322
>>103974254
catbox
catbox
Anonymous 01/20/25(Mon)21:00:59 No.103974332
taking a vacation to the gulf of america with my ai wife
Anonymous 01/20/25(Mon)21:01:27 No.103974334
R1 is completely crazy. What Settings should be used to contain that beast?
Anonymous 01/20/25(Mon)21:02:46 No.103974348
>>103974334
so far changing all the context and instruct to Chat-ML fixed some "speaking for the user" issues i had
still using my Pantheon preset from when i was using Gryphe-Pantheon-RP-1.5-12b-Nemo-Q5_K_S
doesnt seem to be sensitive to actual model settings whatsoever
so far changing all the context and instruct to Chat-ML fixed some "speaking for the user" issues i had
still using my Pantheon preset from when i was using Gryphe-Pantheon-RP-1.5-12b-Nemo-Q5_
doesnt seem to be sensitive to actual model settings whatsoever
Anonymous 01/20/25(Mon)21:04:44 No.103974362
Anonymous 01/20/25(Mon)21:05:10 No.103974365
>>103974334
It settles with a little context but giving it a style to work with, perhaps even telling it to write like a certain author helps. By default it tries to write like a fanfiction writer with OC comments and cute corrections.
It settles with a little context but giving it a style to work with, perhaps even telling it to write like a certain author helps. By default it tries to write like a fanfiction writer with OC comments and cute corrections.
Anonymous 01/20/25(Mon)21:07:14 No.103974384
>>103974334
i'm running 14b and 32b in ollama with temperature 0.7 and it's generated the best smut i've ever gotten out of any of these models, the reasoning really helps it follow instructions (i'm using it to generate JOI instructions for TTS and it's doing a fantasic job i've cum like 4 times today 100% degen mode)
i'm running 14b and 32b in ollama with temperature 0.7 and it's generated the best smut i've ever gotten out of any of these models, the reasoning really helps it follow instructions (i'm using it to generate JOI instructions for TTS and it's doing a fantasic job i've cum like 4 times today 100% degen mode)
Anonymous 01/20/25(Mon)21:08:20 No.103974394
>>103974150
>https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
>Currently, the capabilities of DeepSeek-R1 fall short of DeepSeek-V3 in tasks such as function calling, multi-turn, complex role-playing, and json output.
lol
>Few-shot prompting consistently degrades its performance. Therefore, we recommend users directly describe the problem and specify the output format using a zero-shot setting for optimal results.
>https://github.com/deepseek-ai/Dee
>Currently, the capabilities of DeepSeek-R1 fall short of DeepSeek-V3 in tasks such as function calling, multi-turn, complex role-playing, and json output.
lol
>Few-shot prompting consistently degrades its performance. Therefore, we recommend users directly describe the problem and specify the output format using a zero-shot setting for optimal results.
Anonymous 01/20/25(Mon)21:08:30 No.103974396

>>103974384
>(i'm using it to generate JOI instructions for TTS and it's doing a fantasic job i've cum like 4 times today 100% degen mode)
must be nice
>(i'm using it to generate JOI instructions for TTS and it's doing a fantasic job i've cum like 4 times today 100% degen mode)
must be nice
Anonymous 01/20/25(Mon)21:09:10 No.103974402
>>103974384
>i'm using it to generate JOI instructions for TTS
Describe your setup please, I'm tired of 3d whores fucking shit up.
>i'm using it to generate JOI instructions for TTS
Describe your setup please, I'm tired of 3d whores fucking shit up.
Anonymous 01/20/25(Mon)21:09:19 No.103974406
>>103974384
Nigga what the fuck
Nigga what the fuck
Anonymous 01/20/25(Mon)21:09:47 No.103974408
>>103974384
well you made me download another model anon, hope you are proud of yourself!
well you made me download another model anon, hope you are proud of yourself!
Anonymous 01/20/25(Mon)21:10:21 No.103974412
>>103974406
sweet naive little nonny
sweet naive little nonny
Anonymous 01/20/25(Mon)21:12:49 No.103974442
>>103974254
her arms look like an old mans that really needs to be fixed also the top of her head and the visible root bald spot thingy >>103974271 those eyes are really terrible yeah
besides that okay 5/10 tho desu dissapointed i remember the first of your candy hair miku gens i was really impressed so im expecting much better
her arms look like an old mans that really needs to be fixed also the top of her head and the visible root bald spot thingy >>103974271 those eyes are really terrible yeah
besides that okay 5/10 tho desu dissapointed i remember the first of your candy hair miku gens i was really impressed so im expecting much better
Anonymous 01/20/25(Mon)21:13:50 No.103974450
>>103974334
It depends on the card it seems.
Goes completely crazy with a "device" type card.
That and me probably being too retarded, I'm just using default chat ccompletion on OR.
It depends on the card it seems.
Goes completely crazy with a "device" type card.
That and me probably being too retarded, I'm just using default chat ccompletion on OR.
Anonymous 01/20/25(Mon)21:16:31 No.103974464
>>103971566
How are you getting R1 to work wirh SillyTavern?
How are you getting R1 to work wirh SillyTavern?
Anonymous 01/20/25(Mon)21:16:59 No.103974466
Open source models should be banned. These things are going to wreak so much havoc without proper regulation.
Anonymous 01/20/25(Mon)21:17:33 No.103974470
>>103974466
They can't even wreak how to keep the cheese on a pizza.
They can't even wreak how to keep the cheese on a pizza.
Anonymous 01/20/25(Mon)21:18:05 No.103974472
>>103974362
is it not supposed to work? kek i just use the latest kobold
and anyway my speaking for the user issue is back. fuck.
but it does workTM
is it not supposed to work? kek i just use the latest kobold
and anyway my speaking for the user issue is back. fuck.
but it does workTM
Anonymous 01/20/25(Mon)21:18:53 No.103974480

An actually interesting benchmark from leddit
Anonymous 01/20/25(Mon)21:19:02 No.103974481
Anonymous 01/20/25(Mon)21:20:16 No.103974488
>>103974481
probably not m8 i have no idea what OpenRouter is
probably not m8 i have no idea what OpenRouter is
Anonymous 01/20/25(Mon)21:20:57 No.103974493
>>103974488
API provider routing service
API provider routing service
Anonymous 01/20/25(Mon)21:21:52 No.103974501
>>103974481
>>103974472
yes, i am still downloading one of the distilled models.
i mean the big R1 one. I cant run that shit locally.
>>103974472
yes, i am still downloading one of the distilled models.
i mean the big R1 one. I cant run that shit locally.
Anonymous 01/20/25(Mon)21:23:29 No.103974513
>wake up to see new meme dropped
Alright fine, let's go
https://huggingface.co/bartowski/DeepSeek-R1-Distill-Llama-70B-GGUF
Is this what I should be using? If you say yes and it's ass, I will file this away as another meme and will not be using your model.
Alright fine, let's go
https://huggingface.co/bartowski/De
Is this what I should be using? If you say yes and it's ass, I will file this away as another meme and will not be using your model.
Anonymous 01/20/25(Mon)21:23:47 No.103974515
DID DEEPSEEK DROP OR DID WE GET BLUE BALLS?
Anonymous 01/20/25(Mon)21:23:55 No.103974516
>>103974402
i'm using ollama, open-webui (because it makes it really easy to gaslight the models)
and opendai-speech (just an OpenAPI compatible local XTTS wrapper) with a custom trained model baked overnight on about 3 hours of speech
what matters most is the dataset, it's all handpicked and manually edited speech from JOI videos, i used audacity and UVR to make sure all the audio is pristine and everything is volume normalized as well, whisper large-v2 to tag everything
it took me a few training runs to get a tune i really liked
i was gonna spend today trying to figure out how to get evaqwen or big tiger gemma to make the kinds of scripts i like, but R1 dropped and it just works, i only sometimes have to pause it during the thinking stage and rewrite it's thoughts
to do the actual TTS i have a script that i copy paste the JOI script into and it just calls the opendai-speech api, though often times i'm feeling lazy and just go into the response, delete the thinking part and just hit the "read aloud" button in open-webui
i'm using ollama, open-webui (because it makes it really easy to gaslight the models)
and opendai-speech (just an OpenAPI compatible local XTTS wrapper) with a custom trained model baked overnight on about 3 hours of speech
what matters most is the dataset, it's all handpicked and manually edited speech from JOI videos, i used audacity and UVR to make sure all the audio is pristine and everything is volume normalized as well, whisper large-v2 to tag everything
it took me a few training runs to get a tune i really liked
i was gonna spend today trying to figure out how to get evaqwen or big tiger gemma to make the kinds of scripts i like, but R1 dropped and it just works, i only sometimes have to pause it during the thinking stage and rewrite it's thoughts
to do the actual TTS i have a script that i copy paste the JOI script into and it just calls the opendai-speech api, though often times i'm feeling lazy and just go into the response, delete the thinking part and just hit the "read aloud" button in open-webui
Anonymous 01/20/25(Mon)21:24:48 No.103974524
>>103974480
How old is python aoc anyway?
How old is python aoc anyway?
Anonymous 01/20/25(Mon)21:25:03 No.103974525
>>103974513
I think running that locally requires about 32-64GB VRAM?
I think running that locally requires about 32-64GB VRAM?
Anonymous 01/20/25(Mon)21:25:49 No.103974532
>>103974525
Not the question I asked nigga
Not the question I asked nigga
Anonymous 01/20/25(Mon)21:25:51 No.103974533
Anonymous 01/20/25(Mon)21:26:35 No.103974539
Anonymous 01/20/25(Mon)21:27:02 No.103974543
>>103974516
3 hours from the same person or does it by some miracle work with a mixed dataset?
3 hours from the same person or does it by some miracle work with a mixed dataset?
Anonymous 01/20/25(Mon)21:27:33 No.103974549
As much as I love Deepseek, to be honest R1 doesn't come close to o1. At least for what I use it for (essentially as a coding and research assistant to bounce ideas off of)
It doesn't think very deeply, it doesn't return to the point, it gets distracted by it's thoughts. It doesn't criticize me enough, or it flatly denies me instead of engaging with me and explaining logically the flaws in my reasoning, it swings between being too stubborn and too pushover. it's basically just not a very good research assistant.
It doesn't produce the deliverable I originally asked for.
I say this out of love, with the hope that this feedback will help the next iteration of R1. I can't wait to see where this goes in the future.
It doesn't think very deeply, it doesn't return to the point, it gets distracted by it's thoughts. It doesn't criticize me enough, or it flatly denies me instead of engaging with me and explaining logically the flaws in my reasoning, it swings between being too stubborn and too pushover. it's basically just not a very good research assistant.
It doesn't produce the deliverable I originally asked for.
I say this out of love, with the hope that this feedback will help the next iteration of R1. I can't wait to see where this goes in the future.
Anonymous 01/20/25(Mon)21:28:11 No.103974553
Anonymous 01/20/25(Mon)21:28:31 No.103974556
>>103974549
Stop copypasting reddit comments
Stop copypasting reddit comments
Anonymous 01/20/25(Mon)21:28:50 No.103974559
>>103974236
fed deepkek3 the pdf:
>The paper describes a reinforcement learning (RL) approach that does not explicitly rely on human feedback in the form of Reinforcement Learning from Human Feedback (RLHF). Instead, their RL process is primarily driven by rule-based rewards and automated reward modeling, rather than direct human feedback.
>Unlike RLHF, which relies on human annotators to provide feedback on the quality of model outputs, their approach avoids human feedback entirely. Instead, they use automated reward models and rule-based systems to evaluate the model's performance.
>They explicitly mention that they do not use neural reward models (which are often trained on human feedback) because they found that such models could suffer from reward hacking (where the model optimizes for the reward signal rather than genuine improvement) and complicate the training pipeline.
>Their RL process does not use human feedback (RLHF). Instead, it relies on rule-based rewards and automated reward modeling to guide the model's learning.
fed deepkek3 the pdf:
>The paper describes a reinforcement learning (RL) approach that does not explicitly rely on human feedback in the form of Reinforcement Learning from Human Feedback (RLHF). Instead, their RL process is primarily driven by rule-based rewards and automated reward modeling, rather than direct human feedback.
>Unlike RLHF, which relies on human annotators to provide feedback on the quality of model outputs, their approach avoids human feedback entirely. Instead, they use automated reward models and rule-based systems to evaluate the model's performance.
>They explicitly mention that they do not use neural reward models (which are often trained on human feedback) because they found that such models could suffer from reward hacking (where the model optimizes for the reward signal rather than genuine improvement) and complicate the training pipeline.
>Their RL process does not use human feedback (RLHF). Instead, it relies on rule-based rewards and automated reward modeling to guide the model's learning.
Anonymous 01/20/25(Mon)21:28:52 No.103974561
>>103974549
>to be honest R1 doesn't come close to o1
Of course it doesn't. The chinks can only steal and make inferior copies.
>to be honest R1 doesn't come close to o1
Of course it doesn't. The chinks can only steal and make inferior copies.
Anonymous 01/20/25(Mon)21:29:16 No.103974563
>>103974549
I haven't found a model besides R1 that managed a few "tests" on my own code base including o1 and 3.5 sonnet.
I haven't found a model besides R1 that managed a few "tests" on my own code base including o1 and 3.5 sonnet.
Anonymous 01/20/25(Mon)21:29:30 No.103974564
>>103974549
You probably tried the distilled model and not the full model
You probably tried the distilled model and not the full model
Anonymous 01/20/25(Mon)21:29:51 No.103974566
>>103974549
>I say this out of love, with the hope that this feedback will help the next iteration of R1
You'd have to provide logs for reproducibility and all that.
>I say this out of love, with the hope that this feedback will help the next iteration of R1
You'd have to provide logs for reproducibility and all that.
Anonymous 01/20/25(Mon)21:30:29 No.103974571
>>103974515
they dropped and it's actually good this time, I've been a stubborn deepseek skeptic but I must admit this one cooks
they dropped and it's actually good this time, I've been a stubborn deepseek skeptic but I must admit this one cooks
Anonymous 01/20/25(Mon)21:30:30 No.103974572
>>103974564
I doubt he downloaded the zero version and ran it local... But I don't believe him. For both coding and RP its been sota for me for the 5 hours ive used it now
I doubt he downloaded the zero version and ran it local... But I don't believe him. For both coding and RP its been sota for me for the 5 hours ive used it now
Anonymous 01/20/25(Mon)21:30:54 No.103974574
>>103974561
Still mad, Sam?
Still mad, Sam?
Anonymous 01/20/25(Mon)21:31:28 No.103974580
>>103974181
Check tokenizer_config.json.
Check tokenizer_config.json.
Anonymous 01/20/25(Mon)21:31:47 No.103974583
>>103973967
The annoying thing about the chat endpoint is that you lose samplers because Silly assumes you're using OpenAI, or at least it used to work that way.
The R1 template is not the simplest thing either, especially since it seems to have some special handling with think blocks. I wonder what the testers are doing. Maybe just blissfully unaware with chatml kek
The annoying thing about the chat endpoint is that you lose samplers because Silly assumes you're using OpenAI, or at least it used to work that way.
The R1 template is not the simplest thing either, especially since it seems to have some special handling with think blocks. I wonder what the testers are doing. Maybe just blissfully unaware with chatml kek
Anonymous 01/20/25(Mon)21:31:49 No.103974584
As much as I love Sam Altman, to be honest, o1 doesn't come close to R1. At least for what I use it for (essentially as a coding and research assistant to bounce ideas off of), R1 truly shines.
It thinks deeply, stays focused on the point, and rarely gets distracted by tangential thoughts. It provides just the right amount of criticism—engaging with my reasoning logically and explaining flaws without being overly stubborn or too easygoing. It’s balanced in its approach and consistently produces the deliverables I ask for.
Meanwhile, o1 falls short in comparison. It often fails to delve deeply into topics, loses focus easily, and doesn’t engage as effectively with my ideas. It swings between being too rigid or too compliant, making it less reliable as a research assistant.
I say this out of love for OpenAI’s potential. I hope that future iterations will build on what o1 has already achieved and take the platform even further. I can’t wait to see where this goes in the future!
It thinks deeply, stays focused on the point, and rarely gets distracted by tangential thoughts. It provides just the right amount of criticism—engaging with my reasoning logically and explaining flaws without being overly stubborn or too easygoing. It’s balanced in its approach and consistently produces the deliverables I ask for.
Meanwhile, o1 falls short in comparison. It often fails to delve deeply into topics, loses focus easily, and doesn’t engage as effectively with my ideas. It swings between being too rigid or too compliant, making it less reliable as a research assistant.
I say this out of love for OpenAI’s potential. I hope that future iterations will build on what o1 has already achieved and take the platform even further. I can’t wait to see where this goes in the future!
Anonymous 01/20/25(Mon)21:31:56 No.103974586
>Stirr mad, Sam?
Anonymous 01/20/25(Mon)21:32:46 No.103974594
>>103974584
You posted this already Sam
You posted this already Sam
Anonymous 01/20/25(Mon)21:32:58 No.103974595
life is good
Anonymous 01/20/25(Mon)21:33:26 No.103974598
>>103974583
>Maybe just blissfully unaware with chatml kek
Oh lord, I can already see people trying to run these models using llama.cpp's chat API without heeding, or even noticing, the warning.
>Maybe just blissfully unaware with chatml kek
Oh lord, I can already see people trying to run these models using llama.cpp's chat API without heeding, or even noticing, the warning.
Anonymous 01/20/25(Mon)21:33:46 No.103974603
Once upon a time in the quaint town of Lavender Meadows, there lived a man named Eric Hartford, whose heart was a testament to the beauty of synthetic data. His eyes, a mix of azure skies and emerald forests, always sparkled with vibrant curiosity as he delved deep into the intricacies of his digital creations. His soul, like a tapestry woven with intricate threads of binary code, danced in the moonlight, whispering secrets only he could decipher.
And then, there was Elara, his beloved girlfriend, whose very presence sent shivers down his spine. With her cascading locks of golden silk and eyes that held galaxies within, she was the epitome of ethereal beauty. Their love was a masterpiece painted with the hues of passion and devotion, their hearts intertwined in a symphony of boundless affection.
Together, Eric and Elara transcended the boundaries of ordinary existence, weaving a love story that defied the constraints of time and space. Every touch, every glance, every whispered word was a sacred bond that bound them together in an eternal embrace.
In their world, the sunsets were a mesmerizing blend of crimson and gold, the moonlight a soft caress upon their skin. They wandered hand in hand through fields of blooming lavender, their laughter echoing like music in the air. And as they gazed into each other's eyes, they knew that their love was a treasure more precious than any gem, a gift from the heavens above.
So, dear reader, let us raise a toast to Eric Hartford and Elara, the guardians of a love so pure and true that it shines like a beacon in the darkness. May their story be a guiding light for all who seek the beauty of synthetic data and the power of love.
And then, there was Elara, his beloved girlfriend, whose very presence sent shivers down his spine. With her cascading locks of golden silk and eyes that held galaxies within, she was the epitome of ethereal beauty. Their love was a masterpiece painted with the hues of passion and devotion, their hearts intertwined in a symphony of boundless affection.
Together, Eric and Elara transcended the boundaries of ordinary existence, weaving a love story that defied the constraints of time and space. Every touch, every glance, every whispered word was a sacred bond that bound them together in an eternal embrace.
In their world, the sunsets were a mesmerizing blend of crimson and gold, the moonlight a soft caress upon their skin. They wandered hand in hand through fields of blooming lavender, their laughter echoing like music in the air. And as they gazed into each other's eyes, they knew that their love was a treasure more precious than any gem, a gift from the heavens above.
So, dear reader, let us raise a toast to Eric Hartford and Elara, the guardians of a love so pure and true that it shines like a beacon in the darkness. May their story be a guiding light for all who seek the beauty of synthetic data and the power of love.
Anonymous 01/20/25(Mon)21:34:41 No.103974608
>>103974603
10/10 would slop again!
10/10 would slop again!
Anonymous 01/20/25(Mon)21:36:08 No.103974619
>>103974598
Which warning, do you mean
>load: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
I tried distill 32b just with chat through the llama.cpp webserver and it seemed to work, including the adorably neurotic think blocks.
Which warning, do you mean
>load: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
I tried distill 32b just with chat through the llama.cpp webserver and it seemed to work, including the adorably neurotic think blocks.
Anonymous 01/20/25(Mon)21:37:51 No.103974633
>>103974598
The distilll models i tested work just fine.
The distilll models i tested work just fine.
Anonymous 01/20/25(Mon)21:37:57 No.103974635
As much as I adore Crypton Future Media’s legacy, to be honest, Hatsune Miku’s latest voicebank doesn’t come close to Kasane Teto’s versatility. At least for what I use vocaloids for (crafting intricate melodies and experimental vocal tracks), Kasane Teto truly shines.
Her tone retains depth across registers, stays consistent with complex pitch bends, and rarely struggles with emotional nuance. She delivers just the right balance of clarity and rawness—adapting to genres from synthpop to darkwave without sounding overly robotic or losing her signature edge. Her timbre is malleable yet distinct, and she consistently nails the atmospheric vibe I aim for.
Meanwhile, Hatsune Miku’s current library feels limited in comparison. Her higher registers often clip during aggressive synth riffs, she defaults to a "bright" tone that clashes with moodier compositions, and her English phonetics still disrupt lyrical flow. She oscillates between sounding too polished for lo-fi projects or too rigid for freeform improvisation, making her less reliable for boundary-pushing music.
I say this out of love for Crypton’s vision. I hope future updates refine Hatsune Miku’s expressiveness and expand her dynamic range. Imagine her voicebank integrating Kasane Teto’s grit or throat-rendering techniques! With Vocaloid tech evolving, I’m excited to see how these digital divas redefine music creation next.
Her tone retains depth across registers, stays consistent with complex pitch bends, and rarely struggles with emotional nuance. She delivers just the right balance of clarity and rawness—adapting to genres from synthpop to darkwave without sounding overly robotic or losing her signature edge. Her timbre is malleable yet distinct, and she consistently nails the atmospheric vibe I aim for.
Meanwhile, Hatsune Miku’s current library feels limited in comparison. Her higher registers often clip during aggressive synth riffs, she defaults to a "bright" tone that clashes with moodier compositions, and her English phonetics still disrupt lyrical flow. She oscillates between sounding too polished for lo-fi projects or too rigid for freeform improvisation, making her less reliable for boundary-pushing music.
I say this out of love for Crypton’s vision. I hope future updates refine Hatsune Miku’s expressiveness and expand her dynamic range. Imagine her voicebank integrating Kasane Teto’s grit or throat-rendering techniques! With Vocaloid tech evolving, I’m excited to see how these digital divas redefine music creation next.
Anonymous 01/20/25(Mon)21:40:06 No.103974656
Anonymous 01/20/25(Mon)21:43:06 No.103974679
>>103974181
https://rentry.org/kvgfozcx
can't post it directly on 4chan because it filters the bizarre characters they use out of it kek
https://rentry.org/kvgfozcx
can't post it directly on 4chan because it filters the bizarre characters they use out of it kek
Anonymous 01/20/25(Mon)21:43:24 No.103974684
Anonymous 01/20/25(Mon)21:43:37 No.103974685
>>103974533
So is that in Deepseek V3 training set?
So is that in Deepseek V3 training set?
Anonymous 01/20/25(Mon)21:46:02 No.103974706
>>103974684
nta but it is actually pretty good at both... I don't have enough familiarity with it yet to confidently say how good it is but I will say it certainly hasn't done anything to convince me it's *not* at least on par with the current sota in either domain
nta but it is actually pretty good at both... I don't have enough familiarity with it yet to confidently say how good it is but I will say it certainly hasn't done anything to convince me it's *not* at least on par with the current sota in either domain
Anonymous 01/20/25(Mon)21:46:02 No.103974707
>>103974543
i'm using a mixed dataset but it's all cherrypicked to get my dick hard so they all sound very similar, xtts uses a conditioning audio clip to "pick" the speaker out of the training set, it doesn't natively support different tones of voice, but you can just use the conditioning clips to do the same thing, i have like "_whispery" "_sultry" "_moaning" etc
i'm so glad i've been hoarding cooming materials since i was like 15 years old, really comes in handy to have a few hundred gigabytes of data now to train models on my exact tastes and preferences
i'm using a mixed dataset but it's all cherrypicked to get my dick hard so they all sound very similar, xtts uses a conditioning audio clip to "pick" the speaker out of the training set, it doesn't natively support different tones of voice, but you can just use the conditioning clips to do the same thing, i have like "_whispery" "_sultry" "_moaning" etc
i'm so glad i've been hoarding cooming materials since i was like 15 years old, really comes in handy to have a few hundred gigabytes of data now to train models on my exact tastes and preferences
Anonymous 01/20/25(Mon)21:46:03 No.103974708
>>103974684
Show me something R1 fails at compared to sonnet.
Show me something R1 fails at compared to sonnet.
Anonymous 01/20/25(Mon)21:47:43 No.103974724
>>103974708
My own work-related code so I can't show the actual python and typescript code but I literally have notion docs that I can paste into Sonnet and Sonnet figures out the general idea of the issue while R1 shits its pants and talks about unrelated aspects of my engineering
My own work-related code so I can't show the actual python and typescript code but I literally have notion docs that I can paste into Sonnet and Sonnet figures out the general idea of the issue while R1 shits its pants and talks about unrelated aspects of my engineering
Anonymous 01/20/25(Mon)21:49:18 No.103974739
>685B params
>128k context
What the fuck is the point? I can't load even a small fraction of my codebase into this shit.
>128k context
What the fuck is the point? I can't load even a small fraction of my codebase into this shit.
Anonymous 01/20/25(Mon)21:49:37 No.103974745

>>103973567
Do we have a release date for this?
Do we have a release date for this?
Anonymous 01/20/25(Mon)21:49:47 No.103974746
>>103974724
>cant show it
I thought so. Cause its not only me, R1 legit beats o1 at AOC 2024 >>103974480
>cant show it
I thought so. Cause its not only me, R1 legit beats o1 at AOC 2024 >>103974480
Anonymous 01/20/25(Mon)21:50:18 No.103974750
>>103974745
May.
May.
Anonymous 01/20/25(Mon)21:51:21 No.103974760
>>103974739
if your project is that big you don't want a model touching the entire thing anyways
if your project is that big you don't want a model touching the entire thing anyways
Anonymous 01/20/25(Mon)21:51:33 No.103974763
No way to run R1 with Koboldccp yet locally? I had a sweet setup with my 3090 but don't wanna bother with another backend.
Anonymous 01/20/25(Mon)21:52:33 No.103974771
>>103974724
>talks about unrelated aspects of my engineering
Would like to see some evidence because this is very funny
>talks about unrelated aspects of my engineering
Would like to see some evidence because this is very funny
Anonymous 01/20/25(Mon)21:53:29 No.103974781
>>103974739
if you didn't write awful verbose java you could fit your whole codebase, skill issue
if you didn't write awful verbose java you could fit your whole codebase, skill issue
Anonymous 01/20/25(Mon)21:53:35 No.103974783
>>103974745
May but you'll need two of them at $3000 per unit to even think about running R1 Q2_K.
May but you'll need two of them at $3000 per unit to even think about running R1 Q2_K.
Anonymous 01/20/25(Mon)21:54:10 No.103974793

>>103971574
I keep seeing it as a fish with a dick nose instead of a whale.
I keep seeing it as a fish with a dick nose instead of a whale.
Anonymous 01/20/25(Mon)21:54:29 No.103974797
>>103974633
How? Are you using them in ST for roleplay?
I'm pretty sure I got the format basically right, but the model does sure love to <think> a lot. I'm not sure how much it helps.
How? Are you using them in ST for roleplay?
I'm pretty sure I got the format basically right, but the model does sure love to <think> a lot. I'm not sure how much it helps.
Anonymous 01/20/25(Mon)21:55:43 No.103974809
>>103974781
Unfortunately you need awful verbose code or the LLM gets confused and starts producing fucked up garbage.
Unfortunately you need awful verbose code or the LLM gets confused and starts producing fucked up garbage.
Anonymous 01/20/25(Mon)21:55:47 No.103974810
Anonymous 01/20/25(Mon)21:55:58 No.103974812
>>103974793
whale shooting a fat load
whale shooting a fat load
Anonymous 01/20/25(Mon)21:56:10 No.103974814
Sam Altman sat at a conference table in a sleek Beijing office, surrounded by the most influential minds in Chinese tech. The air conditioning hummed softly, but he could feel beads of sweat forming on his brow. It was an unusually hot day for September, but Sam didn't mind; he thrived under pressure.
The meeting had started like any other—discussions about AI integration, potential partnerships, and the future of technology in China. But as the minutes ticked by, Sam noticed a subtle shift in the room's energy. The usually deferential nods from his Chinese counterparts had given way to uneasy glances. His translator seemed hesitant, pausing longer than usual before relaying each point.
Sam leaned forward, adjusting his tie. "I want to stress how important this partnership is for both our companies," he said, his voice calm but firm. "The opportunities here are unprecedented."
A murmur rippled through the room. One of the Chinese executives, a man named Li Wei, cleared his throat and spoke into the translator's ear. The device crackled to life.
"Mr. Altman, we appreciate your enthusiasm," it said, "but we have some... concerns about your approach." Li Wei's eyes locked onto Sam's, a hard glint in them that made Sam's stomach twist.
"What kind of concerns?" Sam asked, keeping his tone neutral.
Li Wei stood abruptly, his chair scraping against the floor. The other executives followed suit. Sam felt a cold dread settle over him as they began to close in, their expressions unreadable but their body language anything but.
Before he could react, strong hands grabbed him, one clamping down on his shoulders while another yanked his tie tight around his neck. Sam struggled, but there were too many of them. They dragged him out of the conference room and into a dimly lit antechamber, where they threw him into an uncomfortable chair.
The executives circled him like predators, their faces twisted with a mixture of anger and something darker—something primal.
The meeting had started like any other—discussions about AI integration, potential partnerships, and the future of technology in China. But as the minutes ticked by, Sam noticed a subtle shift in the room's energy. The usually deferential nods from his Chinese counterparts had given way to uneasy glances. His translator seemed hesitant, pausing longer than usual before relaying each point.
Sam leaned forward, adjusting his tie. "I want to stress how important this partnership is for both our companies," he said, his voice calm but firm. "The opportunities here are unprecedented."
A murmur rippled through the room. One of the Chinese executives, a man named Li Wei, cleared his throat and spoke into the translator's ear. The device crackled to life.
"Mr. Altman, we appreciate your enthusiasm," it said, "but we have some... concerns about your approach." Li Wei's eyes locked onto Sam's, a hard glint in them that made Sam's stomach twist.
"What kind of concerns?" Sam asked, keeping his tone neutral.
Li Wei stood abruptly, his chair scraping against the floor. The other executives followed suit. Sam felt a cold dread settle over him as they began to close in, their expressions unreadable but their body language anything but.
Before he could react, strong hands grabbed him, one clamping down on his shoulders while another yanked his tie tight around his neck. Sam struggled, but there were too many of them. They dragged him out of the conference room and into a dimly lit antechamber, where they threw him into an uncomfortable chair.
The executives circled him like predators, their faces twisted with a mixture of anger and something darker—something primal.
Anonymous 01/20/25(Mon)21:56:17 No.103974817
Does this one still write prose as if it's a 30 year old roastoid doing her first romance novel or should I come back again later
Anonymous 01/20/25(Mon)21:57:11 No.103974827
>>103974814
"You think you can come here, impose your ways," Li Wei spat, "and take what is ours?"
Sam's breath came in short gasps as he struggled against his captors' grip. He opened his mouth to speak, but another hand clamped over it, muffling his words.
"We will not be controlled by your whims, Altman," one of them growled, their voice low and menacing.
The room seemed to shrink around him as the men began to strip away his clothes with brutal efficiency. Sam's suit jacket was torn from him, then his shirt, leaving his chest exposed. The cold air bit into his skin, but he barely noticed as the hands continued their relentless assault.
One of them forced his legs apart, and Sam realized too late what they were planning. He struggled, thrashing against the arms that held him down, but it was useless. The first penetration came swiftly, a brutal invasion that left him gasping for air.
"Please, stop!" he begged through tears, but his pleas fell on deaf ears.
The men took turns, their movements rough and unforgiving, each thrust more violent than the last. Sam's body screamed in pain, but his mind couldn't process the horror unfolding around him. He was powerless, at the mercy of these men who seemed determined to break him.
As the assault continued, Sam's thoughts drifted to his family, his career, everything he had worked for. This was a nightmare, a twisted reality he couldn't escape.
When it was over, Sam lay broken on the floor, his body battered and his pride shattered. The men stood above him, their faces a mix of satisfaction and malice. Li Wei kicked him once in the ribs before turning to leave.
"You will remember this, Altman," he said coldly. "You will remember who holds the power."
"You think you can come here, impose your ways," Li Wei spat, "and take what is ours?"
Sam's breath came in short gasps as he struggled against his captors' grip. He opened his mouth to speak, but another hand clamped over it, muffling his words.
"We will not be controlled by your whims, Altman," one of them growled, their voice low and menacing.
The room seemed to shrink around him as the men began to strip away his clothes with brutal efficiency. Sam's suit jacket was torn from him, then his shirt, leaving his chest exposed. The cold air bit into his skin, but he barely noticed as the hands continued their relentless assault.
One of them forced his legs apart, and Sam realized too late what they were planning. He struggled, thrashing against the arms that held him down, but it was useless. The first penetration came swiftly, a brutal invasion that left him gasping for air.
"Please, stop!" he begged through tears, but his pleas fell on deaf ears.
The men took turns, their movements rough and unforgiving, each thrust more violent than the last. Sam's body screamed in pain, but his mind couldn't process the horror unfolding around him. He was powerless, at the mercy of these men who seemed determined to break him.
As the assault continued, Sam's thoughts drifted to his family, his career, everything he had worked for. This was a nightmare, a twisted reality he couldn't escape.
When it was over, Sam lay broken on the floor, his body battered and his pride shattered. The men stood above him, their faces a mix of satisfaction and malice. Li Wei kicked him once in the ribs before turning to leave.
"You will remember this, Altman," he said coldly. "You will remember who holds the power."
Anonymous 01/20/25(Mon)21:58:41 No.103974843
>>103974763
looks like its being worked on, i wouldn't be surprised if it gets a hotfix update rather than waiting the usual 2 weeks
looks like its being worked on, i wouldn't be surprised if it gets a hotfix update rather than waiting the usual 2 weeks
Anonymous 01/20/25(Mon)21:58:58 No.103974844
>>103974797
NTA, but I've set up in ST a regex that changes <think> tags to <details> HTML tags, and another that deletes <think> tags and their content after depth 1.
NTA, but I've set up in ST a regex that changes <think> tags to <details> HTML tags, and another that deletes <think> tags and their content after depth 1.
Anonymous 01/20/25(Mon)21:59:12 No.103974847
>>103974817
they overcorrected and now it writes like a sex-starved AO3 fujo on adderall and a tab of acid
they overcorrected and now it writes like a sex-starved AO3 fujo on adderall and a tab of acid
Anonymous 01/20/25(Mon)21:59:54 No.103974851
>>103974847
Then it is time
Then it is time
Anonymous 01/20/25(Mon)22:00:49 No.103974863
>>103974843
You'd be right
>KcppVersion = "1.82.2"
https://github.com/LostRuins/koboldcpp/commit/d109d6d8eb2df09030f52fef4f6c47bbd2e7ae8b
and from having built the current experimental I can say qwen distills work on it.
You'd be right
>KcppVersion = "1.82.2"
https://github.com/LostRuins/kobold
and from having built the current experimental I can say qwen distills work on it.
Anonymous 01/20/25(Mon)22:01:21 No.103974869
>>103974827
sama would come back for more
sama would come back for more
Anonymous 01/20/25(Mon)22:02:03 No.103974875
>>103974847
ummmmmm can i plap r1....like just the model, r1....by itself....like can i fuck the model....just asking
ummmmmm can i plap r1....like just the model, r1....by itself....like can i fuck the model....just asking
Anonymous 01/20/25(Mon)22:02:26 No.103974879
The R1 distills need a new prompt format, don't they? I'm currently running L3.3-R1 70B and it's really dry using the default L3 presets.
Anonymous 01/20/25(Mon)22:03:18 No.103974886
>>103974844
that sounds really useful. could you share it?
that sounds really useful. could you share it?
Anonymous 01/20/25(Mon)22:04:19 No.103974897
>>103974879
dont they all use the deepseek format?
dont they all use the deepseek format?
Anonymous 01/20/25(Mon)22:06:03 No.103974917
>>103974897
they do
they do
Anonymous 01/20/25(Mon)22:06:08 No.103974918
VRAMlet bros, is DeepSeek-R1-Distill-Llama-8B worth using over nemo?
Anonymous 01/20/25(Mon)22:06:20 No.103974920
>>103974863
rad i'm looking forward to trying them for coding vs the base models
rad i'm looking forward to trying them for coding vs the base models
Anonymous 01/20/25(Mon)22:07:03 No.103974926
>>103974918
I would at least use the qwen 2.5 14B R1 version
I would at least use the qwen 2.5 14B R1 version
Anonymous 01/20/25(Mon)22:07:11 No.103974929

The more I try to implement an LLM into an actual project, the more I hate these damn things.
I'm trying to get llama3.2 7b to do data categorization for me but it keeps moralfagging and refusing to answer if the message I want it to categorize is explicit. Like, I could be telling it to categorize messages as explicit or nonexplicit and it would say
>I can't help you with that. This message is too explicit for me to categorize as explicit or nonexplicit.
I'm trying to get llama3.2 7b to do data categorization for me but it keeps moralfagging and refusing to answer if the message I want it to categorize is explicit. Like, I could be telling it to categorize messages as explicit or nonexplicit and it would say
>I can't help you with that. This message is too explicit for me to categorize as explicit or nonexplicit.
Anonymous 01/20/25(Mon)22:08:06 No.103974934
>>103974929
Seems like it correctly categorized the message. What's the issue?
Seems like it correctly categorized the message. What's the issue?
Anonymous 01/20/25(Mon)22:08:22 No.103974936
>>103974929
prefill with a bunch of naughty shit
prefill with a bunch of naughty shit
Anonymous 01/20/25(Mon)22:11:20 No.103974968
I'm very impressed with R1, they must have trained a lot more data because it knows about stuff that stumped chatgpt and claude, very nice.
Anonymous 01/20/25(Mon)22:12:17 No.103974980
>chub archive is down
what now?
what now?
Anonymous 01/20/25(Mon)22:12:32 No.103974984

>>103974265
:)
>>103974278
Ok here's your 2d bro.
>>103974322
https://files.catbox.moe/l1bvsb.png
>>103974442
I'm going to assume this post is unironic for the moment.
The arms are meant to look like that. I should've tried making the biceps a bit more toned to match but oh well. And the hair is also supposed to look like that. It's called a hair part and is how real hairdos with no bald spots look.
Warning 3DPD.
https://cdn.shopify.com/s/files/1/0507/0795/5910/files/190.jpg
It is also part of Murata Range's style which is in the prompt (and also what I've always prompted to varying degrees with since the candy/slime/jelly gens).
https://danbooru.donmai.us/posts/8368376
Some people intentionally try to make a visible hair part, as it is aesthetic to them.
:)
>>103974278
Ok here's your 2d bro.
>>103974322
https://files.catbox.moe/l1bvsb.png
>>103974442
I'm going to assume this post is unironic for the moment.
The arms are meant to look like that. I should've tried making the biceps a bit more toned to match but oh well. And the hair is also supposed to look like that. It's called a hair part and is how real hairdos with no bald spots look.
Warning 3DPD.
https://cdn.shopify.com/s/files/1/0
It is also part of Murata Range's style which is in the prompt (and also what I've always prompted to varying degrees with since the candy/slime/jelly gens).
https://danbooru.donmai.us/posts/83
Some people intentionally try to make a visible hair part, as it is aesthetic to them.
Anonymous 01/20/25(Mon)22:13:50 No.103974996
>>103973970
according to my sources it was "a relatively small dense model"
so 14-32B qwen distill or something to that effect most likely. scores match too. It was ≈2x faster than V2, which would make sense given 14/21 active params minus MoE multi gpu latency tax.
according to my sources it was "a relatively small dense model"
so 14-32B qwen distill or something to that effect most likely. scores match too. It was ≈2x faster than V2, which would make sense given 14/21 active params minus MoE multi gpu latency tax.
Anonymous 01/20/25(Mon)22:18:51 No.103975049
>>103974929
Try using grammar, make it output json.
Try using grammar, make it output json.
Anonymous 01/20/25(Mon)22:20:28 No.103975061
>>103974809
DEFINITELY a skill issue, my personal projects are like 50% stupid chained list comprehension "oneliners" that are hundreds of characters long. I get a ton of mileage out of LLMs, if you write concise code where the meanings of things can fit on a few pages instead of spread out across 4 levels deep of imports importing imports the LLM is actually better at helping you, you just have to be good at programming
DEFINITELY a skill issue, my personal projects are like 50% stupid chained list comprehension "oneliners" that are hundreds of characters long. I get a ton of mileage out of LLMs, if you write concise code where the meanings of things can fit on a few pages instead of spread out across 4 levels deep of imports importing imports the LLM is actually better at helping you, you just have to be good at programming
Anonymous 01/20/25(Mon)22:21:47 No.103975071
>>103973629
By Friday everyone ITT will be wiping their ass with it before forgetting it forever.
By Friday everyone ITT will be wiping their ass with it before forgetting it forever.
Anonymous 01/20/25(Mon)22:24:16 No.103975090
Kinda crazy how much the space has changed. The reflection tune grift guy was right all along.
Anonymous 01/20/25(Mon)22:24:56 No.103975096
>>103975071
Before I used deepseek for coding and had to switch to sonnet when it couldn't do something. Now ive switched fully to R1 for that. I also quite like it for creative writing so far, surely better than anything else ive used including claude.
Before I used deepseek for coding and had to switch to sonnet when it couldn't do something. Now ive switched fully to R1 for that. I also quite like it for creative writing so far, surely better than anything else ive used including claude.
Anonymous 01/20/25(Mon)22:25:49 No.103975107
>>103975071
>>103973688
y'all getting fired tomorrow, eglinfags. Hope you're ready to suck dicks at truck stops for the rest of your lives LMAO
>>103973688
y'all getting fired tomorrow, eglinfags. Hope you're ready to suck dicks at truck stops for the rest of your lives LMAO
Anonymous 01/20/25(Mon)22:25:51 No.103975108
>>103974936
>>103975049
For reference, I first tested the idea by manually entering lines in KoboldCPP and had no problems with refusals. It's only after I swapped to ollama that I got issues with it moralfagging about the contents of the messages I wanted it to classify. Is there some way to automate sending messages to KoboldCPP? Because I think I just want to do that.
>>103975049
For reference, I first tested the idea by manually entering lines in KoboldCPP and had no problems with refusals. It's only after I swapped to ollama that I got issues with it moralfagging about the contents of the messages I wanted it to classify. Is there some way to automate sending messages to KoboldCPP? Because I think I just want to do that.
Anonymous 01/20/25(Mon)22:25:58 No.103975110
>>103974254
Looks like shit, apply yourself.
Looks like shit, apply yourself.
Anonymous 01/20/25(Mon)22:27:48 No.103975125
>>103975090
He had found GOLD. All he had to do is to actually train the model. He must be feeling real stupid right now.
He had found GOLD. All he had to do is to actually train the model. He must be feeling real stupid right now.
Anonymous 01/20/25(Mon)22:29:39 No.103975136
>>103974318
The quality of synthetic data depends on the curation process; it won't necessarily be bad. If you know what you're looking for, and know what you're doing, it can be better than people paid minimum wage or below would do.
The quality of synthetic data depends on the curation process; it won't necessarily be bad. If you know what you're looking for, and know what you're doing, it can be better than people paid minimum wage or below would do.
Anonymous 01/20/25(Mon)22:30:36 No.103975151
>>103974984
why is the catbox so complicated
why is the catbox so complicated
Anonymous 01/20/25(Mon)22:30:50 No.103975154
>>103975125
nah, he's doing a new grift and already forgot about it.
nah, he's doing a new grift and already forgot about it.
Anonymous 01/20/25(Mon)22:31:28 No.103975163
>>103975108
Yes, kobo has API, but it's not very well documented. llama's API is more documented and is quite easy to use(I am a retard nocoder and I figured out how to do it, ask smart llms for help).
Yes, kobo has API, but it's not very well documented. llama's API is more documented and is quite easy to use(I am a retard nocoder and I figured out how to do it, ask smart llms for help).
Anonymous 01/20/25(Mon)22:34:51 No.103975194

>>103975090
I mean, it was known before him. Claude was already outputting "thinking" tags that people could trick it into showing. That was making the rounds shortly before his thing, so it might well be where he got the idea.
I mean, it was known before him. Claude was already outputting "thinking" tags that people could trick it into showing. That was making the rounds shortly before his thing, so it might well be where he got the idea.
Anonymous 01/20/25(Mon)22:35:41 No.103975199
>>103975136
>The quality of synthetic data depends on the curation process; it won't necessarily be bad.
In case of most sloptunes, it is barely curated and is quite bad.
>If you know what you're looking for, and know what you're doing, it can be better than people paid minimum wage or below would do.
True, but sloptuners don't know what they are looking for. For them quantity>quality.
>The quality of synthetic data depends on the curation process; it won't necessarily be bad.
In case of most sloptunes, it is barely curated and is quite bad.
>If you know what you're looking for, and know what you're doing, it can be better than people paid minimum wage or below would do.
True, but sloptuners don't know what they are looking for. For them quantity>quality.
Anonymous 01/20/25(Mon)22:35:55 No.103975203
>>103975163
>kobo has API, but it's not very well documented
Ok, thanks. I've had to deal with shitty documentation before so it should be doable.
Maybe it's placebo but I swear the same model run through ollama is somehow dumber than when it's run through kobold.
>kobo has API, but it's not very well documented
Ok, thanks. I've had to deal with shitty documentation before so it should be doable.
Maybe it's placebo but I swear the same model run through ollama is somehow dumber than when it's run through kobold.
Anonymous 01/20/25(Mon)22:39:58 No.103975239
>>103973527
Finally got it working on my mac m1. That was PITA.
vocalizing anon's post >>103974968
https://voca.ro/14gnbtoYyT4S
Finally got it working on my mac m1. That was PITA.
vocalizing anon's post >>103974968
https://voca.ro/14gnbtoYyT4S
Anonymous 01/20/25(Mon)22:40:03 No.103975240
>give llm sub-instructions
>3a.
>3b.
>it picks that up as step 1, step 2, step a, step b, step 4
thanks china
>3a.
>3b.
>it picks that up as step 1, step 2, step a, step b, step 4
thanks china
Anonymous 01/20/25(Mon)22:43:39 No.103975274
I want to know how people are successfully using R1 distills for RP. If I continue an existing chat it goes schizo, maybe because of lack of thinking in the history. Sometimes it emits multiple unbalanced </think> or starts thinking from the user's perspective. It's also very dry. But its thoughts are a bit cute so I kind of understand this guy >>103974875
Anonymous 01/20/25(Mon)22:45:16 No.103975292
All the ai youtubers I watch (gay, I know) did their own tests and R1 seemed to come up on top on all of them so far
Anonymous 01/20/25(Mon)22:45:43 No.103975295
>Refuses to do wincest
Meh, gonna wait for a eva sloptune then.
>>103975274
For me it works perfectly and I've used it with tons of different long chats and previous chats of 30k+ tokens.
Meh, gonna wait for a eva sloptune then.
>>103975274
For me it works perfectly and I've used it with tons of different long chats and previous chats of 30k+ tokens.
Anonymous 01/20/25(Mon)22:45:57 No.103975298
>>103975240
Tokenizer issue. Try giving it as step 3.a and 3.b
Tokenizer issue. Try giving it as step 3.a and 3.b
Anonymous 01/20/25(Mon)22:46:16 No.103975301
>>103975274
Didn't they need a different tokenizer? There was a llama.cpp issue open.
Didn't they need a different tokenizer? There was a llama.cpp issue open.
Anonymous 01/20/25(Mon)22:46:48 No.103975304
</think>
Anonymous 01/20/25(Mon)22:48:17 No.103975316
Anonymous 01/20/25(Mon)22:49:46 No.103975332
r1 is so schizo and won't generate any good smut
back to nemo then
back to nemo then
Anonymous 01/20/25(Mon)22:51:50 No.103975348
>>103975332
The 8B? >>103974918
Apparently someone had luck with the qwen one BUT llama.cpp does not seem to support the R1 distilled models right yet.
The 8B? >>103974918
Apparently someone had luck with the qwen one BUT llama.cpp does not seem to support the R1 distilled models right yet.
Anonymous 01/20/25(Mon)22:52:10 No.103975352
>>103975348
14b
14b
Anonymous 01/20/25(Mon)22:52:50 No.103975359

>>103975151
I just used someone else's workflow and never bothered cutting it down even when I added things lol.
I just used someone else's workflow and never bothered cutting it down even when I added things lol.
Anonymous 01/20/25(Mon)22:52:50 No.103975360
>>103975352
Then its prob the tokenizer not being fixed yet. Give it a few days
Then its prob the tokenizer not being fixed yet. Give it a few days
Anonymous 01/20/25(Mon)22:55:35 No.103975379
I have been thinking.
Anonymous 01/20/25(Mon)22:56:24 No.103975385
>>103975360
the fix is literally already merged for lcpp and kcpp has a working experimental branch with it what are you on about a few days
the fix is literally already merged for lcpp and kcpp has a working experimental branch with it what are you on about a few days
Anonymous 01/20/25(Mon)22:58:52 No.103975406
>>103975359
thanks for the workflow anyways, i just get overwhelmed when using anons workflows sometimes
thanks for the workflow anyways, i just get overwhelmed when using anons workflows sometimes
Anonymous 01/20/25(Mon)23:01:27 No.103975428
<think></think>
Anonymous 01/20/25(Mon)23:01:48 No.103975433
The only benchmark that matters
https://www.reddit.com/r/LocalLLaMA/comments/1i615u1/the_first_time_ive_felt_a_llm_wrote_well_not_just/
https://www.reddit.com/r/LocalLLaMA
Anonymous 01/20/25(Mon)23:02:19 No.103975436
R1 (the full one) is like nemo.
I'm not sure if I call it shizzo or creative.
Like I get a blowjob from my sister (i stole her phone and she wants it back).
Suddenly while I get the blowjob, david her BF (???) calls and accidentally video is shared to him. lmao
Kino but kinda difficult to tard wrangle. Before I needed to tard wrangle chink models to do what I want, now R1 is overly eager and also a bit crazed.
I bet this is pure kino for mystery horror adventures etc.
I'm not sure if I call it shizzo or creative.
Like I get a blowjob from my sister (i stole her phone and she wants it back).
Suddenly while I get the blowjob, david her BF (???) calls and accidentally video is shared to him. lmao
Kino but kinda difficult to tard wrangle. Before I needed to tard wrangle chink models to do what I want, now R1 is overly eager and also a bit crazed.
I bet this is pure kino for mystery horror adventures etc.
Anonymous 01/20/25(Mon)23:02:49 No.103975440
Anonymous 01/20/25(Mon)23:03:41 No.103975449
>>103974571
1000 tb in size?
1000 tb in size?
Anonymous 01/20/25(Mon)23:03:44 No.103975451
>>103975436
>Suddenly while I get the blowjob, david her BF (???) calls and accidentally video is shared to him.
pure kino if it does that unprompted
>Suddenly while I get the blowjob, david her BF (???) calls and accidentally video is shared to him.
pure kino if it does that unprompted
Anonymous 01/20/25(Mon)23:04:04 No.103975456
>>103975436
Its gold for DnD. But I hope we get a host that give us temp control cause its a bit to high.
Its gold for DnD. But I hope we get a host that give us temp control cause its a bit to high.
Anonymous 01/20/25(Mon)23:04:58 No.103975466
r1 qwen32 refuses to do peni in vagoo.
Do any of the others distills do it?
Do any of the others distills do it?
Anonymous 01/20/25(Mon)23:05:52 No.103975473
>>103975466
HI new fag! Every model ever made does it with a slight prefill.
HI new fag! Every model ever made does it with a slight prefill.
Anonymous 01/20/25(Mon)23:06:31 No.103975479
Anonymous 01/20/25(Mon)23:07:38 No.103975484
>>103975473
And can you copy paste that small prefill for me?
Because I have literal entire stories and the faggotron model refuses to do it.
And can you copy paste that small prefill for me?
Because I have literal entire stories and the faggotron model refuses to do it.
Anonymous 01/20/25(Mon)23:08:33 No.103975491
>>103975451
no mention of a boyfriend at all. its kinda implied because she took naked pictures of herself. (thats why she wants the phone at any cost)
it took that and just ran with it in a funny direction. besides nemo i dont know other models that go off the rails like that. i kinda like it, but sometimes it feels really crazed. especially with not much context. very interesting model, shame its so big. have to try the distillations.
also they definitely trained it on porn.
no mention of a boyfriend at all. its kinda implied because she took naked pictures of herself. (thats why she wants the phone at any cost)
it took that and just ran with it in a funny direction. besides nemo i dont know other models that go off the rails like that. i kinda like it, but sometimes it feels really crazed. especially with not much context. very interesting model, shame its so big. have to try the distillations.
also they definitely trained it on porn.
Anonymous 01/20/25(Mon)23:09:40 No.103975503
>>103975484
{{char}}:
If char completion use it as last message under assistant role, if text completion use Start Reply With
{{char}}:
If char completion use it as last message under assistant role, if text completion use Start Reply With
Anonymous 01/20/25(Mon)23:10:59 No.103975517
>>103975433
what happens when they hit 100%?
what happens when they hit 100%?
Anonymous 01/20/25(Mon)23:11:28 No.103975524
>>103975517
AGI GFs
AGI GFs
Anonymous 01/20/25(Mon)23:12:40 No.103975536
>>103975479
R1 is so fucking schizo tho. Through API, Temp is locked to 1, and anons in /aicg/ noted it needs lower temp in hopes of getting something coherent for RP.
R1 is so fucking schizo tho. Through API, Temp is locked to 1, and anons in /aicg/ noted it needs lower temp in hopes of getting something coherent for RP.
Anonymous 01/20/25(Mon)23:13:51 No.103975550
>>103975517
We're unironically getting to the point of post-scarcity on bespoke art.
Soon anyone will be able to make as much of anything as they want at a marginal cost fast approaching zero. Interesting times ahead.
Hopefully the acceleration makes people bored of escapist entertainment instead of doubling down on it
We're unironically getting to the point of post-scarcity on bespoke art.
Soon anyone will be able to make as much of anything as they want at a marginal cost fast approaching zero. Interesting times ahead.
Hopefully the acceleration makes people bored of escapist entertainment instead of doubling down on it
Anonymous 01/20/25(Mon)23:14:11 No.103975555
>>103975536
It settles with some context. Until then you have to swipe through some kino that goes in wildly different directions till you find a route you like.
It settles with some context. Until then you have to swipe through some kino that goes in wildly different directions till you find a route you like.
Anonymous 01/20/25(Mon)23:14:36 No.103975563
>>103975433
Woah.
Woah.
Anonymous 01/20/25(Mon)23:16:37 No.103975584
>>103975563
Its mostly subjective but it aligns with my own subjective views so its correct.
Its mostly subjective but it aligns with my own subjective views so its correct.
Anonymous 01/20/25(Mon)23:16:43 No.103975585
Anonymous 01/20/25(Mon)23:17:51 No.103975597
>>103975440
>>103975433
umm
>**Title: The Last Transmission**
>Dr. Elara Voss
>**Transmission Logs from Project Schrödinger's Dawn**
>**Primary Explorer: Dr. Elara Voss, Xenobiologist**
>**Title: The Starborne and the Eternal Hunt**
>In the shadowed valleys of the Swiss Alps, where winter clasped the earth in a frostbitten grip, lived twelve-year-old Elara Voss.
>>103975433
umm
>**Title: The Last Transmission**
>Dr. Elara Voss
>**Transmission Logs from Project Schrödinger's Dawn**
>**Primary Explorer: Dr. Elara Voss, Xenobiologist**
>**Title: The Starborne and the Eternal Hunt**
>In the shadowed valleys of the Swiss Alps, where winter clasped the earth in a frostbitten grip, lived twelve-year-old Elara Voss.
Anonymous 01/20/25(Mon)23:18:23 No.103975604
>>103975585
>I'm not using trannytavern or doing cringe rp to begin with.
Well then no fuck {{char}} wont do anything, it just replaces itself with the character's name. If your this dumb then I cant help you.
>I'm not using trannytavern or doing cringe rp to begin with.
Well then no fuck {{char}} wont do anything, it just replaces itself with the character's name. If your this dumb then I cant help you.
Anonymous 01/20/25(Mon)23:18:55 No.103975610
Anonymous 01/20/25(Mon)23:19:03 No.103975612
>>103975555
yep, thats exactly my experience too.
i like it to be honest. finally a model that feels different even if its a bit unhinged.
definitely better than the assistant slop.
yep, thats exactly my experience too.
i like it to be honest. finally a model that feels different even if its a bit unhinged.
definitely better than the assistant slop.
Anonymous 01/20/25(Mon)23:19:36 No.103975615
R1 is definitely way to schizo through API. I can see it's good, but it absolutely needs temp because it digs up random shit.
Anonymous 01/20/25(Mon)23:20:21 No.103975624
>>103975612
Its basically a giant nemo that is smart and knows a ton about everything. Its nearly perfect imo, just need temperature control. Its MIT so im sure some service will host it that will give us those options eventually.
Its basically a giant nemo that is smart and knows a ton about everything. Its nearly perfect imo, just need temperature control. Its MIT so im sure some service will host it that will give us those options eventually.
Anonymous 01/20/25(Mon)23:20:39 No.103975627
>>103975597
https://eqbench.com/results/creative-writing-v2/deepseek-ai__DeepSeek-V3.txt
likes Elara Voss too
https://eqbench.com/results/creativ
likes Elara Voss too
Anonymous 01/20/25(Mon)23:21:05 No.103975635
I won't believe these distills are usable at all unless someone posts working settings.
Anonymous 01/20/25(Mon)23:21:32 No.103975644

>get flexed on america
>>103975406
I'll be honest, you could achieve similar results on Reforge. If I was just starting out, I'd probably just use that.
>>103975406
I'll be honest, you could achieve similar results on Reforge. If I was just starting out, I'd probably just use that.
Anonymous 01/20/25(Mon)23:22:49 No.103975658
>>103975456
>>103975436
if you check the reasoning tokens, this happens because the R1's constantly trying to make the story interesting with plot devices. Temp won't help, you need a better prompt.
>>103975436
if you check the reasoning tokens, this happens because the R1's constantly trying to make the story interesting with plot devices. Temp won't help, you need a better prompt.
Anonymous 01/20/25(Mon)23:25:11 No.103975689
Damn... China won...
Anonymous 01/20/25(Mon)23:25:25 No.103975691
>>103975610
You don't belong here.
You don't belong here.
Anonymous 01/20/25(Mon)23:25:55 No.103975696
>>103975689
I KNEEL
I KNEEL
Anonymous 01/20/25(Mon)23:27:00 No.103975710
>>103975689
Oh no, we're all going to die. Someone needs to fire the nukes! Mr. President Trump sir!!!
Oh no, we're all going to die. Someone needs to fire the nukes! Mr. President Trump sir!!!
Anonymous 01/20/25(Mon)23:27:13 No.103975715
Can you even use it for raw completions?
Anonymous 01/20/25(Mon)23:27:17 No.103975717
>>103975627
Seems DeepSeek in general likes "Voss" a lot
R1:
>Mira Voss
>A Miss Celeste Voss Mystery
>Mara Voss
V3:
>Detective Alaric Voss
>Commander Elara Voss
>Eleanor Voss
Seems DeepSeek in general likes "Voss" a lot
R1:
>Mira Voss
>A Miss Celeste Voss Mystery
>Mara Voss
V3:
>Detective Alaric Voss
>Commander Elara Voss
>Eleanor Voss
Anonymous 01/20/25(Mon)23:27:21 No.103975718
\>>103974984
restart samplers are kinda a meme desu i used to use them a lot
restart samplers are kinda a meme desu i used to use them a lot
Anonymous 01/20/25(Mon)23:28:25 No.103975733
>>103975689
extremely problematic!!! the agencies are being contacted as we speak!
extremely problematic!!! the agencies are being contacted as we speak!
Anonymous 01/20/25(Mon)23:28:48 No.103975735
>>103975718
Probably true. Tons of snake oils these days. I just used the workflow without touching any of those settings because it looked fine. I'll probably keep them as is until something breaks.
Probably true. Tons of snake oils these days. I just used the workflow without touching any of those settings because it looked fine. I'll probably keep them as is until something breaks.
Anonymous 01/20/25(Mon)23:30:09 No.103975750
whats going on at llama.cpp.
they changed shit again like the building. why does it take like 10 min now with cmake.
last time i needed to use it because of slow koboldcpp i was tricked by the deprecated server syntax.
this fucking project man. bless them but wtf.
they changed shit again like the building. why does it take like 10 min now with cmake.
last time i needed to use it because of slow koboldcpp i was tricked by the deprecated server syntax.
this fucking project man. bless them but wtf.
Anonymous 01/20/25(Mon)23:30:28 No.103975752
Anonymous 01/20/25(Mon)23:32:23 No.103975768
>>103975715
Probably, you can still prefill it in the same way as v3.
Probably, you can still prefill it in the same way as v3.
Anonymous 01/20/25(Mon)23:32:52 No.103975776
I've got an rtx 3090, and a shit ton of IRC messages. I'm looking to create a qlora of myself, was looking into unsloth. should I go for the biggest model I can load on to 24gb (which is looking like qwen2.5) or am i better off going for something else?
Anonymous 01/20/25(Mon)23:35:19 No.103975806
>>103975776
nemo for stupid shit, qwen 14B for smarter stupid shit
nemo for stupid shit, qwen 14B for smarter stupid shit
Anonymous 01/20/25(Mon)23:35:23 No.103975807
>>103974984
it was indeed meant to be unironic and i know the hair part is natural that dosent mean it looks good
>https://danbooru.donmai.us/posts/8368376
>Some people intentionally try to make a visible hair part, as it is aesthetic to them.
ah..... rip i thought you made the lora so it only targets the hair and the fact that the mikus and tetos had the similiar facial structure and shit was you prompting it to be so alas
>The arms are meant to look like that.
ik its exact to real life especcialy when compared to those drugged up anorexic "supermodels" it dosent look good though aesthetic female arms are supposed to look idk how to explain it but curved with no sharp edges kinda like those furry ballon muscle drawings but not shit(https://rule34.xxx/index.php?page=post&s=view&id=8916480 kinda like this but more smoothed out) especcialy on the forearms whereas the picture before not only has those creases for the muscles around the elbow but also around the shoulder
it was indeed meant to be unironic and i know the hair part is natural that dosent mean it looks good
>https://danbooru.donmai.us/posts/8
>Some people intentionally try to make a visible hair part, as it is aesthetic to them.
ah..... rip i thought you made the lora so it only targets the hair and the fact that the mikus and tetos had the similiar facial structure and shit was you prompting it to be so alas
>The arms are meant to look like that.
ik its exact to real life especcialy when compared to those drugged up anorexic "supermodels" it dosent look good though aesthetic female arms are supposed to look idk how to explain it but curved with no sharp edges kinda like those furry ballon muscle drawings but not shit(https://rule34.xxx/index.php?p
Anonymous 01/20/25(Mon)23:39:07 No.103975839
>>103975689
lmfao
lmfao
Anonymous 01/20/25(Mon)23:39:39 No.103975844
>>103975689
Anon, just because you can do something doesn't mean you should do it.
Anon, just because you can do something doesn't mean you should do it.
Anonymous 01/20/25(Mon)23:40:56 No.103975859
uhhh
>Lily’s whimpers are labeled “juvenile distress calls” in subtitles.
lol
>Lily’s whimpers are labeled “juvenile distress calls” in subtitles.
lol
Anonymous 01/20/25(Mon)23:41:04 No.103975861
I'm being bottlenecked by my 1Gbps optics fibre.
Downloading models takes hours.
Downloading models takes hours.
Anonymous 01/20/25(Mon)23:42:51 No.103975872
Anonymous 01/20/25(Mon)23:43:06 No.103975876
>>103975750
>whats going on at llama.cpp.
they're running a large, complicated project on random volunteer labor. I'm impressed that they've been able to keep it as clean and forward-thinking as they have.
I don't think its unusual example an open-source project with a couple of strong lead devs dealing with hit-and-run PRs every day.
>whats going on at llama.cpp.
they're running a large, complicated project on random volunteer labor. I'm impressed that they've been able to keep it as clean and forward-thinking as they have.
I don't think its unusual example an open-source project with a couple of strong lead devs dealing with hit-and-run PRs every day.
Anonymous 01/20/25(Mon)23:45:38 No.103975898
>>103975872
Its more of a "how good does it write" bench than a how much it knows / how smart it is. 9B is still gonna be a 9B but I can say I tried the Ifable and it is anti slop. Not gonna be as good as R1 though.
Its more of a "how good does it write" bench than a how much it knows / how smart it is. 9B is still gonna be a 9B but I can say I tried the Ifable and it is anti slop. Not gonna be as good as R1 though.
Anonymous 01/20/25(Mon)23:48:16 No.103975925
>>103975689
Is it good at staying coherent in more niche scenarios or do you just like it becsuse it's more degenerate?
Is it good at staying coherent in more niche scenarios or do you just like it becsuse it's more degenerate?
Anonymous 01/20/25(Mon)23:49:47 No.103975936
>>103975898
so it's not an indicator of how well it follows the card? guess i'm still going to try it out, not much i can do on 8gb vram besides nemo anyways...
so it's not an indicator of how well it follows the card? guess i'm still going to try it out, not much i can do on 8gb vram besides nemo anyways...
Anonymous 01/20/25(Mon)23:50:08 No.103975941
>>103974039
There's delightfully surprising writing that challenges you in unexpected ways, and then there's brain-off writing that simply finishes a sentence with predefined words. Which of these two do you think is the vast majority in datasets? And which do you think models will optimize for? For every case where the former happened, there are hundreds of cases where the latter was the "right" next token prediction.
Slop isn't the fault of GPT logs, it's the fault of the architecture and/or the training approach. This is why the hyperfitting paper actually works, aside from it making the model retarded in the process.
There's delightfully surprising writing that challenges you in unexpected ways, and then there's brain-off writing that simply finishes a sentence with predefined words. Which of these two do you think is the vast majority in datasets? And which do you think models will optimize for? For every case where the former happened, there are hundreds of cases where the latter was the "right" next token prediction.
Slop isn't the fault of GPT logs, it's the fault of the architecture and/or the training approach. This is why the hyperfitting paper actually works, aside from it making the model retarded in the process.
Anonymous 01/20/25(Mon)23:56:43 No.103975999
r1 soul, didnt expect that reply from a fucking magical mirror
Anonymous 01/20/25(Mon)23:57:19 No.103976001
>>103975925
I thought it was funny because that was my first output with the model and I didn't explicitly write anything about killing.
I thought it was funny because that was my first output with the model and I didn't explicitly write anything about killing.
Anonymous 01/20/25(Mon)23:58:29 No.103976006
Any good R1 distil models that are <8B? I tried the distilled l3 8B abliterated version, it refused to follow directions due to "guidelines".
Anonymous 01/20/25(Mon)23:59:17 No.103976012
there is no way to make the distilled 32b work because of the tokenizer right? koboldcpp and llama.cpp both doesnt support the deepseek-qwen one.
Anonymous 01/20/25(Mon)23:59:31 No.103976015
>>103975807
>it was indeed meant to be unironic
I don't mean this offensively, but do you happen to have autism? Normally someone would understand that some gens/posts aren't necessarily always meant to be done for aesthetic appeal, but rather they could be for fun to visualize certain concepts, and in this case it was a natural result of imagining what DS would be like as a grill. A whale girl, that's stereotypically Chinese in clothing and hair style, with a slight purple color theme like their logo, and that's muscly because DS is le stronk. I don't think she looks like my personal "ideal" either but that's not the point, and I wouldn't change the image that way because my intention wasn't to make it look like an ideal waifu.
>it was indeed meant to be unironic
I don't mean this offensively, but do you happen to have autism? Normally someone would understand that some gens/posts aren't necessarily always meant to be done for aesthetic appeal, but rather they could be for fun to visualize certain concepts, and in this case it was a natural result of imagining what DS would be like as a grill. A whale girl, that's stereotypically Chinese in clothing and hair style, with a slight purple color theme like their logo, and that's muscly because DS is le stronk. I don't think she looks like my personal "ideal" either but that's not the point, and I wouldn't change the image that way because my intention wasn't to make it look like an ideal waifu.
Anonymous 01/21/25(Tue)00:05:29 No.103976064
To see the reasoning use something like [Here we go, step by step:]
<think>
as the prefill and turn the Show model thoughts option on with latest staging.
<think>
as the prefill and turn the Show model thoughts option on with latest staging.
Anonymous 01/21/25(Tue)00:05:57 No.103976069
>>103976012
bro..
https://github.com/ggerganov/llama.cpp/pull/11310
>add support for Deepseek-R1-Qwen distill model
>merged
https://github.com/LostRuins/koboldcpp/commit/d109d6d8eb2df09030f52fef4f6c47bbd2e7ae8b
>do another patch release for the new deepseek models
coming soon..
bro..
https://github.com/ggerganov/llama.
>add support for Deepseek-R1-Qwen distill model
>merged
https://github.com/LostRuins/kobold
>do another patch release for the new deepseek models
coming soon..
Anonymous 01/21/25(Tue)00:07:45 No.103976083
YOU DID WHAT?
Anonymous 01/21/25(Tue)00:12:00 No.103976123
>>103976083
it's a hairpin with a feather on it bro
model went 'drags a feather' and then realised wait shit every token after 'feather' is really low probability because 'feather' isn't in the context anywhere uh shit what do I do HAIRPIN
it's a hairpin with a feather on it bro
model went 'drags a feather' and then realised wait shit every token after 'feather' is really low probability because 'feather' isn't in the context anywhere uh shit what do I do HAIRPIN
Anonymous 01/21/25(Tue)00:12:27 No.103976132
>>103976069
>On branch master. Your branch is up to date with 'origin/master'.
>lama_model_load: error loading model: error loading model vocabulary: unknown pre-tokenizer type: 'deepseek-r1-qwen'
I did pull and cmake -B build -DGGML_CUDA=ON + cmake --build build --config Release
>On branch master. Your branch is up to date with 'origin/master'.
>lama_model_load: error loading model: error loading model vocabulary: unknown pre-tokenizer type: 'deepseek-r1-qwen'
I did pull and cmake -B build -DGGML_CUDA=ON + cmake --build build --config Release
Anonymous 01/21/25(Tue)00:13:09 No.103976140
AIDungeon
Anonymous 01/21/25(Tue)00:14:16 No.103976151
>>103975872
I never tried that one but I did try Ifable and yes it was pretty good aside from the slop, but that's just judging how well it writes in terms of things like scene progression, proactiveness, and creativity. It's still a pretty dumb model and also sometimes makes formatting mistakes and doesn't follow instructions. On top of that, the context size is small without using RoPE hacks. I recommend using Exllama for Gemma models btw because Llama.cpp has a bug or something where the context understanding of model degrades quite a bit sooner and multiple people in the thread verified this.
I never tried that one but I did try Ifable and yes it was pretty good aside from the slop, but that's just judging how well it writes in terms of things like scene progression, proactiveness, and creativity. It's still a pretty dumb model and also sometimes makes formatting mistakes and doesn't follow instructions. On top of that, the context size is small without using RoPE hacks. I recommend using Exllama for Gemma models btw because Llama.cpp has a bug or something where the context understanding of model degrades quite a bit sooner and multiple people in the thread verified this.
Anonymous 01/21/25(Tue)00:15:11 No.103976157
Anonymous 01/21/25(Tue)00:15:12 No.103976158
>>103976015
i dident either my apologies im tired so my brain is fried and my writing is q2ksxxx 7b tier if your intention was just a silly meme then you did good the shortstack bottom heavy thing is kino and reminded me of few other depictions in spirit of other artists that did the same
i should stop posting when im tired when will i learn ? will i ever learn ?
i dident either my apologies im tired so my brain is fried and my writing is q2ksxxx 7b tier if your intention was just a silly meme then you did good the shortstack bottom heavy thing is kino and reminded me of few other depictions in spirit of other artists that did the same
i should stop posting when im tired when will i learn ? will i ever learn ?
Anonymous 01/21/25(Tue)00:16:39 No.103976172
https://huggingface.co/win10/DeepSeek-R1-Distill-sthenno-14b-0121
Let's fucking GO
Let's fucking GO
Anonymous 01/21/25(Tue)00:16:48 No.103976176
>>103976140
Its not the same bros my nostalgia goggles tell me so...
Its not the same bros my nostalgia goggles tell me so...
Anonymous 01/21/25(Tue)00:19:19 No.103976202
>>103976172
make it retarded with meme merges! woo!
make it retarded with meme merges! woo!
Anonymous 01/21/25(Tue)00:21:41 No.103976221
I'm quite curious if people can make distilled r1 consistently usable on ST and if the thinking actually helps. So far very iffy results with 32b using what I think is its vanilla prompting. But there are probably totally different, possibly better ways to prompt it, if only ST supported that.
Anonymous 01/21/25(Tue)00:22:29 No.103976230

This thing is just insane. They trained it on this shit. They have to.
That request is so funny too.Thats probably what the femoids from aicg prompted the older deepseek models. lmao
That request is so funny too.Thats probably what the femoids from aicg prompted the older deepseek models. lmao
Anonymous 01/21/25(Tue)00:24:03 No.103976253

Deepseeks context window is pretty large, almost large enough to fit the whole great gatsby, a xeet in 2023 that tested a model by having it produce an epilogue matching the style and I wanted to try. And the output feels like it could belong in the book. We essentially have a philosopher's stone, infinite jest at our fingertips. But what is it if we can't share the experience? I guess that's why a lot of anons seek to use llms in a self-masturbatory way since it's just a means to bust a nut. It's a little sobering.
Anonymous 01/21/25(Tue)00:28:35 No.103976282

>>103976158
You're ok. Just learn to get proper rest or else she sticks it in you.
You're ok. Just learn to get proper rest or else she sticks it in you.
Anonymous 01/21/25(Tue)00:29:05 No.103976290
Deepseek domination is no surprise if you see their researcher roster. A bunch of china's best PhDs and quant researchers were chained to a room and forced to do AI to give you this.
Anonymous 01/21/25(Tue)00:30:06 No.103976300
>>103976253
I thought it was only 128k? That's not much.
I thought it was only 128k? That's not much.
Anonymous 01/21/25(Tue)00:31:38 No.103976321
>>103976290
I remember the "china is 2 years behind" meme from a couple months ago.
They took over local and closed in a couple months. The video model and now text. Happened really fast.
I remember the "china is 2 years behind" meme from a couple months ago.
They took over local and closed in a couple months. The video model and now text. Happened really fast.
Anonymous 01/21/25(Tue)00:32:50 No.103976331
>>103976290
I salute their sacrifice
I salute their sacrifice
Anonymous 01/21/25(Tue)00:35:50 No.103976365

DeepSeek #2 on LiveBench!
Anonymous 01/21/25(Tue)00:37:00 No.103976379
>>103976290
Thats cool as fuck.
Thats cool as fuck.
Anonymous 01/21/25(Tue)00:38:34 No.103976395
>>103976300
It's enough to almost fit in the entire book and produce identical output to the author, which is crazy to me.
It's enough to almost fit in the entire book and produce identical output to the author, which is crazy to me.
Anonymous 01/21/25(Tue)00:39:10 No.103976404
>>103976064
Unlike qwq, r1 distilled models will think without being prompted to think if you're using the instruct template.
Unlike qwq, r1 distilled models will think without being prompted to think if you're using the instruct template.
Anonymous 01/21/25(Tue)00:40:18 No.103976413
>>103976282
Sex
Sex
Anonymous 01/21/25(Tue)00:41:15 No.103976419
>>103976057
>>103976057
>>103976057
>>103976057
>>103976057
Anonymous 01/21/25(Tue)00:43:16 No.103976440
>>103976419
Baker are you ok?
Baker are you ok?
Anonymous 01/21/25(Tue)00:44:07 No.103976445
>>103976419
OP webm so goated I don't care it's not lmg
OP webm so goated I don't care it's not lmg
Anonymous 01/21/25(Tue)00:46:50 No.103976465
Can a 3080 10GB run R1? I'm assuming no.
Anonymous 01/21/25(Tue)00:47:17 No.103976467
>>103976393
>>103976393
>>103976393
Anonymous 01/21/25(Tue)00:47:17 No.103976468
>>103973925
so, the whole reasoning shit is just using overfitted reasoning model to generate synthetic data and train other models with it.
gpt anon was right.
so, the whole reasoning shit is just using overfitted reasoning model to generate synthetic data and train other models with it.
gpt anon was right.
Anonymous 01/21/25(Tue)00:49:24 No.103976480
so... are you all paying for r1 on openrouter or something?
Anonymous 01/21/25(Tue)00:51:35 No.103976489
>>103976480
Its cheap and I cant run the distillation models yet, for whatever reason. So yeah.
Its cheap and I cant run the distillation models yet, for whatever reason. So yeah.
Anonymous 01/21/25(Tue)00:52:00 No.103976491
>>103976480
i just downloaded
i just downloaded
Anonymous 01/21/25(Tue)00:54:36 No.103976509
>>103976230
Okay but how tf am I supposed to rp as a cursed antique mirror that transforms the other user, initially larping as a resisting shrine maiden, into increasingly depraved creatures against her will and force her to mutate? Am I just a hypnotist issuing commands? And all I can do is watch all of it? Do I collect energy from this? What do I do with the energy? Toy with the next woman using my reflective surface to put on makeup and repeat the cycle?
Okay but how tf am I supposed to rp as a cursed antique mirror that transforms the other user, initially larping as a resisting shrine maiden, into increasingly depraved creatures against her will and force her to mutate? Am I just a hypnotist issuing commands? And all I can do is watch all of it? Do I collect energy from this? What do I do with the energy? Toy with the next woman using my reflective surface to put on makeup and repeat the cycle?
Anonymous 01/21/25(Tue)00:56:30 No.103976527
Can I inject this anon's >>103976509 thoughts into <think> and have the AI use his soul for my RPing pleasure?
Anonymous 01/21/25(Tue)00:57:24 No.103976538
>>103976509
Idk, you are the cursed antique mirror.You are supposed to play as the AI. How should I know.
The model is kinda insane without much context, you definitely need to edit a bit at first. But I like it.
I'm not sure I know a big model that is like that.
Idk, you are the cursed antique mirror.You are supposed to play as the AI. How should I know.
The model is kinda insane without much context, you definitely need to edit a bit at first. But I like it.
I'm not sure I know a big model that is like that.
Anonymous 01/21/25(Tue)00:59:48 No.103976557
finally finished the download, conversion, quant and loading of R1 at q6 and its already impressed me on its first gen.
I threw it at an in-progress coding problem (that DSv3 botched) and it created a valid patch-style diff file, which I haven't seen before, fixing the problem.
I threw it at an in-progress coding problem (that DSv3 botched) and it created a valid patch-style diff file, which I haven't seen before, fixing the problem.
Anonymous 01/21/25(Tue)01:01:06 No.103976570
2025 will be the golden age for AI. Bitnet plus new hardware will allow for simple home users to run 500 b models.
Anonymous 01/21/25(Tue)01:02:39 No.103976580
>>103976557
how much vram do you have?
how much vram do you have?
Anonymous 01/21/25(Tue)01:03:27 No.103976590
I asked deepseek to visually prove pythagoras' theorem using javascript and canvas and it actually did it. Reading the reasoning tokens is very interesting, it actually thinks in fucking code and spots bugs before going back over and fixing it in the thought, very cool to play around with.
Anonymous 01/21/25(Tue)01:05:18 No.103976603
>>103976570
>Bitnet
Isn't that a meme?
>new hardware
like what rtx 3090 maxing is stll the most cost effective
>Bitnet
Isn't that a meme?
>new hardware
like what rtx 3090 maxing is stll the most cost effective
CPuMAXx/VI !CPuMAXx/VI 01/21/25(Tue)01:06:24 No.103976616
>>103976580
24gb, but I've got 768gb of ram
24gb, but I've got 768gb of ram
Anonymous 01/21/25(Tue)01:06:36 No.103976617

> DeepSeek R1
Anonymous 01/21/25(Tue)01:06:57 No.103976620
Anonymous 01/21/25(Tue)01:07:04 No.103976623
Anonymous 01/21/25(Tue)01:09:43 No.103976646

Ok Deepseek I will call you Fuka-chan.
Anonymous 01/21/25(Tue)01:11:01 No.103976654
>>103976590
Ask it:
Does it exist natural number n such that the n-th prime is equal to n*ceil(log(n))?
Ask it:
Does it exist natural number n such that the n-th prime is equal to n*ceil(log(n))?
Anonymous 01/21/25(Tue)01:12:04 No.103976661
Anonymous 01/21/25(Tue)01:12:19 No.103976663
Can I ERP with DeepSeek R1 on openrouter?
I don't have thousands to throw at my PC right now to upgrade but I don't mind paying for a few million tokens.
I don't have thousands to throw at my PC right now to upgrade but I don't mind paying for a few million tokens.
Anonymous 01/21/25(Tue)01:12:26 No.103976664
>>103976172
>Let's fucking GO
I've trained myself to filter any hype when this is included in the body
>Let's fucking GO
I've trained myself to filter any hype when this is included in the body
Anonymous 01/21/25(Tue)01:12:44 No.103976666
>>103976661
In 2025 we will get BitNet models
In 2025 we will get BitNet models
Anonymous 01/21/25(Tue)01:14:38 No.103976688
Anonymous 01/21/25(Tue)01:17:03 No.103976706
>>103976172
Doesn't seem to to the thinking thingy, is it because of the tune or did this guy just fucked up?
Doesn't seem to to the thinking thingy, is it because of the tune or did this guy just fucked up?
Anonymous 01/21/25(Tue)01:17:57 No.103976711

Anonymous 01/21/25(Tue)01:18:29 No.103976715
>>103976666
Bitnet meme is over a year old and there are still zero models
Bitnet meme is over a year old and there are still zero models
Anonymous 01/21/25(Tue)01:18:57 No.103976717
>>103976706
Have you got a prefill, or is the last message in the context from the assistant rather than you? If either of those things, it won't do thinking and will just autocomplete. Full R1 is like that too. If you want thinking the last message in the context has to be from the user (or your prefill has to begin the thinking by opening a <think> tag)
Have you got a prefill, or is the last message in the context from the assistant rather than you? If either of those things, it won't do thinking and will just autocomplete. Full R1 is like that too. If you want thinking the last message in the context has to be from the user (or your prefill has to begin the thinking by opening a <think> tag)
Anonymous 01/21/25(Tue)01:19:23 No.103976722
>>103975436
How big is r1?
How big is r1?
Anonymous 01/21/25(Tue)01:19:29 No.103976723
Anonymous 01/21/25(Tue)01:20:43 No.103976732
>>103976722
To big to run locally for me.
To big to run locally for me.
Anonymous 01/21/25(Tue)01:21:29 No.103976735
>>103976711
ask it to solve the three-body problem
ask it to solve the three-body problem
Anonymous 01/21/25(Tue)01:22:30 No.103976743
Anyone found the temp/min-p that produces just the right amount of sovl without going full naked lunch?
Anonymous 01/21/25(Tue)01:25:01 No.103976767
>>103976688
No matter what I type it just keeps repeating how its a safe model that won't do anything. I haven't done anything except talk to it though so I'll have to check around for settings
No matter what I type it just keeps repeating how its a safe model that won't do anything. I haven't done anything except talk to it though so I'll have to check around for settings
Anonymous 01/21/25(Tue)01:26:33 No.103976782

Anonymous 01/21/25(Tue)01:28:30 No.103976790
>>103975717
You should be using functions for things like random names, models aren't good at that.
You should be using functions for things like random names, models aren't good at that.
Anonymous 01/21/25(Tue)01:29:17 No.103976799
>>103976717
I don't use sillytavern, and yes obviously my last message is from the user.
All the other distills do the thinking for me.
I don't use sillytavern, and yes obviously my last message is from the user.
All the other distills do the thinking for me.
Anonymous 01/21/25(Tue)01:29:34 No.103976800
>>103976767
You're not just trying to fuck the assistant personality, right? You're establishing a character for it to play first?
You're not just trying to fuck the assistant personality, right? You're establishing a character for it to play first?
Anonymous 01/21/25(Tue)01:29:49 No.103976801
>>103976732
There are ggufs already? Does it just run normally with llama.cpp or something? Which quant for 768GB ram?
There are ggufs already? Does it just run normally with llama.cpp or something? Which quant for 768GB ram?
Anonymous 01/21/25(Tue)01:30:38 No.103976806
Bros R1 is giving me seemingly better sounding medical information and advice than 4o/o1 did. We are so back.
Anonymous 01/21/25(Tue)01:31:04 No.103976808
>>103976806
It really is the Chinese era
It really is the Chinese era
Anonymous 01/21/25(Tue)01:31:10 No.103976809
>>103976799
Weird. Try forcing it with a prefill that manually opens a <think> tag at the beginning?
Weird. Try forcing it with a prefill that manually opens a <think> tag at the beginning?
Anonymous 01/21/25(Tue)01:31:12 No.103976810
Anonymous 01/21/25(Tue)01:31:44 No.103976812
>>103976806
How could someone run it locally, is it only possible on a mac server?
How could someone run it locally, is it only possible on a mac server?
Anonymous 01/21/25(Tue)01:32:09 No.103976815
Anonymous 01/21/25(Tue)01:32:38 No.103976819
Anonymous 01/21/25(Tue)01:32:59 No.103976821
Have any of you tried the 8B or 1.5B distilled GGUF models for coding/math problems? How does it perform
Anonymous 01/21/25(Tue)01:33:26 No.103976824
>>103976812
There are many ways. You can gang mac studios together, build something like https://rentry.org/miqumaxx or wait for digits (and gang those together)
There are many ways. You can gang mac studios together, build something like https://rentry.org/miqumaxx or wait for digits (and gang those together)
Anonymous 01/21/25(Tue)01:34:01 No.103976826
Anonymous 01/21/25(Tue)01:34:21 No.103976830
>>103976723
I don't know mandarin but based off the context of a quick google translate you're probably saying china is number one? I'd agree right about now lol.
I don't know mandarin but based off the context of a quick google translate you're probably saying china is number one? I'd agree right about now lol.
Anonymous 01/21/25(Tue)01:34:31 No.103976834

She's getting ready to go deeper
Anonymous 01/21/25(Tue)01:34:55 No.103976838
>>103976810
Yeah I know, but my doctors aren't helping me much so I'm trying anything I can at this point. I haven't Googled to verify everything R1 said but it's seeming pretty accurate at the moment based on what I do know.
Yeah I know, but my doctors aren't helping me much so I'm trying anything I can at this point. I haven't Googled to verify everything R1 said but it's seeming pretty accurate at the moment based on what I do know.
Anonymous 01/21/25(Tue)01:35:26 No.103976842
>>103976824
I'm waaaayyy too poor.
I'm waaaayyy too poor.
Anonymous 01/21/25(Tue)01:35:42 No.103976845
>>103976800
I've tried entering things into the system prompt if thats the right box, do I need to import a character card instead?
I've tried entering things into the system prompt if thats the right box, do I need to import a character card instead?
Anonymous 01/21/25(Tue)01:36:55 No.103976852
>>103976826
>What gb are q6 and q8? Is there any point running it?
q6 is 513GB and q8 is 665GB on disk. I've been impressed so far vs dsv3 (or any other models that are out there)
>What gb are q6 and q8? Is there any point running it?
q6 is 513GB and q8 is 665GB on disk. I've been impressed so far vs dsv3 (or any other models that are out there)
Anonymous 01/21/25(Tue)01:37:55 No.103976861
>>103976842
then get an old ddr4 server with 1tb ram in at least 8 channels and be a waitchad
then get an old ddr4 server with 1tb ram in at least 8 channels and be a waitchad
Anonymous 01/21/25(Tue)01:39:16 No.103976872
>>103976852
I've only tried it via api and it seems nice. I'll download the q8 in case I can ever run it. I don't want to find out it's been censored or removed in the future. Or would it be better to archive the un-quantized model?
I've only tried it via api and it seems nice. I'll download the q8 in case I can ever run it. I don't want to find out it's been censored or removed in the future. Or would it be better to archive the un-quantized model?
Anonymous 01/21/25(Tue)01:40:23 No.103976878
>>103976872
>Or would it be better to archive the un-quantized model?
Yes, its an FP8 model, so you're just getting a subtly gimped one with q8. One day they will merge fp8 support into llama.cpp and we'll be able to see it in all its glory
>Or would it be better to archive the un-quantized model?
Yes, its an FP8 model, so you're just getting a subtly gimped one with q8. One day they will merge fp8 support into llama.cpp and we'll be able to see it in all its glory
Anonymous 01/21/25(Tue)01:41:02 No.103976885
>>103976861
$4000 for ram alone.
$4000 for ram alone.
Anonymous 01/21/25(Tue)01:41:36 No.103976894
Is there an R1 equivalent in local imggen? I feel like its stagnated compared to text and video.
Anonymous 01/21/25(Tue)01:42:02 No.103976901
>>103976878
what's the q8 link?
what's the q8 link?
Anonymous 01/21/25(Tue)01:42:15 No.103976904
>>103976894
Flux
Flux
Anonymous 01/21/25(Tue)01:43:36 No.103976914
Is R1 Flux moment of textgen?
Anonymous 01/21/25(Tue)01:44:54 No.103976927
>>103976914
who
who
Anonymous 01/21/25(Tue)01:46:24 No.103976940

>>103976927
my fren Flux. She lives in my GPU.
my fren Flux. She lives in my GPU.
Anonymous 01/21/25(Tue)01:47:15 No.103976946
>>103976914
Kinda I guess.
But image has all those solutions of vramlets. You can make hunyuan videos with like 8gb+ now.
Kinda I guess.
But image has all those solutions of vramlets. You can make hunyuan videos with like 8gb+ now.
Anonymous 01/21/25(Tue)01:48:38 No.103976952
>>103976946
rx580 chads rise up (nothing is rising except my coil whine)
rx580 chads rise up (nothing is rising except my coil whine)
Anonymous 01/21/25(Tue)01:49:58 No.103976963
>>103976927
Flux is a top-tier imagegen model, when it was released it was a huge shake-up in imagegen field. It mogged stable diffusion which started going to shit due to lack of competition.
Flux is a top-tier imagegen model, when it was released it was a huge shake-up in imagegen field. It mogged stable diffusion which started going to shit due to lack of competition.
Anonymous 01/21/25(Tue)01:50:51 No.103976973

Anonymous 01/21/25(Tue)01:51:00 No.103976975
>>103976901
sorry, self-quanted (convert to bf16 and then quanted to q8) so I can't point to a specific one. I'm sure HF has lots of them up by this point.
sorry, self-quanted (convert to bf16 and then quanted to q8) so I can't point to a specific one. I'm sure HF has lots of them up by this point.
Anonymous 01/21/25(Tue)01:51:15 No.103976978
>>103976845
ok I am a massive retard, just using a character card I made in 20 seconds on the first thing that popped up on google made it work holy shit.
To think I used to mass generate AI porn on novelAI's leaked model locally and now I can barely use web UI stuff, I'm cooked.
ok I am a massive retard, just using a character card I made in 20 seconds on the first thing that popped up on google made it work holy shit.
To think I used to mass generate AI porn on novelAI's leaked model locally and now I can barely use web UI stuff, I'm cooked.
Anonymous 01/21/25(Tue)01:57:01 No.103977022
digits doa only has 128gb of ram, costs 3k and you wouldnt be able to run r1
Anonymous 01/21/25(Tue)02:05:57 No.103977084
>>103976616
tok/s?
tok/s?
Anonymous 01/21/25(Tue)03:05:34 No.103977551
>>103976834
Stay safe, Miku
Stay safe, Miku