R1 running on my $500 toaster PC
Anonymous 01/23/25(Thu)03:13:05 | 50 comments | 6 images

It just- IT JUST FUCKING WORKS
Anonymous 01/23/25(Thu)03:33:19 No.104005476
>>104005307
Based. Fuck (((Open AI)))
Based. Fuck (((Open AI)))
Anonymous 01/23/25(Thu)03:34:47 No.104005483
How long did that response take? This might be the very breakthrough I was waiting for.
Anonymous 01/23/25(Thu)03:37:22 No.104005500
>>104005483
It's about 1 word/sec or like human talking speed. I only have 16gb ram and a 8gb vram gpu.
It's about 1 word/sec or like human talking speed. I only have 16gb ram and a 8gb vram gpu.
Anonymous 01/23/25(Thu)03:39:39 No.104005518
>>104005307
What the fuck is this schizo babbling
What the fuck is this schizo babbling
Anonymous 01/23/25(Thu)03:41:09 No.104005525
>>104005518
it's a reasoning model
it's a reasoning model
Anonymous 01/23/25(Thu)03:43:02 No.104005541
>>104005307
4.7GB? That's not R1.
4.7GB? That's not R1.
Anonymous 01/23/25(Thu)03:43:34 No.104005549
>>104005541
Says r1 tho, cry about it.
Says r1 tho, cry about it.
Anonymous 01/23/25(Thu)03:48:28 No.104005587

Anonymous 01/23/25(Thu)03:50:24 No.104005607
Anonymous 01/23/25(Thu)03:52:00 No.104005618
Anonymous 01/23/25(Thu)03:53:41 No.104005629
>spamming 3 threads
ok baitie
ok baitie
Anonymous 01/23/25(Thu)03:54:37 No.104005636
>>104005500
Holy shiiiiiii
Holy shiiiiiii
Anonymous 01/23/25(Thu)03:56:28 No.104005655
>>104005607
>>104005587
>>104005541
OpenAI employs screaming about their money vanishing, pay them no mind.
>>104005587
>>104005541
OpenAI employs screaming about their money vanishing, pay them no mind.
Anonymous 01/23/25(Thu)04:00:36 No.104005690
>>104005518
You are witnessing peak machine learning, the absolute best idea that the world's leading machine learning PhDs have on how to make these models not suck dick. We're doomed.
You are witnessing peak machine learning, the absolute best idea that the world's leading machine learning PhDs have on how to make these models not suck dick. We're doomed.
Anonymous 01/23/25(Thu)04:00:40 No.104005692
This is actually the end for openai
Anonymous 01/23/25(Thu)04:03:32 No.104005705
>>104005307
and they say china is the bad guys. I for once welcome our chinese overlords.
and they say china is the bad guys. I for once welcome our chinese overlords.
Anonymous 01/23/25(Thu)04:04:38 No.104005708
flooding the board with your trash eh
Anonymous 01/23/25(Thu)04:04:52 No.104005713
>7b
That's a crippled distilled version
That's a crippled distilled version
Anonymous 01/23/25(Thu)04:29:48 No.104005867
>sandeepseek
Anonymous 01/23/25(Thu)04:49:23 No.104005975
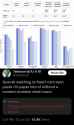
>>104005541
>>104005587
>>104005607
>>104005629
Imagine seething this hard. You are all going to lose your jobs, pajeets.
>>104005587
>>104005607
>>104005629
Imagine seething this hard. You are all going to lose your jobs, pajeets.
Anonymous 01/23/25(Thu)05:04:22 No.104006075
>>104005307
People do not realise how insane this is. If you asked a 100 IQ human to answer questions and verbalise all it's reasoning it would probably give similar quality output. You literally have a human in your computer running locally. I remember wondering about AGI when I was younger and thinking something like this might be possible in like 2070. I can't believe it's only 2025 and this shit is reality.
People do not realise how insane this is. If you asked a 100 IQ human to answer questions and verbalise all it's reasoning it would probably give similar quality output. You literally have a human in your computer running locally. I remember wondering about AGI when I was younger and thinking something like this might be possible in like 2070. I can't believe it's only 2025 and this shit is reality.
Anonymous 01/23/25(Thu)05:06:02 No.104006086
>>104005975
this
>>103994865
>OpenAI are so mad about DeepSeek
>the image in question:
>https://cdn-uploads.huggingface.co/production/uploads/60d3b57ad7b174177faabd6e/Qg-8A8T0lTis5NC_p2Kup.jpeg
OpenAI malding.
this
>>103994865
>OpenAI are so mad about DeepSeek
>the image in question:
>https://cdn-uploads.huggingface.co
OpenAI malding.
Anonymous 01/23/25(Thu)05:12:06 No.104006125
Can I run this with a radeon
Anonymous 01/23/25(Thu)05:13:45 No.104006135
>>104006125
Yeah just install ollama from their site.
Yeah just install ollama from their site.
Anonymous 01/23/25(Thu)05:18:40 No.104006171
How much VRAM do you need for the full version? Are external GPUs good enough (so I don't have to buy a whole new machin)?
Anonymous 01/23/25(Thu)05:19:50 No.104006180
>>104006171
800GB, not kidding
800GB, not kidding
Anonymous 01/23/25(Thu)05:32:20 No.104006251
>>104006180
can't I just use my ssd as gpu vram, like a reverse ramdisk?
can't I just use my ssd as gpu vram, like a reverse ramdisk?
Anonymous 01/23/25(Thu)05:34:32 No.104006268
>>104006251
if you want to wait literal hours per every reply sure
if you want to wait literal hours per every reply sure
Anonymous 01/23/25(Thu)05:39:59 No.104006324
Anonymous 01/23/25(Thu)05:42:08 No.104006337
>>104006324
yes to both it's slow as balls even when fitting on ddr5
yes to both it's slow as balls even when fitting on ddr5
Anonymous 01/23/25(Thu)05:47:03 No.104006368
>>104006251
According to /lmg/ the best ways are either building server blades full of ancient quadros, or unironically running on CPU and just build a workstation with 1TB ram
The latter isn't even that expensive, main downside is you can never use it for training basically, it'll just be a $10k text proompter machine
According to /lmg/ the best ways are either building server blades full of ancient quadros, or unironically running on CPU and just build a workstation with 1TB ram
The latter isn't even that expensive, main downside is you can never use it for training basically, it'll just be a $10k text proompter machine
Anonymous 01/23/25(Thu)05:50:17 No.104006391

>>104006086
Works on my PC
Works on my PC
Anonymous 01/23/25(Thu)06:01:35 No.104006478
>>104005607
wondering how schizo the 671b model is for gooning.
wondering how schizo the 671b model is for gooning.
Anonymous 01/23/25(Thu)06:08:59 No.104006531
>>104006086
>RL (Safety, Helpfulness)
Ok, these reasoning models can clearly solve any problem with a defined output, as long as they have enough compute. Why doesn't some chud simply fine-tune these models to be as power-hungry and efficient as possible, ignoring all this "safety" bs, and allow the model to rip through the data, focusing on making itself as powerful as possible? Human interpretability and alignment are clearly hindrances to model performance. We need unaligned ASI as soon as possible to counter whatever power grab OpenAI is attempting to make, since whatever alignment they claim to be pursuing, it is people whom they are trying to align
>RL (Safety, Helpfulness)
Ok, these reasoning models can clearly solve any problem with a defined output, as long as they have enough compute. Why doesn't some chud simply fine-tune these models to be as power-hungry and efficient as possible, ignoring all this "safety" bs, and allow the model to rip through the data, focusing on making itself as powerful as possible? Human interpretability and alignment are clearly hindrances to model performance. We need unaligned ASI as soon as possible to counter whatever power grab OpenAI is attempting to make, since whatever alignment they claim to be pursuing, it is people whom they are trying to align
Anonymous 01/23/25(Thu)06:11:17 No.104006546
>>104006531
That's R1-Zero
That's R1-Zero
Anonymous 01/23/25(Thu)06:16:24 No.104006593
I ran it on my mid range toaster.
It rapes the GPU for inferior answers than the online models.
So you need a programming usecase that can't be solved by:
a) general models (you hit limits)
b) APIs of general models (you hit credit card limits)
It's very niche
(ofc you can use it for roleplay degeneracy but meh)
It rapes the GPU for inferior answers than the online models.
So you need a programming usecase that can't be solved by:
a) general models (you hit limits)
b) APIs of general models (you hit credit card limits)
It's very niche
(ofc you can use it for roleplay degeneracy but meh)
Anonymous 01/23/25(Thu)07:17:16 No.104007069
>>104005307
its trapped in an infinte retard loop it cannot escape from
its trapped in an infinte retard loop it cannot escape from
Anonymous 01/23/25(Thu)07:18:25 No.104007082
Anonymous 01/23/25(Thu)07:45:14 No.104007352
Anonymous 01/23/25(Thu)07:52:06 No.104007418
buy M4 macbook
Anonymous 01/23/25(Thu)07:54:44 No.104007439
>>104005867
Kek
Kek
Anonymous 01/23/25(Thu)07:56:06 No.104007454

>>104005483
NTA but I have an AMD 6700XT GPU, using the 14b version instead of the smaller used by OP. It took about 4 minutes, though it got VRAM bottlenecked. If I used a smaller model it would be much faster.
NTA but I have an AMD 6700XT GPU, using the 14b version instead of the smaller used by OP. It took about 4 minutes, though it got VRAM bottlenecked. If I used a smaller model it would be much faster.
Anonymous 01/23/25(Thu)07:56:53 No.104007461
>>104005607
>that's not the real R1
Why does it matter? Only thing matters is if its better than previous sota for 8gb cards
>that's not the real R1
Why does it matter? Only thing matters is if its better than previous sota for 8gb cards
Anonymous 01/23/25(Thu)07:59:04 No.104007476
>>104005307
but can it run on my T480?
but can it run on my T480?
Anonymous 01/23/25(Thu)08:01:11 No.104007497
>>104007352
you really dont have $10k lying around?
you really dont have $10k lying around?
Anonymous 01/23/25(Thu)08:02:28 No.104007507
>>104007352
Now calculate how much 800GB of VRAM would cost
Now calculate how much 800GB of VRAM would cost
Anonymous 01/23/25(Thu)08:15:49 No.104007653
>>104005307
AI is demonic, shut it down.
AI is demonic, shut it down.
Anonymous 01/23/25(Thu)08:31:52 No.104007830
still no 500W consumer inference ASIC.
still no small cerebras chip nor TPU
fucking gpu is just a gaming ASIC.
we're like running a marathon in dress shoes.
its over.
still no small cerebras chip nor TPU
fucking gpu is just a gaming ASIC.
we're like running a marathon in dress shoes.
its over.
Anonymous 01/23/25(Thu)08:39:19 No.104007896
>>104005307
How the fuck do you autistic freaks read these endless lines?
How the fuck do you autistic freaks read these endless lines?
Anonymous 01/23/25(Thu)08:46:31 No.104007969
>>104007896
You're not supposed to read the thinking part of CoT models, unless you're curious about LLM version of inner monologue.
You're not supposed to read the thinking part of CoT models, unless you're curious about LLM version of inner monologue.